

有大量可用于Python的HTTP客户端–在Github上快速搜索Python HTTP客户端会得到1700多个结果。但是,你如何理解所有这些客户端,并找到一个适合你特定使用需求的呢?
你是有一台机器可供支配,还是有一批机器?你是想保持简单,还是更关心原始性能?一个网络应用程序,应该偶尔向一个微服务API发出请求,这与一个不断抓取数据的脚本有很大的不同要求。此外,还有一个问题是,你选择的库在六个月后是否仍然存在。
在这篇文章中,我们将介绍目前可用于Python的五个最好的HTTP客户端,并详细说明为什么它们中的每一个都可能是你要考虑的一个。
简 介
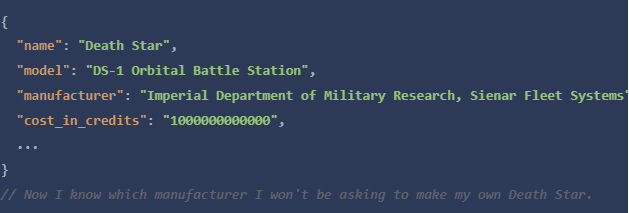
在这里的所有例子中,我将向《星球大战》API(swapi.dev)发出GET请求,该API返回有关《星球大战》宇宙中的人物、行星和数据。你可以看到下面一个JSON响应的例子。
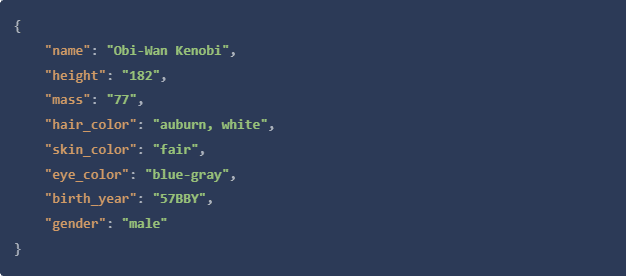
这里的POST请求例子是到httpbin.org,这是一个开发者测试工具,响应请求的内容,如果你愿意,你也可以使用requestbin.com。我们将发送以下关于欧比旺的JSON POST数据。
基础知识
如果你熟悉 Python 的标准库,你可能已经知道其中 urllib 和 urllib2 模块的混乱历史。urllib2 (最初的模块) 在 Python 3 中被分割成独立的模块,urllib.request和urllib.error。
为了与本文其余部分的包进行比较,让我们先看看我们如何只用标准库来做一个请求。
我们下面的所有例子都使用Python 3
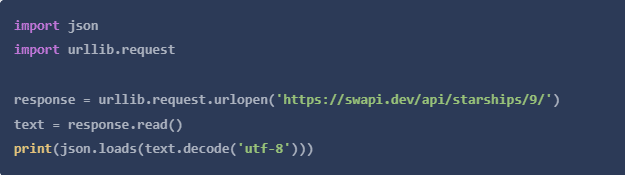
请注意,我们必须使用JSON模块将其转换为JSON,因为read()返回一个字符串。
我们的POST将看起来像这样。
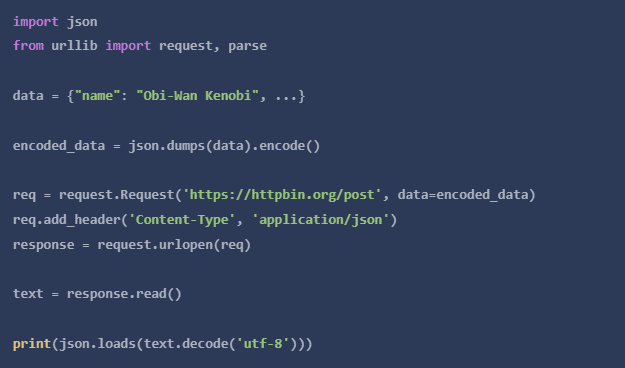
我们还必须对我们要发送的数据进行编码,并设置头的内容类型,如果我们要提交表单数据,我们就需要更新头的内容。
你可能觉得这很笨重–“我只想得到一些数据!”。嗯,这似乎也是许多其他开发者的感受,因为有许多HTTP客户端可以作为额外的包。在文章的其余部分,我们将看一下几个好的选择。
最佳Python HTTP客户端
1.urllib3
urllib3 是一个功能强大、用户友好的 Python HTTP 客户端。许多Python生态系统已经在使用urllib3,你也应该这样做。urllib3带来了许多Python标准库中缺少的关键功能。
urllib3包,相当令人困惑的是,它不是标准库的一部分,而是一个独立的HTTP客户端包,它建立在urllib之上。它提供了缺失的功能,如连接池、TLS验证和线程安全。这最终导致了像网络爬取这样的多次调用的应用程序有更好的性能,因为它们将重复使用与主机的连接而不是创建新的连接。
urllibs3实际上是本文后面提到的HTTP客户端的一个依赖项,每月有超过1.5亿的下载量。为了使用 urllib3 进行请求,我们要用它进行如下调用。

与标准库一样,我们不得不自己将其转换为JSON,因为urllib3让我们不得不手动操作。
对于POST请求,我们还需要对查询参数或JSON字段进行手动编码。

urllib3.PoolManager()为我们提供了一个池管理器对象,处理连接池和线程安全。随后的请求是通过管理器实例的request()方法进行的,并向它提供 HTTP 方法和所需的 URL。对特定主机名的连接在后台被缓存/维护,并在适用时被重新使用。出于这个原因,我们也要确保在配置PoolManager()时,要有正确数量的主机名来连接。
urllib3 还提供了复杂的重试行为。这是一个非常重要的考虑–我们不希望我们的连接由于随机的一次性过载服务器而超时,然后就放弃了。我们希望在我们认为数据不可用之前尝试多次。你可以在urllib3 文档中找到关于这个主题的更多细节。
使用 urllib3 的连接池的缺点是,由于它不是一个有状态的客户端,所以很难处理 cookie。我们必须在请求中手动设置这些头值,而不是由 urllib3 直接支持,或者使用类似http.cookies模块的东西来为我们管理它们。比如说。

鉴于许多其他库都依赖于 urllib3,它很可能会在未来一段时间内存在。
2.Requests
Requests是一个优雅而简单的Python HTTP库,为人类而建。
Requests包在Python社区中备受青睐,根据PePy的数据,每月获得超过1.1亿的下载量。它也被主urllib.request文档推荐为 “更高级别的HTTP客户端接口”。
使用Requests是非常简单的,因此,Python社区的大多数开发者都把它作为他们的HTTP客户端的选择。它由Python软件基金会维护,在Github上有超过45000颗星,是许多其他Python库的依赖,如gRPC和pandas。
让我们回顾一下我们是如何用提出请求的。

同样,发布数据也变得简单了–我们只需要把我们的get方法调用改为post()。

在这里你可以看到为什么request如此受欢迎–它的设计实在是太优雅了!这里的例子是迄今为止给出的所有例子中最简洁和需要最少代码的。
请求结合了HTTP动词作为方法(GET、POST),我们甚至能够直接转换为JSON,而不需要编写我们自己的解码方法。作为一个开发者,这意味着它非常容易操作和理解,只需要两个方法调用就可以从我们的API获得我们想要的数据。在我们的POST例子中,我们也不需要为我们的数据字典编码而烦恼,也不需要担心在请求头中设置正确的内容类型。
修改我们的POST调用以提交表单数据也很容易,只需将我们的json参数替换为数据即可。
它的另一个简单的例子是我们可以设置cookies,这只是post方法的一个附加参数。比如说。
r = requests.post('https://httpbin.org/post', data=data, cookies={'foo': 'bar', 'hello': 'world'}))请求还提供了一大批其他高级功能,如会话、请求钩子和自定义重试策略。会话允许在不同的请求中保持cookie的状态性,这是urllib3没有提供的东西。
一个来自Requests文档的会话例子。

在这里,我们初始化了一个会话对象,用它来发送两个GET请求。我们从服务器收到的任何cookie都由会话对象管理,并在随后的请求中自动发回给服务器。
此外,钩子允许你注册你想在每次调用后执行的共同行为。如果你使用git,你可能对这个概念很熟悉,它允许你做同样的事情。你可以在Requests的文档中查看所有的高级功能。
鉴于所有要求的先进功能意味着它是各种应用的可靠选择。
3.aiohttp
用于asyncio和Python的异步HTTP客户端/服务器。
aiohttp是一个包含客户端和服务器框架的包,这意味着它可能很适合在其他地方发出请求的 API。它在 Github 上有 11000 颗星,并且有许多第三方库建立在它之上。用aiohttp运行我们通常的《星球大战》请求将是:

我们的POST请求:

你可以看到aiohttp.ClientSession()对象使用了与Requests 相似的语法,但整体代码比之前的例子要复杂得多,我们现在有了使用async和await的方法调用,还有一个额外的asyncio 模块导入。aiohttp 文档给出了一个很好的概述,说明为什么这些额外的代码与Requests 相比是必要的。
如果你不熟悉异步编程的概念,将需要一些时间来理解,但它最终意味着有可能在同一时间发出一些请求,而不需要等待每个请求陆续返回响应。对于我们只做一个请求的情况,这可能不是一个问题,但如果我们需要做几十个甚至几千个请求,CPU等待响应的所有时间可以更好地用于做其他事情(比如做另一个请求!)。我们不希望在等待的时候为CPU周期付费。作为一个例子,让我们看一下一些代码,从《星球大战》的API中查找前50艘星际飞船的数据。
import aiohttp
import asyncio
import time
async def get_starship(ship_id: int):
async with aiohttp.ClientSession() as session:
async with session.get(f'https://swapi.dev/api/starships/{ship_id}/') as response:
print(await response.json())
async def main():
tasks = []
for ship_id in range(1, 50):
tasks.append(get_starship(ship_id))
await asyncio.gather(*tasks)
asyncio.run(main())我们首先使用asyncio的run()方法来运行我们的main()异步函数,在这里我们使用for-loop来运行我们的50个请求。通常情况下,这意味着我们一个接一个地运行这50个请求,等待一个请求完成后再开始下一个。然而,在asyncio和aiohttp 中,我们有 “异步 “函数,可以异步运行并立即返回一个 Future 值。我们将这些值存储在我们的任务列表中,并最终用gather()来等待所有的任务完成。
在我的机器上,这一直需要不到2秒的时间,而使用Requests的会话请求同样的数据只需要超过4秒。因此,如果我们能够处理好它给我们的代码带来的额外复杂性,我们就能够加快检索数据的时间。
aiohttp提供了详尽的文档和大量的高级功能,比如会话、cookies、池、DNS 缓存和客户端跟踪。然而,它仍然缺乏的一个领域是对复杂重试行为的支持,这只能通过第三方模块获得。
4. GRequests
GRequests将Gevent–一个 “基于coroutine的Python网络库”–引入Requests,以允许请求异步进行。这是一个较早的库,首次发布于2012年,不使用Python的标准asyncio模块。我们可以像使用Requests那样提出单个请求,但我们也可以利用Gevent模块来提出一些请求,就像这样。

GRequests的文档有点稀少,甚至在其Github页面上推荐了其他库而不是它。它只有165行代码,并没有提供比Request本身更高级的功能。在九年的时间里,它总共有六个版本,所以可能只有在你觉得异步编程特别混乱的时候才真正值得考虑。
5.HTTPX
HTTPX提供了一个 “广泛兼容的请求的API”,是我们名单中唯一提供HTTP 2.0支持的库,并且还提供了异步API。
使用HTTPX与Requests非常相似。

并用于我们的POST请求。

我们只是简单地改变了我们的模块的名称,仍然不需要管理任何JSON转换。在我们的例子中,我们使用了同步方法,但也可以选择异步版本,只需使用httpx.AsyncClient。这里,代码与我们之前的AIOHTTP的例子很相似。

对于需要一定时间才能返回响应的请求,这又意味着我们的客户端不必再等待。如果你有大量的请求需要同时进行,并希望节省CPU周期,这绝对是值得考虑的。如果你也想把基于请求的脚本重构为异步的东西,那么HTTPX似乎是一个很好的替代。
6. Uplink
Uplink是我们这里列表中最近的一个库,与我们其他的库相比,它遵循的方法略有不同,因为它主要不是关注任意的HTTP请求,而是关注典型的REST结构的请求流,有路径模式(路由)和REST参数。
默认情况下,Uplink使用我们著名的Requests库来组装实际的HTTP请求,然而它也支持iohttp和Twisted,如果你喜欢异步请求的调用。从这个意义上说,它本身并不是一个合适的HTTP客户端,而更像是现有HTTP客户端的一个方便的包装器。
为了再次实现我们最基本的例子

我们在这里所做的是
- 创建一个
SWAPI类,基于Uplink的基础消费者类。 - 添加一个假的方法
get_starship,并用@get来注解它,以指定所需的REST路径和参数。我们的父类将在运行时提供实现。 - 实例化
SWAPI并传递我们的base_url。 - 调用我们的
get_starship方法,并传递船舶ID。 - 接收就绪的响应,并简单地使用
json()将其转换为一个适当的JSON对象。
瞧,我们有了一个轻量级的Python类,有了一个命名恰当的方法,可以发送我们的请求,而不需要处理实际的HTTP细节。
这与我们的POST例子类似,我们指定一个@post装饰器来表示POST请求并定义路径/路线。此外,我们使用@json decorator表示我们的数据参数应该被用作HTTP请求的JSON主体。

[文中代码源自Scrapingbee]
差不多就是这样了,只用了几行代码,我们就成功地创建了一个类,它允许我们以本地Python的方式访问REST接口,而不需要自己处理HTTP。
特点比较
当然,我们列表中的所有库都具有相同的基本功能,即组成和发送HTTP请求。在这方面,它们都很相似,而且确实支持同样的基本功能(即支持SSL和代理)。
它们的不同之处在于Python和HTTP的更多高级领域,例如对异步请求调用的支持、跨请求会话支持和现代HTTP版本。特别是后者(到目前为止)是HTTPX独有的,它是我们列表中唯一支持HTTP/2的Python库。
| 客户端 | 每月下载量 | Github | 异步 | 会议 | 代理支持 | SSL | HTTP 2 | 最新发布 |
|---|---|---|---|---|---|---|---|---|
| aiohttp | 58M | 12.4k | ✔️ | ✔️ | ✔️ | ✔️ | – | 2021 |
| GRequests | 288k | 4k | ✔️ | ✔️ | ✔️ | ✔️ | – | 2020 |
| HTTPX | 9M | 8.8k | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | 2022 |
| Requests | 214M | 47.5k | – | ✔️ | ✔️ | ✔️ | – | 2022 |
| Uplink | 377k | 900 | – | – | ✔️ | ✔️ | – | 2022 |
| urllib | 不适用 | 不适用 | – | – | ✔️ | ✔️ | – | 不适用 |
| urllib3 | 226M | 3k | – | – | ✔️ | ✔️ | – | 2022 |
* 发布日期、下载数字(基于PePy)和Github星级是截至2022年6月。
下载量和Github星级,当然,必须用一粒盐来衡量,但它们仍然可以作为一个库有多受欢迎以及你可以期待什么样的社区支持的指标,在这里,Requests是明显的赢家(虽然urllib3的下载次数更多,但请记住我们之前的说明,它是Requests的一个依赖)。
总 结
我们在本文中看到,Requests启发了许多所示库的设计。它在Python社区中非常流行,是大多数开发者的默认选择。由于它提供了额外的功能,如会话和简单的重试行为,如果你有简单的需求或想维护简单的代码,你可能应该关注它。
如果你的要求稍微复杂一些–特别是如果你需要处理并发的请求–你可能想看看 aiohttp。在我们的测试中,它显示了异步网络请求的最佳性能,它在异步库中具有最高的知名度,并且得到了积极的支持。然而,HTTPX 是一个接近的竞争者,它确实支持 aiohttp 仍然缺乏的一些功能,特别是 HTTP/2。
另一方面,Uplink提供了一个非常优雅和轻量级的抽象层,但它可能不是你进行通用网络爬取的首选,相反,如果你需要访问定义明确的REST接口,它将主要发挥其作用。

