

在许多情况下,如自动化、数据科学、数据工程、自动化和应用开发,Python是通用语言。它通常用于下载图片和网页,有多种方法和软件包可供选择。一种简单而强大的方法是与Wget对接。
Wget是一个有25年历史的免费命令行程序,可以通过HTTP、HTTPS和FTP从网络服务中检索文件。如果你把它和Python一起使用,你几乎可以不受限制地从网上下载和搜刮什么。
这篇文章将通过一些简单的例子向你展示用Python使用Wget的好处。你还会了解到Wget的局限性和替代方案。
为什么使用Wget?
Wget是一个方便和广泛支持的工具,用于通过三种协议下载文件:HTTP、HTTPS和FTP。Wget的流行归功于它的两个主要特点:递归性和健壮性。
递归性:使用适当的参数,Wget可以作为一个网络爬虫来操作。它不是下载单个文件,而是递归地下载从特定网页链接的文件,直到所有的链接都被用完或达到用户指定的递归深度。在这种情况下,Wget将下载的文件保存在一个类似于它们被下载的服务器的目录结构中。这个功能是高度可配置的。
- 支持网络位置和文件名中的通配符
- 提供时间戳检查,因此只有新的或更新的文件被下载。
- 尊重机器人的排除标准
稳健性:Wget可以从中断的传输中恢复,使其成为在不稳定或缓慢的网络上下载文件的良好解决方案。Wget使用RangeHTTP Header继续下载,直到收到整个文件。这不需要用户的干预。
Wget2是在2021年发布的。虽然它支持或多或少相同的功能,但它专注于并行化,使其比前者快得多。
为什么使用Python的Wget?
Python是一种通用的编程语言,用于金融、学术界、云/数据工程、数据科学、网络开发和工作流程自动化。它不仅广泛用于各种领域和部门,而且拥有一个巨大的社区,是通过谷歌搜索最多的编程语言,并在职位空缺中名列最受欢迎的编程语言。
使用Wget,你可以轻松地将Python脚本变成成熟的网络抓取解决方案。一些有趣的用例是。
- 为学术和商业目标创建数据集。通过Wget,可以很容易地刮取一个或多个网站的内容。这些大型数据集对机器学习研究至关重要。例如,如果没有数十亿的内容,最近的NLP模型是不可能的。
- 监测大型网站。自动Wget检查网页和文件是否可以从世界各地的不同网络和地方获得。
- 内容映射。很多网页都会产生个性化的内容。通过设置Wget以表现为不同的角色,你可以创建一个概览,了解哪些内容显示给哪些用户。
虽然有多种方法可以在Python中运行shell命令和程序(如Wget),但在本教程中你将使用subprocess包与操作系统的shell接口。
请注意,尽管Python wget包共享一些功能,但它与Wget命令行程序没有关系。它是一个未完成的包,已经多年没有更新了,并且缺乏Wget的大部分显著特征。
在Python中使用Wget
接下来,你将在Python中设置Wget来下载文件。
首要条件
首先,确保你的机器上安装了Wget。这个过程因你的操作系统不同而不同。
- 如果你使用的是Linux,你可能已经预装了它。
- 如果你使用Mac,安装Wget的最简单方法是使用Homebrew。
- Windows用户可以从这个网站下载Wget命令行工具的可执行文件。一旦下载完毕,确保它被添加到PATH变量中。
用子进程包运行命令
为了从Python脚本中运行Wget命令,你将使用子进程包的Popen方法。每次你的脚本调用popen(),它将在操作系统的命令处理器的一个独立实例中执行你传递的命令。通过设置verbose参数为True,它还会返回命令的输出。请根据你的需要自由调整。
所有的代码片断都可以在这个文件中找到。
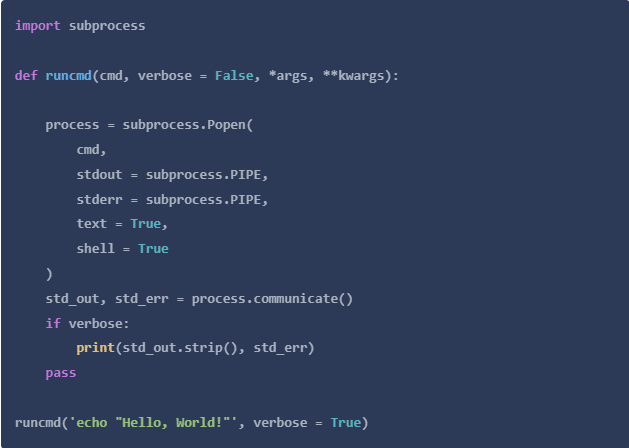
本节中你将使用的命令都是以同样的方式组织的。你将使用wget命令,给它一个URL,并提供特定的选项来实现某些目标。

在广泛的手册中检查你的选项。
下载一个文件。要从服务器上下载一个文件,把wget命令和文件的URL传给你创建的自定义函数。将verbose设置为True。
runcmd("wget https://www.scrapingbee.com/images/logo-small.png", verbose = True)从该命令的输出中,你可以观察到(1)URL被解析为服务器的IP地址,(2)发送了一个HTTP请求,(3)收到状态码200 OK。最后(4),Wget将文件存储在脚本运行的目录中,而不改变文件名。
下载一个文件到一个自定义文件夹。要下载一个文件到一个特定的文件夹,可以传递给它–目录前缀或–P标志,然后是目标文件夹。有趣的是,当文件夹的路径不存在时,Wget会创建它。
runcmd("wget --directory-prefix=download_folder https://www.scrapingbee.com/images/logo-small.png", verbose = False)
runcmd("wget -P download_folder https://www.scrapingbee.com/images/logo-small.png", verbose = False)将文件下载到一个特定的文件名:你不仅可以改变一个文件的目标文件夹,而且可以指定其本地文件名。向它提供–输出文件或–O标志,然后是所需的文件名。
runcmd("wget -O logo.png https://www.scrapingbee.com/images/logo-small.png")
runcmd("wget --output-document=logo.png https://www.scrapingbee.com/images/logo-small.png")下载一个文件的较新版本。有时你只想下载一个文件,如果本地的拷贝比服务器的版本要老。你可以通过提供–时间戳选项来打开这个功能。
runcmd("wget --timestamping https://www.scrapingbee.com/images/logo-small.png", verbose = True)如果你已经下载了ScrapingBee的标志,你很可能会看到,在这个例子中,服务器响应的状态代码是304未修改的。换句话说,服务器上的文件与你本地机器上的文件是同一个版本,所以不会有文件被下载。
完成未完成的下载。Wget的默认行为是,如果中途失去连接,会重试下载一个文件。然而,如果你想继续获得部分下载的文件,你可以设置-c或-continue选项。

递归检索。Wget最令人兴奋的功能是递归检索。Wget可以通过HTMLsrc和href属性或CSSurl()功能符号检索和解析给定URL上的页面以及初始文件所指向的文件。如果下一个文件也是文本/HTML,它将被解析并进一步跟踪,直到达到所需的深度。递归检索是广度优先的:它将下载深度1上的文件,然后是深度2,等等。
有很多选项你可以设置。
-r或--recursive选项将启用递归检索。-l或--level选项允许你设置深度,即Wget可以追索的子目录的数量。为了防止抓取巨大的网站,Wget设置的默认深度为5/。把这个选项改为零(0)或"inf",以获得无限的深度。如果你想确保所有必要的资源(图片、CSS、JavaScript)都被加载以正确显示一个页面,即使这些资源没有所需的最大深度,你可以设置-p或-page-requisites选项。-k或-convert-links选项将转换下载文件中的链接,使其适合于本地查看。已下载的文件将被相对提及(例如,./foo/bar.png)。没有被下载的文件将以其主机名提及
以下命令将递归地下载scrapingbee.com网站到一个www.scrapingbee.com,最大深度为3/。Wget还将转换所有链接,使这个副本在本地可用。
runcmd('wget --recursive --level=3 --convert-links https://www.scrapingbee.com')
[文中代码源自Scrapingbee]这个命令可能需要几分钟以上的时间才能完成,这取决于你的互联网连接速度。
什么时候不使用Wget
如果你专注于从网络服务器递归下载文件,Wget是一个优秀的解决方案。然而,由于这种狭窄的关注点,它的使用情况是有限的,替代方案值得考虑。
- 要通过HTTP(S)或FTP(S)以外的协议下载文件。
- 如果你只需要刮取网页上的某些DOM元素而不把文件存储在本地,可以考虑与[Beautiful Soup]相结合的请求。
- Selenium是模拟网站上的点击和滚动行为的绝佳解决方案(例如,用于测试目的)。
总 结
Wget是一个通过HTTP和FTP协议下载文件的便捷解决方案。它在递归下载多个文件方面与Python配合得很好,而且这个过程可以很容易地自动化,以节省你的时间。
Wget的重点可能有些局限,但它为你的下载和网络抓取需求提供了大量的选择。

