

你找到了你需要爬取的网站,设置了你的爬虫并启动了它,却悲哀地发现PerimeterX已经阻止了你。但不要陷入绝望! 在放弃爬取数据的目标之前,你可以尝试绕过PerimeterX。
PerimeterX是最早为网站提供安全服务的公司之一,它成立于2004年(比Cloudflare早6年!)。因此,当涉及到阻止机器人时,他们知道自己在做什么。
PerimeterX是如何工作的?
PerimeterX检测系统声称可以保护网站不受机器人的影响,同时对用户体验影响最小。换句话说,除非他们怀疑请求来自机器人,否则尽量不要用验证码解决或等待认证的屏幕来打扰人类用户。
为了实现这一目标,PerimeterX等先进的网络安全系统同时使用被动和主动机器人检测。被动式机器人检测是指一旦收到访问者的请求,就在其服务器上进行检查。主动式机器人检测是指它们在访问者的代理上运行脚本,以收集信息和检测机器人。
一些非详尽的被动机器人检测技术是。
1.IP过滤
像PerimeterX这样的安全公司通常有大量已知被机器人使用的IP清单。他们还可以识别属于数据中心、代理机构或VPN供应商的IP群。网络应用防火墙(WAF)通常为试图访问受保护网站的每个IP分配一些分数或信誉。如果你的机器人使用的IP有一个坏的声誉,你可能会被阻止。
2.检查HTTP请求头
很多机器人使用库或其他非浏览器代理,如python-requests或Axios。这些代理通常不发送一些典型浏览器添加到其请求中的头信息。这是PerimeterX Bot Defender等反机器人系统用来识别和阻止机器人的最简单方法之一。幸运的是,在你的请求中添加HTTP头信息以绕过这种保护很容易。
3.行为分析
PerimeterX对其使用机器学习算法进行行为分析感到非常自豪,这使得它能够根据机器人的行为来识别机器人。例如,他们的系统已经了解到,在短时间内发出数百次请求的IP通常是机器人。当他们检测到这种类型的行为时,他们通常会阻止对受保护网页的访问。
4.指纹和黑名单
我们提到的一些方法,如行为分析或检查HTTP请求头,可以与其他方法相结合,如TLS指纹,以识别访客,即使他们使用不同的IP。一旦网络应用防火墙(WAF)将访问者识别为机器人,他们就会将其添加到黑名单中,以防止他们在未来的访问中进行访问。
如果在应用了绕过被动机器人防御系统的技术后,PerimeterX仍能检测到你,那么可能是它的主动机器人脚本在检测你的机器人。如果你准备创建一个PerimeterX验证码绕过,请准备好用一些混淆的Javascript代码和逆向工程策略来弄脏自己的手。
如何绕过PerimeterX?
绕过他们的Bot Defender系统的一个方法是在你现有的爬虫上添加一个PerimeterX的绕过。要编写PerimeterX绕过的代码,重要的是要了解它的内部结构,而要做到这一点的第一步是对他们的客户端机器人检测脚本进行反向工程。
在这个例子中,我们将分析SSENSE上的antibot实现。那个网站似乎是一个很好的例子,因为很多电子商务网站都使用PerimeterX。我们将主要使用JavaScript,但你在本教程中学到的技术将允许你用Python或其他语言编写PerimeterX的绕过。准备好了吗?让我们开始吧!
第1步:分析网络日志
首先,打开你选择的网络浏览器的开发工具,并切换到网络标签。
接下来,在打开开发者工具的同时,导航到SSENSE。
随着页面的加载,你会注意到网络日志中出现了许多请求。这些是需要注意的重要内容,按时间顺序排列。
一个最初的GET请求到https://www.ssense.com/en-ca。看一下响应,你会看到_pxhd的Set-Cookie头。这是一个重要的cookie:它作为一个会话指示器,也将在未来的请求中使用。你的PerimeterX绕过将需要这个cookie中的一些数据来计算正确的值,这些值将被发送到服务器上进行验证。
还要检查响应主体的HTML是否包含一个<script>标签,该标签可以获取PerimeterX的挑战脚本。

对/<_pxAppId>/init.js的GET请求(其中<_pxAppId>是window._pxAppId的值)。这将返回PerimeterX用于客户端机器人检测的脚本。它是经过混淆和减化的,所以你暂时无法了解很多。点击这里可以看到整个脚本。
然后,向/<_pxAppId>/xhr/api/v2/collector发出一个POST请求。请求的有效载荷是一个字符串,内容类型为application/x-www-form-urlencoded,并包含以下数据。
<payload>是一个经过加密和Base64编码的字符串。<appId>是以前定义的window._pxAppId的值。<tag>是一个版本标签(每个站点都是静态的),例如:v8.0.2。<uuid>是一个随机生成的UUID,例如:4420aff0-351d-11ed-95d0-c137f4896ca9。<ft>是一个整数(每个站点都是静态的),例如:278。<seq>的值是0。- <
en>的值是NTA。 <pc>是一个整数,例如:3195683956001701。<pxhd>是_pxhdcookie的值。<rsc>的值为1。
响应主体是一个JSON对象,有一个顶级字段:do。do字段包含一个字符串数组。其格式如下。

还有第二个POST请求到/<_pxAppId>/xhr/api/v2/collector。有效载荷的内容类型与之前相同,格式类似,但增加了一些字段。
<payload>是一个更长的、加密的+Base64编码的字符串。<appId>、<tag>、<uuid>、<ft>和<pxhd>与之前的请求相同。<seq>的值是1。- <
en>的值为NTA。 <cs>是一个SHA2-256哈希值,例如:dd2d5dc601445d684b2c4249a4c68f300048446afd4fece93c44ae41f62bdda3<pc>是一个整数,例如:1670315818019117<sid>是一个字符串,例如:4415dfc2-351d-11ed-a66d-7275714f5843<vid>是一个字符串,例如:43c15b2f-351d-11ed-97ec-797549415148<cts>是一个字符串,例如:4415e33e-351d-11ed-a66d-7275714f5843<rsc>的值为2。
如果你仔细看看,你会发现cs、sid、vid和cts字段是直接从第一个POST请求返回的JSON对象中导出的。
此外,相对于第一个POST请求,seq和rsc的值已经增加了1。这种行为在接下来的所有POST请求中也得到了保持,所以我们可以确定这些字段作为某种请求计数器的作用。
PerimeterX在响应体中发送了另一个JSON对象,再次包含一个字符串数组。

你可能已经注意到,所有的POST请求都没有包含Set-Cookie响应头。通常情况下,一旦浏览器通过了机器人检测检查,反机器人系统就会设置特殊的cookies或头信息,以便在未来的请求中使用。然后,一旦客户向受保护的端点发出请求,请求中的这些头文件/cookies就会在服务器端得到验证。
那么,在PerimeterX的情况下,这是如何做到的呢?如果你向一个受PerimeterX保护的端点发出请求,你不会看到任何不寻常的头信息。不过,你会注意到似乎是一些与PerimeterX有关的cookie。为了更清楚地了解情况,你可以查看网站上的所有 cookie,并通过关键字px 进行过滤。
这些是PerimeterX的清除cookies。它们在服务器端被检查,以确定一个请求是否应该被阻止或转发到原点。但是,请记住,在网络日志中没有关于这些cookie被设置为Set-Cookie头的记录。那么,它们是从哪里来的呢?
你可能会从POST请求的响应体中认出这些cookie的名称和值。这肯定意味着这些cookie是直接通过JavaScript设置的,考虑到所有PerimeterX的cookie都没有Http-Only标志,这就说得通了。
注意:根据受PerimeterX保护的网站的安全级别、你的浏览器和你的设备,挑战脚本的行为及其请求可能略有不同。在撰写本文时,SSENSE只要求向/<_pxAppId>/xhr/api/v2/collector发出上述两个POST请求。第二个POST会产生一个_px2的cookie,这是一个主要的通关cookie,可以让人不受限制地进入一个网站。安全性较高的网站可能需要向/<_pxAppId>/xhr/api/v2/collector发出额外的POST请求,以获得一个_px3cookie。对于这些网站,_px3充当了必要的清除cookie。 不过不用担心,我们在这里讨论的技术对绕过高安全级别网站的PerimeterX也很有用。
好的,干得好通过分析这些请求,我们了解了很多关于 PerimeterX 的行为方式。不幸的是,我们仍然缺少很多信息。我们仍然不知道加密的有效载荷字段中包含哪些数据,其他一些字段是如何生成的,以及该脚本执行了哪些客户端机器人检测检查。如果你想绕过PerimeterX,这些知识是至关重要的。
如果我们想回答剩下的这些问题,我们别无选择,只能直接查阅PerimeterX的挑战脚本,弄清楚它到底是如何工作的。
第2步:对PerimeterX的JavaScript挑战进行反混淆处理
为了让反向工程师看不懂脚本,PerimeterX对他们的Javascript挑战进行了混淆处理。下面是一些例子的非详尽清单。
字符串隐蔽性。这种技术用对解码器函数的调用取代了对字符串字面的所有引用。在 PerimeterX 中,字符串要么被 Base64 编码,要么用一个简单的 XOR 密码进行额外加密。
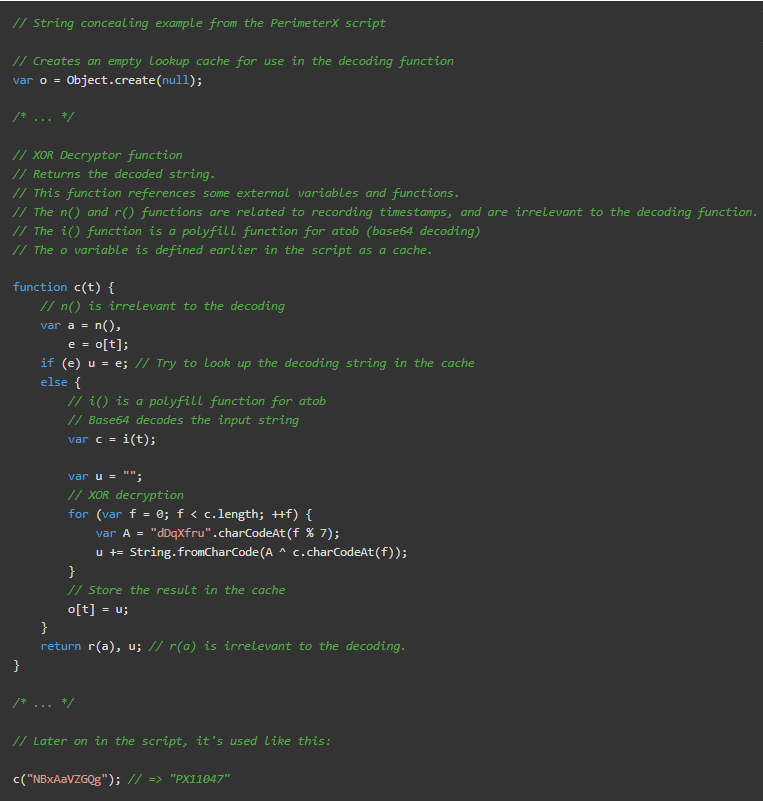
代理变量/函数。这种技术用一个中间变量代替了对一个变量/函数标识符的直接引用。
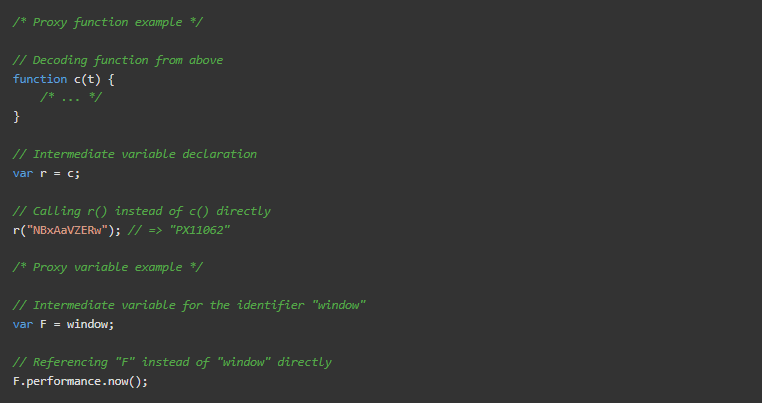
单项表达式。这种技术不是直接使用布尔字面或未定义关键字,而是利用了JavaScript的单数表达式实现的自动类型转换行为。

尽管PerimeterX挑战脚本的混淆功能可能不像其他机器人检测供应商那样复杂,但它仍然需要专门的反向工程技能来将其转换为可读状态。简单地把它粘贴到一般的JavaScript去混淆器中,不会产生容易理解的代码。
要对 PerimeterX 脚本进行解密,你需要创建一个自定义的解密器。这一步可能比较困难,但它对创建PerimeterX的绕过是至关重要的
提示:尝试使用抽象语法树(AST)进行操作。
一旦你对 PerimeterX 的挑战脚本进行了解密,你就可以通过阅读它来确定进行了哪些机器人检测检查,以及如何复制解决挑战的行为。在接下来的步骤中,我们将对去模糊化的脚本进行研究,并尝试提取其内部的关键信息。
第3步:分析去模糊化的PerimeterX脚本
让我们先弄清楚有效载荷是如何被加密的!
PerimeterX的有效载荷加密
为了弄清有效载荷是如何加密的,以便我们能够编写我们的自定义 PerimeterX 绕过,我们要向后努力。首先,我们通过搜索去模糊化脚本中的"payload="字符串,找到它的设置位置。

看一下N的定义,我们可以确定Wc函数负责对有效载荷进行加密。Wc接收了两个参数。
n:一个存储原始有效载荷数据的JavaScript对象。B:一个JavaScript对象,存储一些在加密过程中作为密钥使用的值。
让我们查一下Wc的定义。
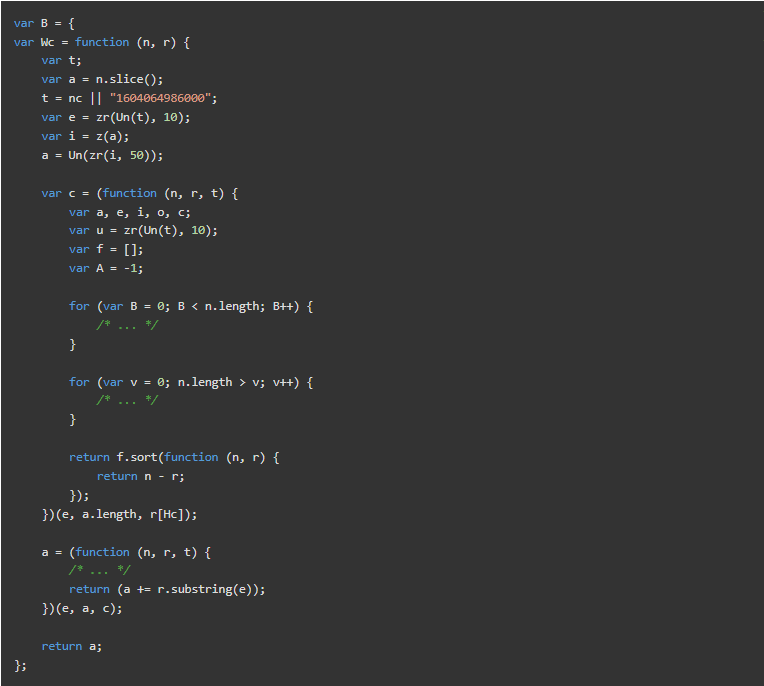
这就是PerimeterX的加密密码。原始函数相当长,而且引用了许多外部变量/函数。为了实用起见,我们把它截断了。
然而,通过查看完全解密的 PerimeterX 脚本,你可以了解到这个密码的一些重要内容。
- 有效载荷使用两个加密密钥:
uuid和sts的值。 uuid出现在每个POST请求中,而ts出现在第2个POST请求之后。在第1个POST请求中,没有sts,"1604064986000 "被用来代替它。- 这是一种对称密钥的算法。因此,只要你有原始的
sts和uuid值,你就可以解密任何加密的 PerimeterX 有效载荷。这对于分析你的浏览器发送的有效载荷是很有用的,因为密钥总是和加密的内容一起在POST请求中发送。
PerimeterX如何设置Cookies
我们之前的结论是,所有与PerimeterX相关的cookie都是由实际的脚本本身设置的。记得_px2cookie的原始值第一次出现在JSON格式的响应体中(如<jwt>)。

字段名do,实际上变成了相当的字面意思。Do的对应值实际上是一个指令数组。每个字符串都被分割成一个数组。对于do数组中的第一个字符串,看起来像这样。

结果数组的第一个元素决定了要执行的函数,而其余的元素则作为函数的参数。在这种情况下,bake是要执行的函数的名称。
在去模糊化的 PerimeterX 脚本中搜索bake,我们发现了cu对象。这个cu对象保存了bake指令的处理程序。
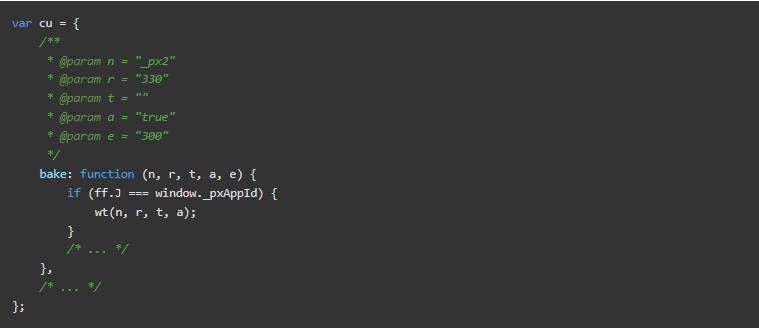
参数n、r、t、a和e的值分别为"_px2"、"330"、"<jwt>"、"true "和"300"。
烘烤方法调用了一个函数wt,我们也来看看它的定义。

所以,看起来 烘烤指令直接设置了_px2cookie!这也是一种文字游戏,就像烘烤饼干一样。
祝贺你!你在代码中找到了他们的主要反机器人cookie的设置位置。下一步将是为它计算出对PerimeterX有意义的值,这样你的机器人就不会被标记为可疑的。
你应该注意到,cu对象也包含所有其他可能的do指令的处理程序。为了创建一个PerimeterX绕过,你需要对每个do指令的功能进行反向工程。
让我们来学习如何破解你可能在这个do数组里面发现的一些安全检查。
WebGL指纹识别
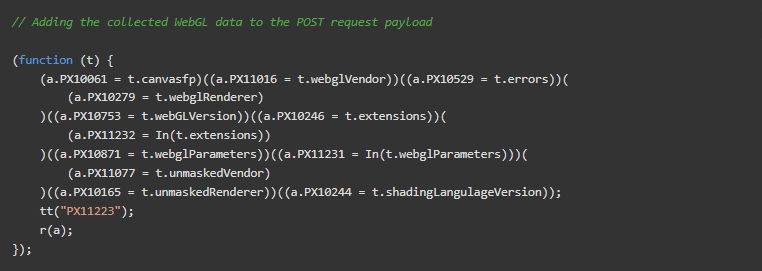
在下面的片段中,PerimeterX使用WebGLAPIs来创建和渲染图像。然后,该图像的哈希值被存储在canvasfp中。

这对指纹识别很有用,因为即使被指示绘制完全相同的图像,硬件或低级软件(即操作系统)的轻微变化也会产生不同的输出(从而产生不同的哈希值)。这使得WebGL指纹识别成为对设备进行分类的好方法。
PerimeterX还收集了其他各种WebGL属性,以更好地对你的设备进行分类。利用机器学习,他们可以利用这些数据来检测你是否在欺骗WebGL属性/渲染。
计算出的canvasfp以及额外的WebGL属性被添加到下面这个片段的payload对象中。
自动浏览器检查
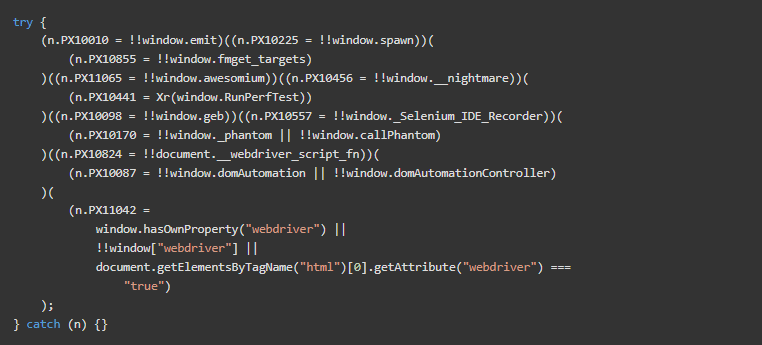
下面,PerimeterX正在检查是否存在自动化浏览器的特定属性。
沙箱检查
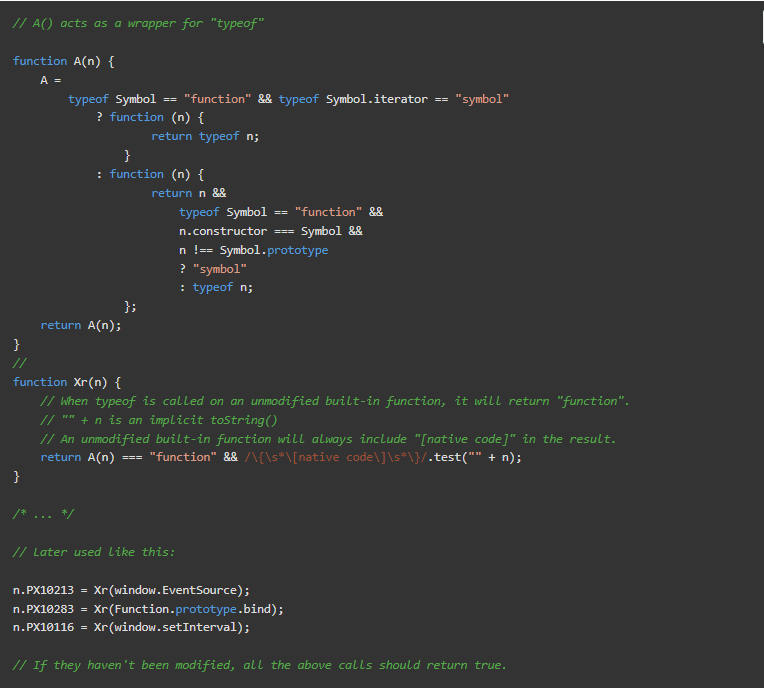
PerimeterX检查是否存在仅针对NodeJS的API,以确定脚本是否被沙盒化。

为了确保内置函数没有被修改(即monkey-patched),PerimeterX对它们调用typeof和隐式toString。
用户输入事件跟踪
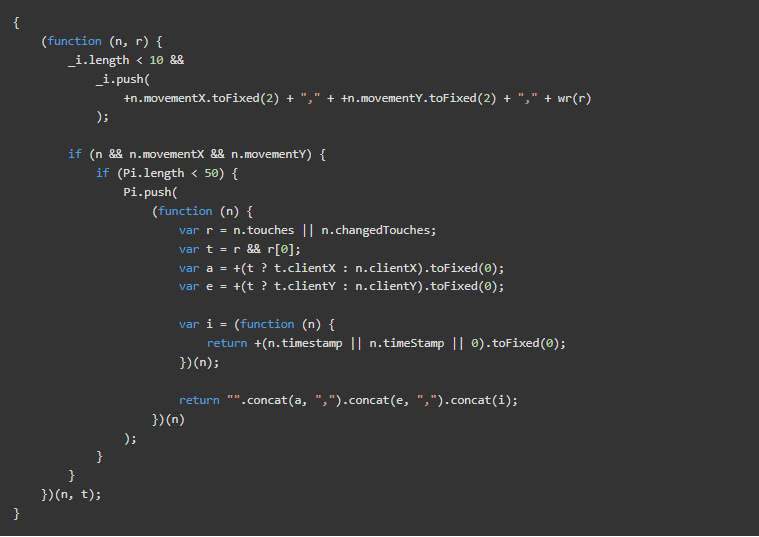
PerimeterX收集行为生物识别数据,如鼠标动作、键盘按压和触摸动作。然后可以用机器学习来分析所收集的数据,以确定这些输入是类似人类的,还是由机器人产生的。
在这个片段中,PerimeterX跟踪触摸事件的时间和位置。
绕过PerimeterX的简单方法
在这一点上,也许你在想 “难道就没有任何现有的PerimeterX绕过方法可以用吗?”。残酷的现实是,在2023年,使用公共软件绕过PerimeterX反机器人服务是非常困难的,比如你可以在GitHub上找到的库(不过,你可以查看其中一些,如Puppeteer Stealth)。此外,基于Chrome、Chromium、Firefox或Selenium的标准无头浏览器可能需要非常特殊的配置才能工作。
由于该软件的源代码是公开的,PerimeterX的开发者可以更新他们的反机器人系统来检测它。一种选择是编写你自己的PerimeterX绕过,尽管对付他们的反机器人保护的最简单方法是使用旨在绕过PermiterX的私人软件。
如果你想要一个高效的绕过PerimeterX的私有软件,可以考虑使用以下代理服务器:
总 结
正如你所看到的,要绕过PerimeterX的JavaScript挑战,你需要对JavaScript脚本进行解密,然后仔细计算该脚本所有不同类型的检查的正确值。
- 输入事件跟踪,如鼠标事件。
- 沙箱(NodeJS、Python等)。
- 自动浏览器,如Chrome Headless或Selenium检查。
- WebGL指纹与他们的机器学习算法相结合。
- 具有正确值的Cookies。
请记住,在你欺骗了PerimeterX(现在的HUMAN)Bot Defender一次后,你的工作并没有完全完成。有必要经常检查你的爬虫,因为如果PerimeterX更新了它的脚本,你的自定义绕过方式就会被发现并被阻止。

