

你是否曾将数据从网站上的表格中手动复制到Excel电子表格中,以便对其进行分析?如果你有,那么你就知道这是一个多么乏味的过程。幸运的是,有一个工具可以让你使用Node.js轻松地从网页上刮取数据。你可以使用Cheerio从几乎所有的HTML中收集数据。你可以从HTML字符串中提取数据,或者爬取网站来收集产品数据。
在这篇文章中,你将学习如何使用Cheerio从静态HTML内容中刮取数据。如果你需要参考Cheerio的文档,你可以在这里找到它。
什么是Cheerio?
Cheerio是jQuery的一个实现,它在一个虚拟的DOM上工作。这个DOM是由一个HTML字符串构建的,没有运行任何JavaScript或应用CSS样式。由于它不显示任何东西,这使得它成为在服务器上刮取数据的好方法,或者如果你正在创建一个由云提供商托管的服务,你可以在无服务器函数中运行它。
因为Cheerio不运行JavaScript或使用CSS,所以它真的很快,在大多数情况下都能工作。如果你想爬取一个需要运行JavaScript的网页,像jsdom这样的东西会更好。
用Cheerio爬取数据
本文将指导你完成一个简单的爬取项目。你将从维基百科收集国家人口数据,并将其保存到CSV中。
最终爬虫的副本可以在GitHub上找到。
着手进行设置
在你开始之前,你需要在你的电脑上安装Node.js。建议使用nvm,但你也可以直接安装Node.js。要做到这一点,请访问他们的网站,并按照长期服务(LTS)版本的安装说明。
现在你已经安装了Node.js,创建一个目录来存储你的项目并使用npm初始化项目。
mkdir country-population cd country-population npm init
在npm设置你的项目时,你会被提示回答几个问题;接受所有的默认值就可以了。一旦你的项目准备好了,就向它添加一些依赖项。
npm install cheerio axios npm install -D typescript esbuild esbuild-runner
你正在安装axios来下载网页内容,并安装cheerio来解析它。你还安装了typescript和esbuild-runner,以便你可以执行你的项目。
最后,在你的package.json中添加一个脚本,它将运行你的爬虫。
"scripts": {
"scrape": "esr ./src/index.ts"
}
加载一个HTML字符串
要开始使用Cheerio,你需要向它提供一些HTML数据,它将使用这些数据来建立一个DOM。最简单的方法是传入一个硬编码的字符串。在你的项目中创建一个名为src\index.ts的文件来开始。
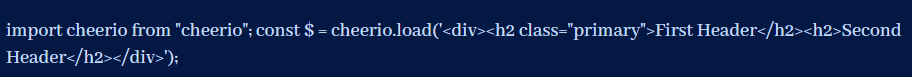
正如你所看到的,你所需要做的就是将一个HTML字符串传入Cheerio的加载方法。Cheerio本身并没有提供任何获取字符串的功能。这意味着你可以直接传入一个常量,加载一个本地的HTML文件,或者使用HTTP请求从网上下载内容。
在测试爬取脚本时,下载网页内容并保存在本地可能会有帮助;这样,你就不必担心连接问题会破坏你的单元测试。
使用选择器来寻找节点
一旦你把数据解析到Cheerio中,你将希望能够从其中提取数据。这主要是通过jQuery的选择表达式完成的。例如,要在你加载的数据中只选择第一个标题,你可以使用以下代码:
const firstHeader = $('h2.primary');
console.info(firstHeader.text());你可以从你的项目根部运行以下命令来测试你的爬虫:
npm run scrape
你应该看到你的脚本输出 “First Header”,表明它能够解析传入的HTML字符串并找到第一个设置了主类的h2节点。
迭代节点
你已经看到了当你只寻找一个节点时,基本选择器是如何工作的,但当你需要遍历多个节点时,又该怎么办呢–例如,你的HTML字符串中所有的h2节点?
要做到这一点,你需要使用each方法。这个方法提供了一个当前结果的索引和一个元素的引用。为了得到实际的元素,你需要把提供的引用传递给Cheerio。下面的例子显示了你如何在示例字符串中找到每个h2节点的文本内容。
$('h2').each((idx, ref) => {
const elem = $(ref);
console.info(elem.text());
});如果你把这个添加到你现有的代码中,当你执行它时,你应该看到添加了以下输出:
First Header Second Header
搜集人口数据
现在你已经了解了如何使用Cheerio,你可以建立一个应用程序,实际向网页发出请求,刮取数据,并将结果保存为有用的格式。在这篇文章中,你将从维基百科上抓取国家人口数据,并将结果保存到CSV文件中。
要求提供数据
你可以使用任何库来请求页面内容。在这里,你将使用Axios,因为它的界面很简单。如果你对Axios不熟悉,你可以在它的文档网站上阅读更多的信息。
要开始使用Axios,通过在项目根目录下运行npm i axios将其添加到项目的依赖项中。安装后,你可以在你的index.ts文件的顶部添加一个导入语句:
import axios from "axios";
你现在要创建实际的爬虫,所以继续前进,在导入后删除index.ts中的一切。
接下来,你将创建一个函数,下载数据并将其解析为一个对象数组。第一步是使用Axios下载数据。
const getPopulationData = async (): Promise<Array> => {
// Get the data
const targetUrl = "https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population";
const pageResponse = await axios.get(targetUrl);
// hold results
// load content to cheerio
// scrape the content
// return results
}然后你需要在函数中添加几个数组,这些数组将在解析过程中使用。
// hold results const keys = []; const result = [];
一切都为解析做好了准备,所以将页面加载到Cheerio中。
// load content to cheerio const $ = cheerio.load(pageResponse.data);
寻找正确的节点
这一部分有点棘手,你需要离开你的IDE来进行工作。首先,在你的浏览器中打开维基百科上按人口分类的国家和依赖性列表。一旦页面加载完毕,向下滚动到表格并右键点击它。在打开的菜单中,点击 “Inspect“。
这将打开你的浏览器的开发工具,并选中你点击的元素。现在,你必须玩一玩选择查询,看看什么能在Cheerio中发挥作用。在基于Chrome的浏览器中,你可以在开发工具的元素视图中按下Ctrl+F,然后在打开的搜索框中输入一个选择器。
在这个例子中,搜索选择器table.wikitable。你应该看到一个结果;这正是你想要的。现在你可以选择表了,那么如何获得实际的数据行呢?只需在选择器的末尾添加一个tr,表示你想选择该表的后代行。把你的查询改为table.wikitable tr,你应该会看到少于250个结果。
提取数据
现在你有了一个选择器来获取表的行数,是时候实际提取数据了。回到你开始的那个函数,添加以下内容来找到表并迭代其行。
// scrape the content
$("table.wikitable")
.find("tr")
.each((row, elem) => {});在each方法的回调中,你需要遍历该行的数据单元。第一行将是表头;你要保存这些值,用于所有其他行的对象键。
如果你在Chrome浏览器中看了上面描述的页面,你可能会想,为什么不能用table.wikitable > thead > tr这样的选择器来找到表头的内容。问题是Cheerio不会在网页上运行JavaScript,如果你下载该网页并在文本编辑器中打开它,你会看到thead元素是由表体的第一行动态创建的。
if(row === 0) {
$(elem).find('th').each((idx, elem) => {
const key = $(elem).text().trim();
console.info(`Key ${idx}`, key);
keys.push(key);
});
return;
}现在你有了所有的对象键,遍历剩余行的数据单元来构建一个对象。然后,将该对象添加到结果列表中。
const nextCountry = {};
$(elem).find('td,th').each((idx, elem) => {
const value = $(elem).text().trim();
const key = keys[idx];
nextCountry[key] = value;
});
result.push(nextCountry);在getPopulationData方法的最后,你需要返回结果变量。
// return results
return result;
};最后,你需要从文件的根部调用你的方法。
getPopulationData().then((results) => console.info(`Found ${results.length} results`));如果你现在运行该文件,你应该看到网站的每一个列名的输出:
Key 0 Rank Key 1 Country or dependent territory Key 2 Region Key 3 Population Key 4 % of world Key 5 Date Key 6 Source (official or from the United Nations) Key 7 Notes Found 242 results
保存结果
所以,现在你有一个Node.js应用程序,可以下载一个维基百科页面,并将表的内容解析成一个JSON对象。下一步是将该数据保存为CSV文件,以便你可以分析它。要做到这一点,你将使用json2csv包。通过运行npm i json2csv来安装它,然后把它和基于承诺的fs包一起导入你的源代码顶部。
import json2csv from "json2csv"; import * as fsp from "fs/promises";
然后创建一个新的异步方法,接受国家数据,将其转换为CSV,然后将其保存到一个文件中。
const saveCsv = async (countries: Array) => {
console.info(`Saving ${countries.length} records`);
const j2cp = new json2csv.Parser();
const csv = j2cp.parse(countries);
await fsp.writeFile("./output.csv", csv, {encoding: "utf-8"});
};最后,修改你调用getPopulationData的那一行,使其将结果传递给新的saveCsv方法。
getPopulationData().then(saveCsv);[文中代码源自Scrapingbee]
再次运行该程序,你会看到一个output.csv文件被添加到当前目录中。在你最喜欢的CSV浏览器中打开它,你会看到你刚刚解析的所有国家人口数据。
总 结
从网站上爬取数据可能是一个非常乏味的过程。幸运的是,有一些伟大的项目和工具可以帮助实现这一过程的自动化。在这篇文章中,我们向你介绍了Cheerio。使用它,你看到了如何加载HTML,使用选择器来寻找数据,以及如何在选定的元素上迭代,并从中提取数据。
你还看到了如何使用Chrome开发工具来确定使用哪些选择器。最后,你看到了如何将你提取的数据导出到CSV文件,以便你可以在Excel、Pandas或你选择的工具中进行分析。

