

研究估计,超过40%的互联网流量来自于机器人,因此对能够区分人类活动和机器人活动的软件的需求一直在上升。这方面的一个典型例子是Cloudflare的机器人管理解决方案。
如果你点击了这篇文章,你可能想了解如何绕过Cloudflare。你来对地方了! 在本指南中,我们将介绍:
- 什么是Cloudflare机器人管理
- Cloudflare如何检测机器人
- 如何逆向工程和绕过Cloudflare
准备好了吗?让我们开始吧!
什么是Cloudflare机器人管理
Cloudflare是一家网络性能和安全公司。在安全方面,他们为客户提供网络应用防火墙(WAF)。WAF可以保护应用程序免受若干安全威胁,如跨站脚本(XSS)、凭证填充和DDoS攻击。
他们的WAF中包含的核心系统之一是Cloudflare的Bot Manager。作为一个机器人保护解决方案,它的主要目标是减轻来自恶意机器人的攻击,而不影响真正的用户。
Cloudflare承认某些机器人的重要性。例如,没有网站希望故意阻止谷歌或其他搜索引擎抓取其网页。为了说明这一点,Cloudflare为已知的好机器人维护了一个允许列表。
不幸的是,对于像你和我这样的网络搜索爱好者来说,他们还认为所有未列入白名单的机器人流量都是恶意的。因此,无论你的意图如何,你的机器人很有可能被拒绝访问Cloudflare保护的网页。
如果你以前曾试图搜刮一个受Cloudflare保护的网站,你可能遇到过以下几个与Bot-manager有关的错误。
- 错误1020:拒绝访问
- 错误1010:该网站的所有者根据你的浏览器签名禁止你访问。
- 错误1015:您被限制了速率
- 错误1012:访问被拒绝
这通常伴随着403 ForbiddenHTTP响应状态代码。
Cloudflare能否被绕过?
幸好,答案是肯定的! 但是,开发Cloudflare旁路并不是一个简单的壮举,要靠自己去做。首先,你需要对它的工作原理有一个坚实的了解。
Cloudflare是如何检测机器人的?
Cloudflare使用的机器人检测方法一般可分为两类:被动和主动。被动机器人检测技术包括在后端进行的指纹检查,而主动检测技术则依赖于在客户端进行的检查。让我们一起深入了解每个类别的几个例子吧
Cloudflare被动式机器人检测技术
以下是Cloudflare采用的一些被动机器人检测技术的非详尽清单。
检测机器人网络
Cloudflare维护着一个已知与恶意机器人网络相关的设备、IP地址和行为模式的目录。任何被怀疑属于这些网络的设备都会被自动阻止,或者面临额外的客户端挑战,需要解决。
IP地址信誉
一个用户的IP地址信誉(也称为风险分数或欺诈分数)是基于地理位置、ISP和信誉历史等因素。例如,属于数据中心或已知VPN供应商的IP将比住宅IP地址的声誉更差。一个网站也可以选择限制从他们所服务的区域以外的地区访问网站,因为来自实际客户的流量不应该来自那里。
HTTP请求标头
Cloudflare使用HTTP请求头来确定你是否是一个机器人。如果你有一个非浏览器的用户代理,如python-requests/2.22.0,你的搜刮器可以很容易地被挑出来作为一个机器人。如果你的机器人发送的请求缺少浏览器中的头信息,Cloudflare也可以阻止它。或者,如果你有基于用户代理的不匹配的头文件。例如,包括Firefox用户代理的sec-ch-ua-full-version-list:header。
TLS指纹识别
这项技术使Cloudflare的antibot能够识别被用来向服务器发送请求的客户端。
尽管有多种方法可以对TLS进行指纹识别(如JA3、JARM和CYU),但每一种实现都会产生一个指纹,而这个指纹在每个请求客户端是静态的。TLS指纹是有帮助的,因为一个浏览器的TLS实现往往与其他发布版本、其他浏览器和基于请求的库的实现不同。例如,Windows上的Chrome浏览器(版本104)会有一个与以下所有不同的指纹。
- 一个在Windows上的Chrome浏览器(version 87)。
- 一个火狐浏览器
- 一个安卓设备上的Chrome浏览器
- python的HTTP请求库
TLS指纹的构建发生在TLS Handshake 过程中。Cloudflare分析了“client hello “消息中提供的字段,如密cipher suites, extensions, and elliptic curves,以计算特定客户端的指纹hash。
接下来,该hash在预先收集的指纹数据库中被查找,以确定该请求来自哪个客户端。假设客户端的hash与允许的指纹hash(即浏览器的指纹)相符。在这种情况下,Cloudflare将把来自客户端请求的用户代理头与与存储的指纹哈希相关的用户代理进行比较。
如果它们匹配,安全系统会认为该请求来自一个标准的浏览器。相反,如果一个客户的TLS指纹和它所宣传的用户代理之间不匹配,则表明明显使用了定制的机器人软件,导致请求被阻止。
HTTP/2指纹识别
HTTP/2规范是第二个主要的HTTP协议版本,于2015年5月14日作为RFC 7540发布。截至本文撰写之时(2022年9月),该协议已被所有主要浏览器所支持。
HTTP/2的主要目标是通过引入头域压缩和允许在同一TCP连接上的并发请求和响应来提高网站和网络应用的性能。为了实现这一目标,HTTP/1.1的基础被扩展为新的参数和值。这些新的内部结构是HTTP/2指纹的基础。
二进制框架层是HTTP/2的新成员,是HTTP/2指纹的核心焦点。
如果您对HTTP/2指纹识别的更深入分析感兴趣,您应该在这里阅读Akamai提出的HTTP2客户端指纹识别方法。HTTP/2客户端的被动指纹识别。但现在,这里是一个总结。
三个主要部分构成了HTTP/2的指纹。
- 帧:
settings_header_table_size,settings_enable_push,settings_max_concurrent_streams,settings_initial_window_size,settings_max_frame_size,settings_max_header_list_size,window_update - 流优先级信息:
StreamID:Exclusivity_Bit:Dependant_StreamID:weight - 伪报头字段顺序:The order of the
:method,:authority,:scheme, and:pathheaders.
如果你感到好奇,你可以点击这里测试一个实时的HTTP/2指纹识别演示。
与TLS指纹一样,每个请求客户端都会有一个静态的HTTP/2指纹。为了确定一个请求的合法性,Cloudflare总是验证请求中的指纹和用户代理对是否与存储在其数据库中的白名单相符。
HTTP/2指纹识别和TLS指纹识别是相辅相成的。在Cloudflare使用的所有被动机器人检测技术中,这两种技术是在基于请求的机器人中最难控制的。然而,它们也是最重要的。因此,你要确保你做得对,否则就有可能被封杀
好了!现在,你应该对Cloudflare如何被动地检测机器人有了充分的了解。但是,请记住:这只是故事的一半。现在,让我们来看看他们是如何主动进行检测的
Cloudflare主动式机器人检测技术
当您访问受Cloudflare保护的网站时,许多检查都在客户端(即在您的本地浏览器中)不断运行,以确定您是否是一个机器人。以下是他们使用的一些方法的清单(再次,并非详尽无遗)。
CAPTCHA
在过去,验证码是检测机器人的首选方法。然而,众所周知,它们损害了终端用户的体验。Cloudflare是否向用户提供验证码,取决于几个因素,例如。
- 网站的配置。网站管理员可以选择一直启用验证码,有时启用,或根本不启用。
- 风险等级。Cloudflare可选择仅在流量可疑的情况下提供验证码。例如,如果用户使用Tor客户端浏览网站,可能会显示验证码,但如果用户运行谷歌浏览器等标准网络浏览器,则不会显示。
以前,Cloudflare使用reCAPTCHA作为他们的主要验证码供应商。但是,自2020年以来,他们已经迁移到完全使用hCaptcha。下面是一个出现在Cloudflare保护的网站上的hCaptcha的例子。
Canvas指纹识别
Canvas 指纹技术允许系统识别网络客户端的设备类别。设备类别是指用于访问网页的系统的浏览器、操作系统和图形硬件的组合。
画布是一种HTML5 API,用于使用JavaScript在网页上绘制图形和动画。为了构建画布指纹,网页会查询你的浏览器的画布API,以呈现一个图像。然后对该图像进行哈希处理,以产生一个指纹。
这种技术依赖于将一个系统的图形渲染系统作为一个物理上不可克隆的函数。这听起来可能很复杂,所以让我解释一下。
- 硬件:GPU
- 低级别的软件:GPU驱动,操作系统(字体,抗锯齿/次像素渲染算法)。
- 高级软件:网络浏览器(图像处理引擎)
因为这些类别中的任何一个变化都会产生一个独特的指纹,这种技术可以准确区分设备的类别。
我想澄清一下:Canvas 指纹并不包含足够的信息来充分追踪和识别独特的个人或机器人。相反,它的主要目的是为了准确区分设备类别。
在机器人检测方面,这很有用,因为机器人往往会对其底层技术(通过其用户代理头)撒谎。Cloudflare有一个合法画布指纹+用户代理对的大型数据集。使用机器学习,他们可以通过寻找你的画布指纹和预期指纹之间的不匹配来检测设备属性欺骗(例如,用户代理、操作系统或GPU)。
Cloudflare使用一种特定的画布指纹识别方法,即谷歌的Picasso指纹识别法。
如果你想看看Canvas指纹的操作,请查看Browserleak的实时演示。
事件追踪
Cloudflare将事件监听器添加到网页中。这些监听器监听用户的行动,如鼠标移动、鼠标点击或按下按键。大多数时候,真正的用户需要使用他们的鼠标或键盘来浏览。如果Cloudflare看到持续缺乏鼠标或键盘的使用,他们可以认为用户是一个机器人。
环境API查询
这是一个非常广泛的类别。一个浏览器有数以百计的网络API,可以用来进行机器人检测。我将尽我所能把它们分成4类。
- 浏览器特定的API:这些规范在一个浏览器中存在,但在另一个浏览器中可能不存在。例如,
window.chrome是一个只存在于Chrome浏览器中的属性。如果您发送给Cloudflare的数据表明您使用的是Chrome浏览器,但发送时却使用Firefox用户代理,他们就会知道有问题。 - Timestamp APIs:Cloudflare利用时间戳API,如
Date.now()或window.performance.timing.navigationStart来跟踪用户的速度指标。如果时间戳不像普通人的浏览活动,用户将被阻止。一些例子包括:非人为的快速浏览或不匹配的时间戳(如navigationStart的时间戳来自页面加载之前)。 - 自动的浏览器检测:Cloudflare查询浏览器的属性,这些属性只存在于自动化网络浏览器环境中。例如,
window.document.__selenium_unwrapped或window.callPhantom属性的存在分别表明Selenium和PhantomJS的使用。出于显而易见的原因,如果检测到这一点,你就会被阻止。 - Sandboxing 检测:就我们的目的而言,Sandboxing是指在非浏览器环境中模拟浏览器的尝试。Cloudflare设有检查,以阻止人们试图用模拟的浏览器环境解决其挑战,例如在NodeJS中使用JSDOM。例如,脚本可以寻找
进程对象,这只存在于NodeJS中。他们还可以通过对相关函数使用Function.prototype.toString.call(functionName)来检测函数是否被修改。
Cloudflare机器人保护的核心
与其他许多反机器人一样,Cloudflare将上述所有方法的数据作为传感器数据进行收集,并在服务器端验证其不一致之处。
对,这是一个很大的信息! 您现在应该对Cloudflare使用的机器人检测技术有所了解了。
到目前为止,我们只讨论了高层次的概念,没有过多关于Cloudflare实际脚本的具体细节。但不要担心。在下一节中,我们将看到Cloudflare的反病毒机器人究竟是如何将这些技术付诸实践的;通过分析其核心:Cloudflare的等待室。
Cloudflare等待室
“检查网站连接是否安全”
“在访问XXXXXXX.com之前检查你的浏览器”
你有印象吗?如果你正在读这篇文章,你以前可能已经跑到Cloudflare的等候室。
这也被称为CloudflareJavaScript挑战或CloudflareI Am Under Attack页面,这是Cloudflare的主要保护措施。如果你想绕过Cloudflare,你需要绕过这个页面。
当您在浏览器中访问受Cloudflare保护的网站时,您首先需要在Cloudflare的等待室中等待几秒钟。在这段时间里,你的浏览器会解决一些挑战,以证明你不是一个机器人。如果你被标记为机器人,你会得到一个 “访问被拒绝 “的错误。否则,你会被自动重定向到实际的网页上。
一旦挑战被解决了一次,你就可以自由地浏览网站一段时间,而不需要再次等待。
但在这几秒钟的等待时间里,究竟发生了什么?如果你希望绕过Cloudflare,你需要充分了解它的内部结构,以欺骗它的验证过程。
为了回答这个问题,我们将深入研究Cloudflare的JavaScript挑战,并向你展示如何对其进行反向工程。系好你的安全带,因为这将是一个技术性的问题!
逆向工程:Cloudflare的JavaScript挑战
如果你想为任何反僵尸系统制作自己的旁路,你首先需要对它进行逆向工程。创建一个Cloudflare的旁路也不例外。
在这个例子中,我们将对AW LAB上出现的Cloudflare等待室页面进行逆向工程。请随意点击链接,并跟着做!
第1步:检查网络日志
首先,在你的浏览器中打开开发者工具,并导航到 “网络 “标签。然后,我们将让它们打开并浏览AW LAB网站。
在我们从挑战页重定向到实际网站后,我们会注意到以下关键请求(按时间顺序排列)。
- 一个最初的
GET到https://en.aw-lab.com/,响应的主体是等待室的HTML。该HTML包含<script>标签,其中有一个重要的匿名函数。这个函数做一些初始化工作,并加载 “initial challenge “脚本。
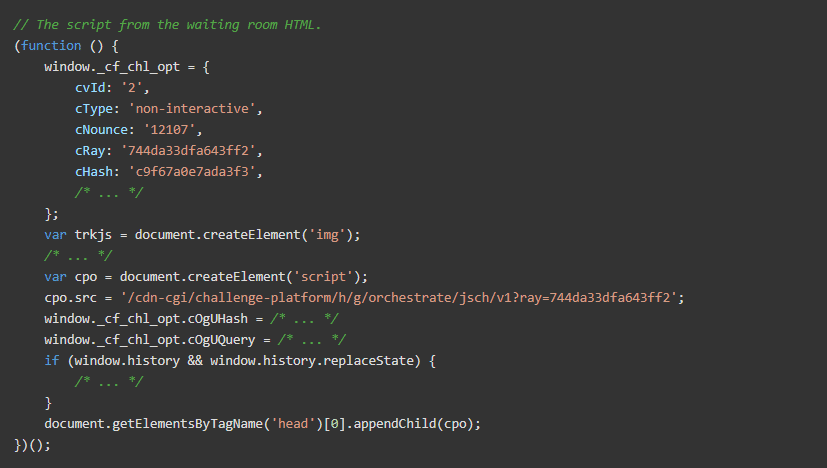
这个脚本(以及接下来的许多脚本)会根据请求进行轮换,所以如果你在浏览器中跟随,它可能会对你来说略有不同。
GET到 “initial challenge “脚本:https://en.aw-lab.com/cdn-cgi/challenge-platform/h/g/orchestrate/jsch/v1?ray=<rayID> ,其中<rayId>是上面的window._cf_chl_opt.cRay的值。它返回一个被混淆的JavaScript脚本,你可以在这里查看。注意:这个脚本在每次请求时都会旋转变化。
向https://en.aw-lab.com/cdn-cgi/challenge-platform/h/g/flow/ov1/<parsedStringFromJS>/<rayID>/<cHash>发出POST请求,其中<parsedStringFromJS>是初始挑战脚本中定义的字符串,<cHash>是window._cf_chl_opt.cHash的值。请求主体是一个URL编码的有效载荷,格式为:v_<rayID>=<initialChallengeSolution>。这个请求的响应体似乎是一个长的base64编码的字符串。
第二次POST请求到https://en.aw-lab.com/cdn-cgi/challenge-platform/h/g/flow/ov1/<parsedStringFromJS>/<rayID>/<cHash>。有效载荷遵循与前一个请求相同的格式,并再次返回一个长的base64编码的字符串。该请求负责发送第二个 Cloudflare 挑战的解决方案。
最后一个POST请求到https://en.aw-lab.com/,其中有一些加密形式的数据是这种格式。

对这一请求的响应给了我们目标网页的实际HTML和一个cf_clearancecookie,使我们能够自由访问该网站而不需要解决另一个难题。
请求流并没有给我们提供太多信息,特别是所有的数据看起来要么是加密的,要么是随机的文本流。因此,这就排除了试图通过黑盒逆向工程来绕过Cloudflare的可能性。
这可能会让你有比开始更多的问题。这些请求来自哪里?有效载荷中的数据代表什么?base64响应体的目的是什么?
那么,没有比 “初始挑战 “脚本更好的地方来寻找答案了。到目前为止,我们一直避免深入研究Cloudflare的代码,但现在我们别无选择。请注意,这不是在公园里散步!如果你准备好迎接挑战,请跟我们一起。我们将从一些动态分析开始。
第2步:调试Cloudflare Javascript挑战脚本
Cloudflare的脚本被严重混淆了。在对脚本的功能知之甚少的情况下,直接钻进去试图读懂它,那将是一场噩梦。
幸运的是,在写这篇文章时,Cloudflare并没有使用任何形式的反调试保护。打开你的浏览器的开发工具,为所有的请求设置一个XHR/fetch breakpoint 。
请确保清除你的cookies,以便Cloudflare再次将你置于等待室。保持你的开发者工具打开,导航到AW LAB。
你会注意到,在 “initial challenge “脚本加载后的几毫秒内,你的XHR断点被触发了(在第一个POST请求被发送之前)。
现在,你可以看到并访问当前范围内的所有变量和函数。然而,从屏幕上显示的变量值中你能推断出的东西并不多,而且代码也无法阅读。
仔细观察这个脚本,你会发现有一个函数被调用了一千多次。在这个例子中,那就是c函数(尽管它在你的脚本中可能有一个不同的名字)。当调用时,总是有一个字符串化的十六进制数字作为参数。让我们试着在DevTools控制台中运行它。
这样看来,Cloudflare使用了一种掩盖字符串的混淆机制。通过运行该函数并将其调用替换为其返回值,我们可以将上述截图中的底部两行简化为这样。

使用同样的技术在控制台中运行代码,我们可以推断出变量o和aE分别代表窗口和一个XMLHttpRequest实例。我们还可以将括号符号转换为点符号,从而得出。

这并不完美,但代码对我们来说越来越容易阅读了。简化所有隐藏字符串的函数调用会提高脚本的可读性。然而,手动操作会花费很多时间。我们将在下一节中解决这个难题,但现在让我们继续前进。
如果你在调试器中按下 “继续到下一个断点 “按钮,你的浏览器将发送第一个帖子请求。在收到响应后,它将立即在下一个断点上暂停。
好一个情节转折!调试器在一个完全不同的脚本中暂停了。这个新脚本就是我们所说的Cloudflare的 “主 “或 “第二 “Javascript挑战。但是,如果你看一下网络日志,并没有向这个特定的脚本发出GET请求!那么,它是从哪里来的呢?
仔细看一下这个脚本,我们可以看到它是一个匿名函数。在我们的例子中,该脚本的名称是VM279。根据 StackOverflow 上的这个线程,这第二个脚本可能是在初始挑战脚本中使用eval或类似的方法进行评估。我们可以确认这一点,因为调用堆栈显示Cloudflare的 “initial challenge “脚本是发起者!我们可以确认这一点。
如果我们点击启动器,我们可以看到这个脚本在 “initial challenge “脚本中被评估的地方。
我们将使用同样的方法来评估c函数的调用,以撤销字符串的隐藏,并将o替换为window,这样我们就得到了这个结果。

看起来这个函数正在根据前一个断点的XMLHttpRequest的responseText中包含的数据创建一个新函数。Cloudflare 可能使用一些密码将其解密为可执行脚本。
好吧,我们已经取得了一些进展。然而,Cloudflare的脚本仍然无法读懂。即使是手动调试,我们也无法弄清楚更多。如果你想创建一个 Cloudflare 旁路,我们需要能够完全理解它。而要做到这一点,我们需要对它进行去混淆处理。
第 3 步:对 Cloudflare Javascript 质询脚本进行去混淆处理
这不会是微不足道的。Cloudflare 在他们的代码中使用了很多混淆技术,在本文中涵盖所有这些技术是不切实际的。这是一个(非详尽的)示例列表:
- 字符串隐藏。Cloudflare 删除对字符串文字的所有引用。在上一节中,我们看到该
c函数充当字符串隐藏器。 - 控制流扁平化。
JUMPCloudflare通过使用无限循环和中央 switch 语句调度程序来模拟类似汇编的指令,从而模糊了程序的控制流这是 Cloudflare 脚本中的一个示例: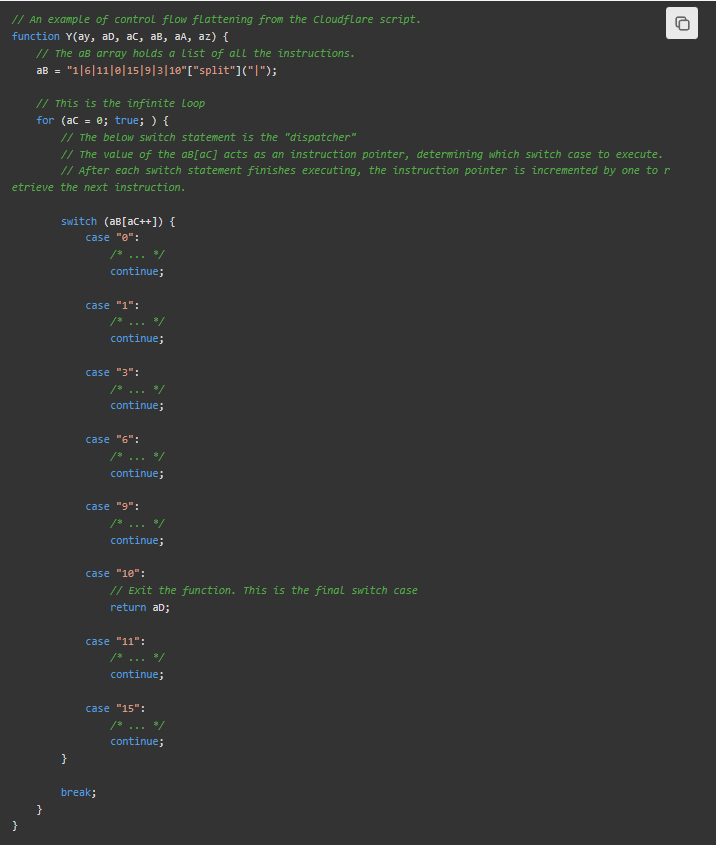
- 代理功能。Cloudflare 将所有二进制操作(
+、-、==等/)替换为函数调用。这会降低代码的可读性,因为您经常需要查找额外函数的定义。这是一个例子: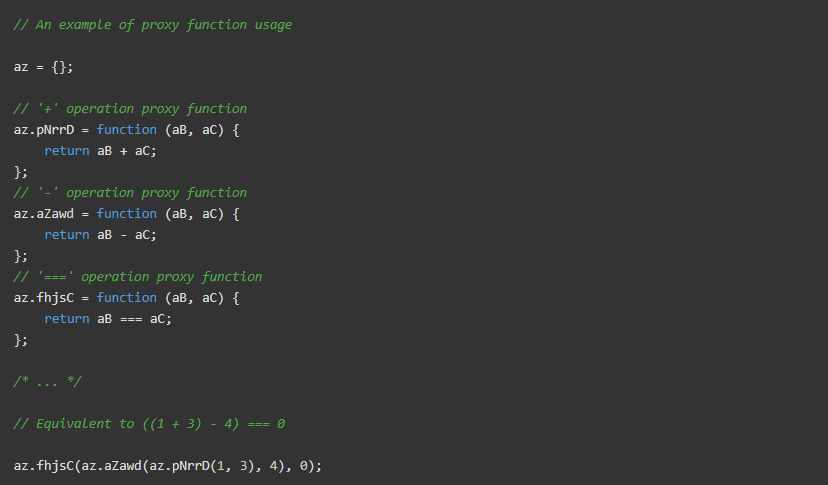
- 原子操作。尤其是在主要/次要挑战脚本中,Cloudflare 利用 javascript 的原子部分(一元表达式、数学运算和空数组)将简单的字符串或数字文字转换为长而复杂的表达式。这种技术很容易让人联想到JSFuck。例子:
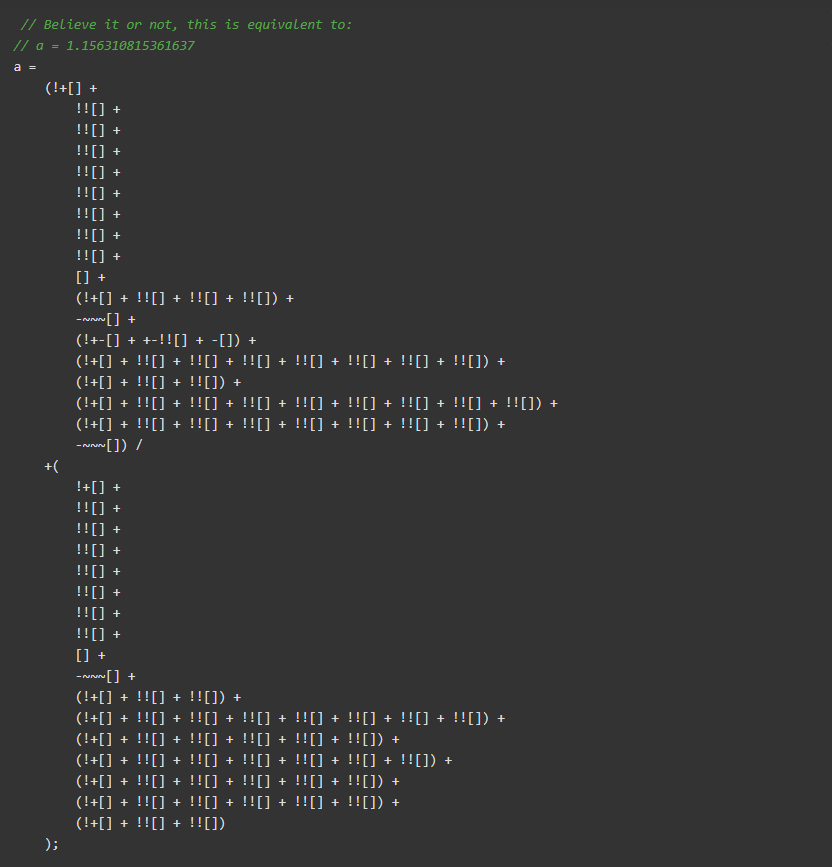
开发 Cloudflare 绕过并非易事的原因在于其脚本的混淆性和动态性。每次进入 Cloudflare 等候室时,您都会面临新的挑战脚本。
如果您想创建自己的 Cloudflare 旁路,则需要一些高度专业化的技能。Cloudflare 的挑战脚本的混淆功能已经足够好了,您不能只将其放入通用反混淆器中并获得可读的输出。您需要创建一个自定义反混淆器,能够动态解析每个新的 Cloudflare 挑战脚本并将其转换为人类可读的代码。提示:尝试操作脚本的抽象语法树
一旦您制作了一个有效的动态反混淆器,您将能够更好地理解 Cloudflare 的反机器人在您的浏览器上执行的所有检查,以及如何复制挑战解决过程。
在下一步中,我们将从去混淆的 Cloudflare 脚本中分析一些活跃的机器人检测实现。让我们开始吧!
第4步:分析反混淆脚本
还记得那些神秘的有效载荷和 base64 编码的响应体吗?好吧,现在我们可以了解它们是如何工作的了!
Cloudflare 的加密
回想一下这段代码片段,我们确定响应文本正在用于评估主要/次要质询脚本:

去混淆的版本如下所示:

最后,ab.pgNsC只是该ax功能的代理包装器。反混淆ax函数如下所示:
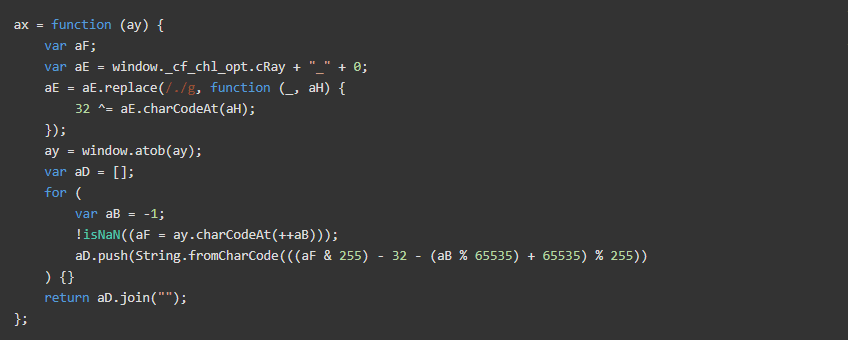
你能猜出这个函数是做什么的吗?是解密功能!
Cloudflare 使用密码加密主要/次要质询脚本。然后,在POST解决初始质询的第一个请求之后,Cloudflare 返回加密的第二个质询脚本。
为了实际执行挑战,它被解密为一个字符串,该ax函数window._cf_chl_opt.cRay用作解密密钥。然后将该字符串传递给Function 构造函数以创建一个新函数并使用()!
我们之前还讨论了 Cloudflare 的主动机器人检测技术。现在,我们可以重新访问其中的一些以查看它们的实现!
验证码
在这里,我们可以看到 Cloudflare 如何加载 hCaptcha 实例:

Canvas指纹识别
在此代码段中,Cloudflare 正在创建一组Canvas指纹函数,以便稍后在脚本中使用:
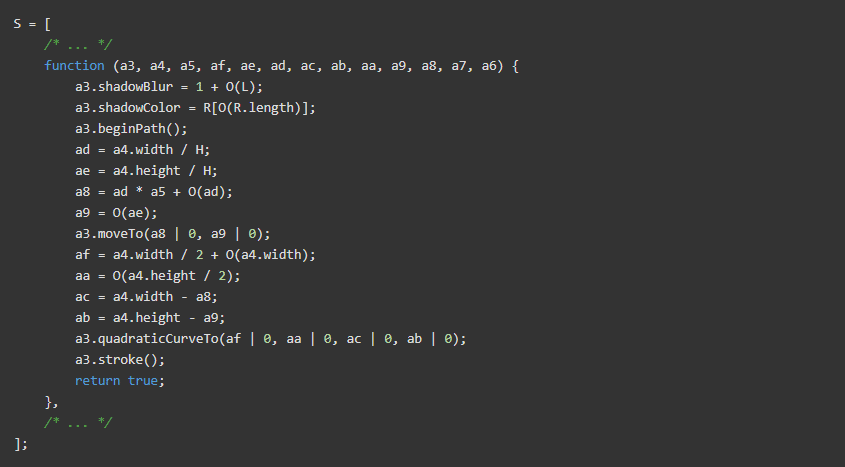
时间戳跟踪
脚本中有很多地方 Cloudflare 会在浏览器中查询时间戳。这是一个例子:
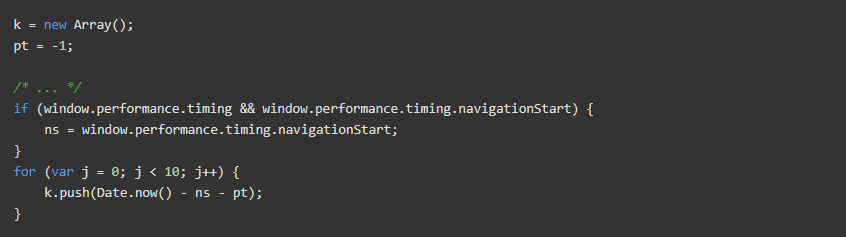
事件追踪
在这里,我们可以看到 CloudflareEventListener在网页中添加了 s 来跟踪鼠标移动、鼠标点击和按键操作。
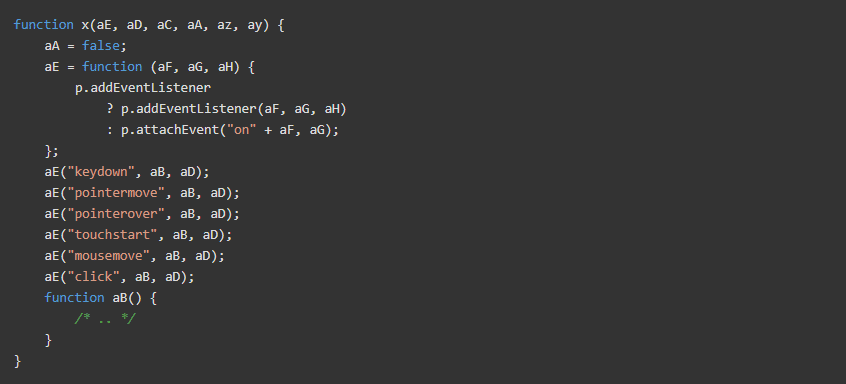
自动浏览器检测
以下是 Cloudflare 为检测流行的自动浏览库的使用而必须进行的一些检查:
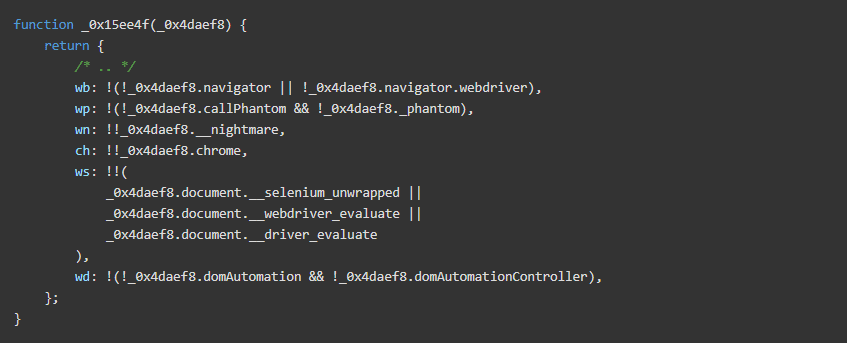
Sandboxing检测
在此代码段中,脚本通过搜索仅节点process对象来检查它是否在 NodeJS 环境中运行:
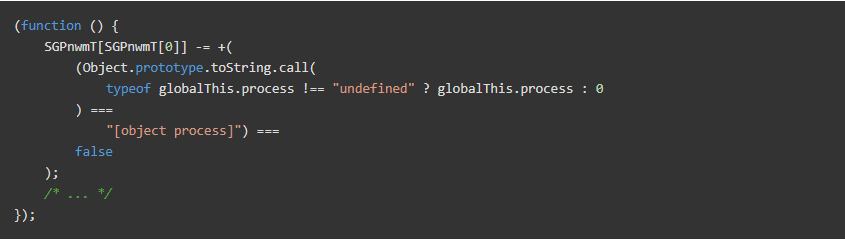
为了检测对本机函数的任何修改(例如, monkey patching),CloudflaretoString会对它们执行以检查它们是否返回"[native code]"。

第5步:把它们放在一起
到目前为止,这是一段相当长的旅程!我们知道,有很多东西需要吸收。让我们休息一下,回顾一下到目前为止您所学到的知识:
- Cloudflare 反机器人的目的
- Cloudflare 使用的主动和被动机器人检测技术
- 什么是 Cloudflare 等候室/挑战页面
- 如何对 Cloudflare 等候室的请求流程进行逆向工程
- 如何对 Cloudflare 挑战脚本进行去混淆处理
- Cloudflare 如何在他们的 Javascript 挑战中实施机器人检测技术
现在,最后一步是将所有这些知识放在一起并绕过 Cloudflare!
如何绕过 Cloudflare
我们已经提到这不是一件容易的事,但是如何绕过 Cloudflare 保护呢?要绕过 Cloudflare,您需要结合从前几节中获得的所有知识。
如您所知,Cloudflare 有两种机器人检测方法:被动指纹识别和主动机器人检测(通过他们的 JavaScript 挑战)。要绕过 Cloudflare,您需要在他们两人的雷达下潜行。为了让您开始,这里有一些提示。
绕过 Cloudflare 被动机器人检测
- 使用高质量的代理。要将您的爬虫伪装成合法用户,请使用住宅代理。Cloudflare 很容易检测到数据中心代理和 VPN,并将其归类为可疑流量。此外,来自单个 IP 地址的过多请求可能会导致阻塞,因此请确保在每个会话中轮换您的代理以避免这种情况。
- 模仿浏览器的标题。通过确保从原始请求发送所有 HTTP 标头,使您的抓取工具的请求看起来尽可能真实。这包括为每个请求提供有效的 cookie 标头!
- 匹配列入白名单的指纹。如果你决定走浏览器自动化路线,你的爬虫可能会默认满足这个要求。但是,只要您使用构建库的确切用户代理和浏览器版本。在开发完全基于请求的爬虫时,这变得更加乏味。您需要从您打算模拟的浏览器中捕获和分析数据包。您选择的编程语言是有限的。它必须具有足够的低级访问权限来控制 Cloudflare 的 TLS 和 HTTP/2 指纹规范的所有组件,以便您可以1:1 匹配浏览器。
请记住,被动机器人检测是 Cloudflare 的第一层防御。如果你想绕过 Cloudflare,你不能忽略这一步。
如果您的活动被他们的被动机器人保护系统标记为可疑,您将立即被阻止。相反,跳过它们甚至可能让您跳过活动的机器人保护检查。
绕过 Cloudflare 主动机器人检测
- 重构挑战解决逻辑。这需要对 Cloudflare 等候室的内部结构有专业的了解。研究它的请求流和反混淆脚本。您需要准确 了解 Cloudflare 执行的检查、它们的执行顺序以及如何绕过它们。您还需要复制 Cloudflare 的各种有效负载的加密和解密。这是创建绕过最困难的部分,因为 Cloudflare 质询脚本是动态的。每个会话甚至可能需要您即时对新脚本进行去混淆处理,以解析特定值以在求解器中使用。
- 收集真实设备数据。即使您完全了解它们是如何制作的,有些指纹也太不切实际而无法模仿。例如,Cloudflare 的 Canvas 指纹识别。与 TLS 或 HTTP/2 指纹不同,它严重依赖于软件和硬件的移动部件。硬件组件的功能太先进了,无法尝试和模仿,而不是你想把所有时间都花在设计一个抓取项目上。相反,请考虑从真实用户的设备中收集指纹数据。然后,您可以在需要使用时将这些数据注入到求解器中。但是,只要几个,你就不会走得太远。您最好的选择是在高流量网页上托管一个收集器,以确保您有足够的设备来避免对 Cloudflare 的机器学习系统产生怀疑。
- 使用自动化浏览器/Sandboxing脚本如果您想抽象一些挑战解决逻辑,您可以考虑直接执行 Cloudflare JavaScript 挑战。这可以在浏览器中使用自动化工具或通过在沙箱(如 JSDOM)中模拟浏览器来实现。这种方法的缺点是性能。运行或模拟浏览器环境将比基于请求/算法的挑战求解器慢得多且计算成本高。另外,请回想一下,Cloudflare 会检查自动浏览器和Sandboxing。要绕过它们,您首先必须了解哪些存在以及它们是如何工作的。因此,无论是否为Sandboxing,您都无法跳过对 Cloudflare 挑战脚本进行反混淆!
如果你已经走到这一步,干得好!您现在已经熟悉了为 Cloudflare 的反机器人挑战制作求解器的过程。
如果您发现自己在此过程中迷失了方向,请不要担心。我们明白了,绕过任何反机器人都会感觉像是一项艰巨的任务。但这并不意味着你应该放弃你的抓取项目!
从头开始绕过 Cloudflare 是一项复杂的任务,如果您打算自己做,没有任何捷径可走。但是,它不一定非得这么难!有时候,最好让别人帮您处理。有时,最好让别人来帮你解决这个问题。
绕过Cloudflare的最简单方法
大多数时候,花费大量的时间、精力和金钱来开发和维护你自己的解算器是不现实的。你可以考虑使用以下代理服务器绕过Cloudflare和所有其他反机器人解决方案。从而专注于您的数据爬取,让代理来处理其他问题。
结 论
恭喜你坚持到最后!我们知道这是一篇冗长的文章,但 Cloudflare 的高度复杂性使其成为必需品。
谢谢阅读!我们希望本指南能够帮助您了解有关 Cloudflare 机器人检测技术、如何对其进行逆向工程以及如何最终绕过它们的宝贵知识。您今天学到的方法也不只是 Cloudflare 特有的:您可以出去参考它来帮助您绕过其他反机器人!

