

在这篇文章中,你将研究如何在代理服务器后面使用Python Requests库。开发人员使用代理服务器是为了匿名、安全,有时甚至会使用多个代理服务器来防止网站禁止他们的 IP 地址。代理服务器还具有其他一些好处,如绕过过滤器和审查制度。
先决条件和安装
这篇文章是为那些想用Python在代理后面进行爬取的人准备的。为了获得材料的大部分内容,以下内容是有益的。
- 有Python 3的经验.
- 在你的本地机器上安装了Python 3。
通过打开终端并键入,检查Python-requestspacakges是否已经安装。
$ pip freeze
pip freeze会显示你当前所有的python软件包和它们的版本,所以继续检查它是否存在。如果没有,通过运行来安装它。
$ pip install requests
如何在Python请求中使用代理服务器
要在Python中使用代理,首先要导入
request包。接下来创建一个
proxies字典,定义HTTP和HTTPS连接。这个变量应该是一个字典,将协议映射到代理的URL。此外,做一个url变量,设置为你要爬取的网页。
注意在下面的例子中,字典定义了两个独立协议的代理URL。HTTP 和 HTTPS。每个连接都映射到一个单独的 URL 和端口,但这并不意味着这两者不能相同
- 最后,创建一个
响应变量,使用任何一个请求方法。该方法将接收两个参数:你创建的URL变量和定义的字典。
你可以对不同的api调用使用相同的语法,但无论你做什么调用,你都需要指定协议。
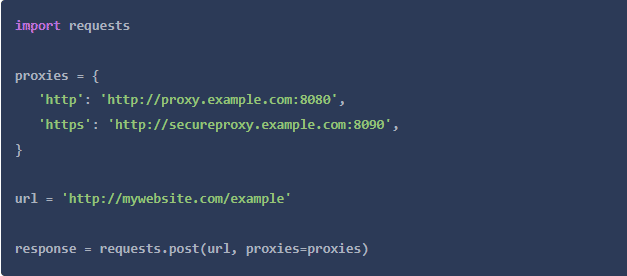
请求方式
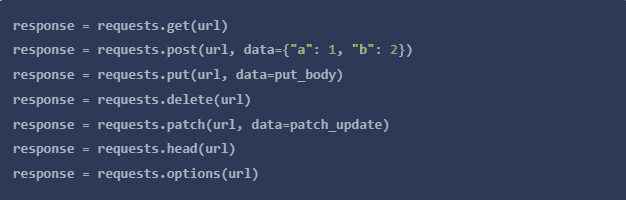
代理认证
如果你需要添加认证,你可以使用以下语法重写你的代码。

代理会话
你也可能发现自己想从利用会话的网站上进行爬取,在这种情况下,你必须创建一个会话对象。你可以这样做,首先创建一个会话变量,并将其设置到requestSession()方法中。然后,与之前类似,你将通过request方法发送你的会话代理,但这次只传入url作为参数。
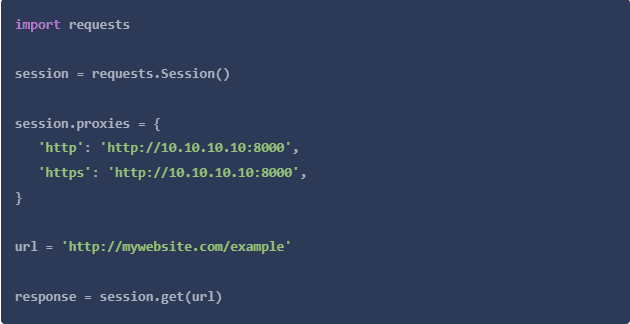
环境变量
你可能会发现自己在每个请求中重复使用相同的代理,所以请随意通过设置一些环境变量来使你的代码更加干燥。

如果你决定设置环境变量,就不再需要在你的代码中设置代理。只要你提出请求,就会有一个api调用!
阅读响应
如果你想读取你的数据。

JSON:对于JSON格式的响应,requests包提供了一个内置方法。

用请求Requests代理
还记得我们说过一些开发者使用不止一个代理吗?那么,现在你也可以了!
任何时候你发现自己反复从一个网页上爬取,使用一个以上的代理是很好的做法,因为很有可能你的爬取器会被封锁,这意味着你的IP地址会被禁止。铲除文化是真实的!所以,为了避免被取消,最好是利用轮流代理。旋转代理是一个代理服务器,为每个连接从代理池中分配一个新的IP地址。
要轮换IP地址,你首先需要有一个可用的IP池。你可以使用互联网上的免费代理或商业解决方案。在大多数情况下,如果你的服务依赖于爬取的数据,免费代理很可能是不够的。
如何用Requests轮换IP
为了开始轮换你的IP地址,你需要一个免费代理服务器的列表。如果免费代理服务器确实符合你的爬取需求,在这里你可以找到一个免费代理服务器的列表。今天你将编写一个脚本,选择并轮换代理服务器。
首先导入
request、BeautifulSoup和choice库。接下来定义一个方法
get_proxy(),它将负责检索IP地址供你使用。在这个方法中,你将定义你的url作为你选择使用的任何代理列表资源。在发送请求api调用后,将响应转换为Beautiful Soup对象,以使提取更容易。使用html5lib解析器库来解析网站的HTML,就像你对浏览器那样。创建一个代理变量,使用选择从soup生成的代理列表中随机选择一个IP地址。在map函数中,你可以使用一个lambda函数将HTML元素转换为检索到的IP地址和端口号的文本。创建一个
proxy_request方法,接收3个参数:request_type、url和**kwargs。在这个方法中,将你的代理字典定义为从get_proxy方法返回的代理。与之前类似,你将使用请求,传入你的参数。
import requests
ip_addresses = [ "mysuperproxy.com:5000", "mysuperproxy.com:5001", "mysuperproxy.com:5100", "mysuperproxy.com:5010", "mysuperproxy.com:5050", "mysuperproxy.com:8080", "mysuperproxy.com:8001",
"mysuperproxy.com:8000", "mysuperproxy.com:8050" ]
def proxy_request(request_type, url, **kwargs):
while True:
try:
proxy = random.randint(0, len(ip_addresses) - 1)
proxies = {"http": ip_addresses(proxy), "https": ip_addresses(proxy)}
response = requests.get(request_type, url, proxies=proxies, timeout=5, **kwargs)
print(f"Proxy currently being used: {proxy['https']}")
break
except:
print("Error, looking for another proxy")
return response[文中代码源自Scrapingbee]
总 结
虽然你可能很想马上用你看中的新代理服务器开始爬取,但仍有一些关键的事情你应该知道。首先,不是所有的代理都是一样的。实际上有不同的类型,主要有三种:透明代理、匿名代理和精英代理。
在大多数情况下,你会使用精英代理,无论是付费还是免费,因为他们是避免被发现的最佳解决方案。如果使用代理的唯一目的是隐私,匿名代理可能值得你去做。不建议使用透明代理,除非有特殊原因,因为透明代理会暴露您的真实IP地址和您正在使用代理服务器。
现在我们把这些都弄清楚了,是时候开始用Python中的代理进行爬取了。所以,赶快出去,提出你能想到的所有请求吧!

