

如果你突然想到了下一个大项目的想法:”我利用X公司提供的数据,为它建立一个前端如何?”你开始编码,发现X公司并没有为他们的数据提供API。他们的网站是他们数据的唯一来源。
现在是时候求助于良好的老式网页爬取,即从网站的HTML源代码中解析和提取数据的自动化过程。
jsoup是一个实现WHATWGHTML5规范的Java库,可以用来解析HTML文档,从HTML文档中寻找和提取数据,并操作HTML元素。它是一个简单的网络爬取的优秀库,因为它的性质很简单,而且它能够以浏览器的方式解析HTML,这样你就可以使用常见的CSS选择器。
在这篇文章中,你将学习如何使用jsoup在Java中进行网页爬取。
安装jsoup
本文使用Maven作为构建系统,因此要确保其已安装。注意,你也可以在没有Maven的情况下使用jsoup。你可以在jsoup的下载页面找到相关说明。
你将在本文中构建的应用程序可以在GitHub中找到,如果你想克隆它并跟着做,或者你可以按照说明从头开始构建该应用程序。
首先生成一个Maven项目:
mvn archetype:generate -DgroupId=com.example.jsoupexample -DartifactId=jsoup-example -DarchetypeArtifactId=maven-archetype-quickstart -DarchetypeVersion=1.4 -DinteractiveMode=false
名为jsoup-example的目录将存放项目文件。在文章的其余部分,你将在这个目录下工作。
编辑pom.xml文件,在依赖关系部分添加jsoup作为依赖关系:

本文使用的是1.14.3版本,这是在写作时的最新版本。当你阅读本文时,请到jsoup下载页面查看哪个版本是最新的。
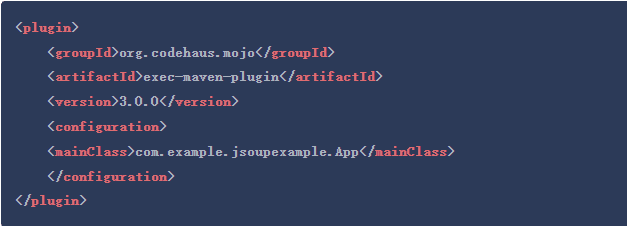
在plugins部分,添加Exec Maven Plugin。
使用jsoup
网络爬取应该总是从人的角度出发。在直接跳入编码之前,你应该首先熟悉目标网站的情况。花一些时间研究网站的结构,弄清楚你想爬取什么数据,并查看HTML源代码以了解数据的位置和结构。
在这篇文章中,你将爬取ScrapingBee的博客,并收集有关发表的博客的信息:标题、链接等。这是很基本的,但它将帮助你开始你的网络爬取之旅。
让我们开始探索这个网站。在浏览器中打开https://www.scrapingbee.com/blog,点击Ctrl+Shift+I,打开开发工具。点击控制台左上角的小光标图标。如果你在启用该功能时将鼠标悬停在网页上的某个元素上,它将在HTML代码中定位该元素。它使你不必手动浏览HTML文件以确定哪些代码对应于哪些元素。这个工具将是你在整个爬取过程中的朋友。
将鼠标悬停在第一篇博文上。你会看到它在控制台中被突出显示,它是一个具有p-10 md:p-28 flex类的div。它旁边的其他博客都是一个具有w-full sm:w-1/2 p-10 md:p-28 flex类的div。
现在你已经对网页中的目标数据的大体结构有了一个大致的了解,现在是时候进行一些编码了。打开src/main/java/com/example/jsoupexample/App.java文件,删除自动生成的代码,并粘贴以下模板代码:
package com.example.jsoupexample;
public class App
{
public static void main( String[] args )
{
}
}HTML解析
jsoup的工作原理是解析网页的HTML并将其转换为Document对象。可以把这个对象看作是DOM的一个程序化表示。为了创建这个Document,jsoup提供了一个有多个重载的parse方法,可以接受不同的输入类型。
一些值得注意的有以下几点。
parse(File file, @Nullable String charsetName): 解析一个HTML文件(也支持gzipped文件)。parse(InputStream in, @Nullable String charsetName, String baseUri): 读取一个InputStream并解析它。parse(String html): 解析一个HTML字符串。
所有这些方法都返回解析后的Document对象。
让我们看看最后一个的操作。首先,导入所需的类:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document;
在main方法中,写下以下代码:

正如你所看到的,一个HTML字符串被直接传递到解析方法中。Document对象的title方法返回网页的标题。使用命令mvn exec:java运行该应用程序,它应该打印出Web Scraping。
把一个硬编码的HTML字符串放在解析方法中是可以的,但它并不真正有用。你如何从一个网页中获取HTML并解析它?
一种方法是使用HttpURLConnection类来向网站发出请求,并将响应的InputStream传递给解析方法。这里有一些示例代码可以做到这一点:
package com.example.jsoupexample;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class App {
public static void main(String[] args) {
URL url;
try {
url = new URL("https://www.scrapingbee.com/blog");
HttpURLConnection connection;
try {
connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("accept", "application/json");
try {
InputStream responseStream = connection.getInputStream();
Document document = Jsoup.parse(responseStream, "UTF-8", "https://www.scrapingbee.com/blog");
System.out.println(document.title());
} catch (IOException e) {
e.printStackTrace();
}
} catch (IOException e1) {
e1.printStackTrace();
}
} catch (MalformedURLException e1) {
e1.printStackTrace();
}
}
}请注意,仅仅为了从网页上获取HTML,就需要大量的模板代码。值得庆幸的是,jsoup提供了一个更方便的连接方法,可以连接到一个网页,获取HTML,并将其解析为一个Document,一气呵成。
只要把URL传给connect方法,它就会返回一个Connection对象:
Jsoup.connect("https://example.com")你可以用这个对象来修改请求属性,比如用data方法添加参数,用header方法添加头信息,用cookie方法设置cookie,等等。每个方法都返回一个Connection对象,所以它们可以被链起来。
Jsoup.connect("https://example.com")
.data("key", "value")
.header("header", "value")
.timeout(3000)当你准备好进行请求时,调用Connection对象的get或post方法。这将返回解析后的Document对象。写下以下代码:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class App {
public static void main(String[] args) {
try {
Document document = Jsoup.connect("https://www.scrapingbee.com/blog")
.timeout(5000)
.get();
System.out.println(document.title());
} catch (IOException e) {
e.printStackTrace();
}
}
}这段代码被包裹在一个try-catch块中,因为get方法会抛出一个IOException。当你运行这段代码时,你应该看到网页的标题被打印出来。
getElementById和getElementsByClass
现在我们来解析一下博客。文档对象提供了许多方法来选择你想要的节点。如果你了解JavaScript,你会发现这些方法与你所习惯的非常相似。
第一个重要的方法是getElementById。它类似于JavaScript中的getElementById。它接受一个ID并返回具有该ID的唯一元素。我们的目标网页有一个ID为content的div。让我们用getElementById()来探测它。
...
import org.jsoup.nodes.Element; // add this import
...
Document document = Jsoup.connect("https://www.scrapingbee.com/blog")
.timeout(5000)
.get();
Element content = document.getElementById("content");
System.out.println(content.childrenSize());注意childrenSize方法的使用,该方法返回元素的子代数。运行这段代码会打印出2,而这个div确实有两个孩子。

在这个特定的例子中,getElementById不是很有用,因为没有多少元素带有ID,所以让我们关注下一个重要方法:getElementsByClass。同样,它与JavaScript中的getElementsByClassName方法类似。请注意,这个方法返回一个Elements对象,而不是一个Element。这是因为可以有多个具有相同类的元素。
如果你记得,所有的博客都有一个p-10类,所以你可以用这个方法来掌握它们:
...
import org.jsoup.select.Elements; // Add this import
...
Elements blogs = document.getElementsByClass("p-10");现在你可以用一个for循环来迭代这个列表:
for (Element blog : blogs) {
System.out.println(blog.text());
}text方法返回该元素的文本,类似于JavaScript中的innerText。当你运行这段代码时,你会看到博客的文本被打印出来。
select
现在我们来解析每个博客的标题。你将使用select方法来完成这个任务。类似于JavaScript中的querySelectorAll,它接受一个CSS选择器并返回一个与该选择器相匹配的元素列表。在本例中,标题是博客中的一个h4元素。
因此,下面的代码将选择标题并从中获取文本:
for (Element blog : blogs) {
String title = blog.select("h4").text();
System.out.println(title);
}下一步是获取博客的链接。为此,你将使用blog.select("a")来选择blog元素中的所有a标签。为了得到链接,使用attr方法,它返回第一个匹配元素的指定属性。由于每个博客只包含一个a标签,你将从href属性中获得链接。
String link = blog.select("a").attr("href");
System.out.println(link);运行它可以打印出博客的链接:
Are Product Hunt's featured products still online today? /blog/producthunt-cemetery/ C# HTML parsers /blog/csharp-html-parser/ Using Python and wget to Download Web Pages and Files /blog/python-wget/ Using the Cheerio NPM Package for Web Scraping /blog/cheerio-npm/ ...
first and selectFirst
让我们看看是否能得到博客的标题图片。这次blog.select("img")将不起作用,因为有两张图片:头像和作者的头像。相反,你可以使用first方法来获得第一个匹配的元素,或者使用selectFirst。
String headerImage = blog.select("img").first().attr("src");
// Or
String headerImage = blog.selectFirst("img").attr("src");
System.out.println(headerImage);带有select功能的高级CSS选择器
现在我们来试试作者的头像。如果你看一下其中一个头像的URL,你会发现它包含 “作者 “这个词。因此,我们可以使用一个属性选择器来选择所有src属性包含 “author “的图片。相应的选择器是img[src*=authors]。
String authorImage = blog.select("img[src*=authors]").attr("src");
System.out.println(authorImage);分页
最后,让我们看看如何处理分页问题。点击第2页的按钮会带你到https://www.scrapingbee.com/blog/page/2/。由此,你可以推断出你可以将页码附加到https://www.scrapingbee.com/blog/page/,以获得该页。由于每一页都是一个独立的网页,你可以把所有的东西都包在一个for循环中,并改变URL来迭代每一页:
for(int i = 1; i <= 4; ++i) {
try {
String url = (i==1) ? "https://www.scrapingbee.com/blog" : "https://www.scrapingbee.com/blog/page/" + i;
Document document = Jsoup.connect(url)
.timeout(5000)
.get();
...
}
} catch (IOException e) {
e.printStackTrace();
}
}i = 1的情况是例外的,因为第一页是在https://www.scrapingbee.com/blog,而不是https://www.scrapingbee.com/blog/page/1。
最终代码
这是最后的代码,增加了一些空格和文字,使其更容易阅读:
package com.example.jsoupexample;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
for(int i = 1; i <= 4; ++i) {
System.out.println("PAGE " + i);
try {
String url = (i==1) ? "https://www.scrapingbee.com/blog" : "https://www.scrapingbee.com/blog/page/" + i;
Document document = Jsoup.connect(url)
.timeout(5000)
.get();
Elements blogs = document.getElementsByClass("p-10");
for (Element blog : blogs) {
String title = blog.select("h4").text();
System.out.println("TITLE: " + title);
String link = blog.select("a").attr("href");
System.out.println("LINK: " + link);
String headerImage = blog.selectFirst("img").attr("src");
System.out.println("HEADER IMAGE: " + headerImage);
String authorImage = blog.select("img[src*=authors]").attr("src");
System.out.println("AUTHOR IMAGE:" + authorImage);
System.out.println();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}下面是输出的样本:
PAGE 1 TITLE: Are Product Hunt's featured products still online today? LINK: /blog/producthunt-cemetery/ HEADER IMAGE: https://d33wubrfki0l68.cloudfront.net/9ac2840bae6fc4d4ef3ddfa68da1c7dd3af3c331/8f56d/blog/producthunt-cemetery/cover.png AUTHOR IMAGE:https://d33wubrfki0l68.cloudfront.net/7e902696518771fbb06ab09243e5b4ceb2cba796/23431/images/authors/ian.jpg TITLE: C# HTML parsers LINK: /blog/csharp-html-parser/ HEADER IMAGE: https://d33wubrfki0l68.cloudfront.net/205f9e447558a0f654bcbb27dd6ebdd164293bf8/0adcc/blog/csharp-html-parser/cover.png AUTHOR IMAGE:https://d33wubrfki0l68.cloudfront.net/897083664781fa7d43534d11166e8a9a5b7f002a/115e0/images/authors/agustinus.jpg TITLE: Using Python and wget to Download Web Pages and Files LINK: /blog/python-wget/ HEADER IMAGE: https://d33wubrfki0l68.cloudfront.net/7b60237df4c51f8c2a3a46a8c53115081e6c5047/03e92/blog/python-wget/cover.png AUTHOR IMAGE:https://d33wubrfki0l68.cloudfront.net/8d26b33f8cc54b03f7829648f19496c053fc9ca0/8a664/images/authors/roel.jpg TITLE: Using the Cheerio NPM Package for Web Scraping LINK: /blog/cheerio-npm/ HEADER IMAGE: https://d33wubrfki0l68.cloudfront.net/212de31150b614ca36cfcdeada7c346cacb27551/9bfd1/blog/cheerio-npm/cover.png AUTHOR IMAGE:https://d33wubrfki0l68.cloudfront.net/bd86ac02a54c3b0cdc2082fec9a8cafc124d01d7/9d072/images/authors/ben.jpg ... [文中代码源自Scrapingbee]
如果你最初没有这样做,你可以从GitHub上克隆这个应用程序,这样你就可以对照它检查你的代码。
总 结
jsoup是在Java中进行网络爬取的一个很好的选择。虽然本文介绍了这个库,但你可以在jsoup文档中找到更多关于它的信息。
尽管jsoup很容易使用,也很高效,但它也有缺点。例如,它不能运行JavaScript代码,这意味着jsoup不能用于爬取动态网页和单页应用程序。在这些情况下,你将需要使用像Selenium这样的东西。

