

网页爬取是一种常见的在线收集数据的技术,其中HTTP客户端在处理用户对数据的请求时,使用HTML分析器来梳理这些数据。它帮助程序员更容易获得他们的项目所需的信息。
网页爬取有许多用例。它允许你访问可能无法从API获得的数据,以及来自几个不同来源的数据。它还可以帮助你汇总和分析与产品有关的用户意见,它还可以提供对市场状况的洞察力,如定价波动或分销问题。然而,爬取这些数据或将其整合到你的项目中并不总是那么容易。
幸运的是,网页爬取已经变得更加先进,许多编程语言都支持它,包括C++。这种流行的系统编程语言还提供了许多使其对网页爬取有用的功能,如速度、严格的静态类型,以及一个标准库,其产品包括类型推理、通用编程的模板、并发的基元和lambda函数。
在本教程中,你将学习如何使用C++来实现libcurl和gumbo库的网络抓取。你可以在GitHub上跟随学习。
首要条件
在本教程中,你将需要以下内容。
- 对HTTP的基本了解
- 你的机器上安装了C++ 11或更新版本
- g++ 4.8.1或更新版本
libcurl和gumboC库- 有数据的资源,可供爬取(你将使用Merriam-Webster网站)。
关于网页爬取
对于客户端(如浏览器)提出的每一个HTTP请求,服务器都会发出一个响应。请求和响应都伴随着标头,标头描述了客户打算接收的数据的各个方面,并为服务器解释所发送数据的所有细微差别。
例如,假设你使用cURL作为客户端,向Merriam-Webster的网站提出了关于 “深奥 “一词的定义的请求。
GET /dictionary/esoteric HTTP/2 Host: www.merriam-webster.com user-agent: curl/7.68.0 accept: */*
Merriam-Webster网站会用头信息来识别自己的服务器,用HTTP响应代码来表示成功(200),用内容类型头信息来表示响应数据的格式–这里是HTML,用缓存指令,以及额外的CDN元数据。它可能看起来像这样。
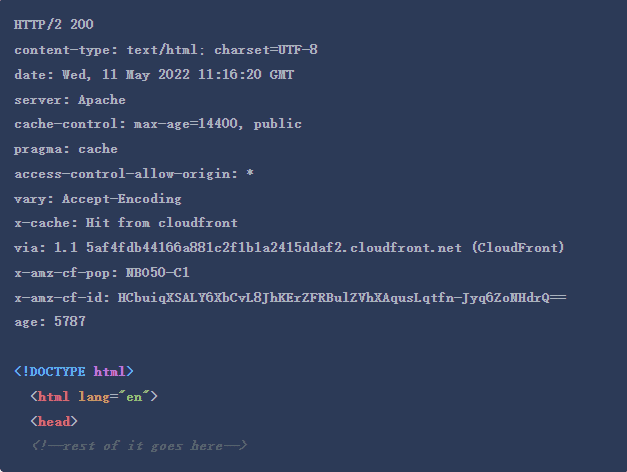
在你建立你的爬取器之后,你应该得到类似的结果。本教程中你将使用的两个库之一是libcurl,cURL是在它的基础上编写的。
构建网络爬取器
你将在C++中建立的爬取器将从Merriam-Webster网站上获取单词的定义,同时消除与传统单词搜索相关的许多输入。相反,你将把这个过程减少到一组按键。
在本教程中,你将在一个标记为scraper的目录中工作,并有一个同名的单一C++文件:scraper.cc。
设置Libraries
你要使用的两个C语言库,libcurl和gumbo,在这里起作用,因为C++与C语言互动良好。libcurl是一个API,可以实现一些URL和HTTP相关的功能,并为上一节中使用的同名客户端提供动力,gumbo是一个轻量级的HTML-5解析器,与几种C语言兼容的语言绑定。
使用vcpkg
vcpkg由微软开发,是一个用于C/C++项目的跨平台软件包管理器。按照这个指南在你的机器上设置vcpkg。你可以通过在控制台输入以下内容来安装libcurl和
$ vcpkg install curl $ vcpkg install gumbo
如果你在IDE环境中工作–特别是Visual Studio Code–那么请在你的项目根目录下运行下面的片段,以便整合这些软件包。
$ vcpkg integrate install
为了尽量减少安装中的错误,可以考虑将
vcpkg加入你的环境变量。
使用apt
如果你使用过Linux,你应该对apt很熟悉,它能让你方便地对平台上安装的库进行源代码和管理。要用apt安装libcurl和gumbo,在你的控制台输入以下内容。
$ sudo apt install libcurl4-openssl-dev libgumbo-dev
安装Libraries
与其通过手动安装,你可以使用下面所示的方法。
首先,clone curl仓库并全局安装。
$ git clone https://github.com/curl/curl.git $ cd $ autoreconf -fi $ ./configure $ make
接下来,clone gumbo仓库并安装该软件包。
$ sudo apt install libtool $ git clone https://github.com/google/gumbo-parser.git $ cd $ ./autogen.sh $ ./configure $ make && sudo make install
爬虫的编码
编写爬取器的第一步是创建一个用于发出HTTP请求的工具。这个工件–一个函数,名为request–将允许字典爬取工具从Merriam-Webster网站上获取标记。
在你的scraper.cc文件中的请求函数中,在下面的代码片段中,定义了不可改变的基元–通过user-agent头识别scraper的客户端名称,以及将服务器响应标记写入内存的语言工件。唯一的参数是构成URL路径的一部分的词,其定义是由爬取者提供的。
typedef size_t( * curl_write)(char * , size_t, size_t, std::string * );
std::string request(std::string word) {
CURLcode res_code = CURLE_FAILED_INIT;
CURL * curl = curl_easy_init();
std::string result;
std::string url = "https://www.merriam-webster.com/dictionary/" + word;
curl_global_init(CURL_GLOBAL_ALL);
if (curl) {
curl_easy_setopt(curl,
CURLOPT_WRITEFUNCTION,
static_cast < curl_write > ([](char * contents, size_t size,
size_t nmemb, std::string * data) -> size_t {
size_t new_size = size * nmemb;
if (data == NULL) {
return 0;
}
data -> append(contents, new_size);
return new_size;
}));
curl_easy_setopt(curl, CURLOPT_WRITEDATA, & result);
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_USERAGENT, "simple scraper");
res_code = curl_easy_perform(curl);
if (res_code != CURLE_OK) {
return curl_easy_strerror(res_code);
}
curl_easy_cleanup(curl);
}
curl_global_cleanup();
return result;
}记得在你的.cc或.cpp文件的序言中为curl库和C++字符串库包含适当的头文件。这将避免库连接的编译问题。
#include “curl/curl.h” #include “string”
下一步,解析标记,需要四个函数:scrape,find_definitions,extract_text, andstr_replace。由于gumbo是所有标记解析的核心,因此添加适当的库头,如下所示。
#include “gumbo.h”
scrape函数将请求中的标记送入find_definitions,以便有选择地迭代DOM遍历。你将在这个函数中使用gumbo解析器,它返回一个包含单词定义列表的字符串。
std::string scrape(std::string markup)
{
std::string res = "";
GumboOutput *output = gumbo_parse_with_options(&kGumboDefaultOptions, markup.data(), markup.length());
res += find_definitions(output->root);
gumbo_destroy_output(&kGumboDefaultOptions, output);
return res;
}下面的find_definitions函数递归地从spanHTML 元素中收获定义,其唯一的类标识符为"dtText"。它通过extract_text函数在每次成功的迭代中从每个HTML节点中提取定义文本,该文本被包含在其中。
std::string find_definitions(GumboNode *node)
{
std::string res = "";
GumboAttribute *attr;
if (node->type != GUMBO_NODE_ELEMENT)
{
return res;
}
if ((attr = gumbo_get_attribute(&node->v.element.attributes, "class")) &&
strstr(attr->value, "dtText") != NULL)
{
res += extract_text(node);
res += "\n";
}
GumboVector *children = &node->v.element.children;
for (int i = 0; i < children->length; ++i)
{
res += find_definitions(static_cast(children->data[i]));
}
return res;
}接下来,下面的extract_text函数从每个节点中提取不是脚本或样式标签的文本。该函数将文本输送到str_replace例程,该例程将前面的冒号替换为二进制的>符号。
std::string extract_text(GumboNode *node)
{
if (node->type == GUMBO_NODE_TEXT)
{
return std::string(node->v.text.text);
}
else if (node->type == GUMBO_NODE_ELEMENT &&
node->v.element.tag != GUMBO_TAG_SCRIPT &&
node->v.element.tag != GUMBO_TAG_STYLE)
{
std::string contents = "";
GumboVector *children = &node->v.element.children;
for (unsigned int i = 0; i < children->length; ++i)
{
std::string text = extract_text((GumboNode *)children->data[i]);
if (i != 0 && !text.empty())
{
contents.append("");
}
contents.append(str_replace(":", ">", text));
}
return contents;
}
else
{
return "";
}
}str_replace函数(受到一个同名的PHP函数的启发)用另一个字符串替换一个大字符串中指定的搜索字符串的每个实例。它显示如下。
std::string str_replace(std::string search, std::string replace, std::string &subject)
{
size_t count;
for (std::string::size_type pos{};
subject.npos != (pos = subject.find(search.data(), pos, search.length()));
pos += replace.length(), ++count)
{
subject.replace(pos, search.length(), replace.data(), replace.length());
}
return subject;
}由于上述函数中的遍历和替换依赖于算法库中定义的基元,所以你也需要包含该库。
#include ”algorithm”
接下来,你将为爬取器增加活力–使其能够返回作为命令行参数的每个单词的定义。为了做到这一点,你将定义一个函数,将每个命令行参数转换为小写的等价物,将重定向产生的请求错误的可能性降到最低,并将输入限制为一个命令行参数。
增加了将字符串输入转换为小写等价物的功能。
std::string strtolower(std::string str)
{
std::transform(str.begin(), str.end(), str.begin(), ::tolower);
return str;
}接下来是有选择地解析单个命令行参数的分支逻辑。
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}你的爬取器中的主要功能应该出现如下图所示。
int main(int argc, char **argv)
{
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}
std::string arg = argv[1];
std::string res = request(arg);
std::cout << scrape(res) << std::endl;
return EXIT_SUCCESS;
}你应该包括C++的iostream库,以确保主函数中定义的输入/输出(IO)基元能按预期工作。
#include “iostream”
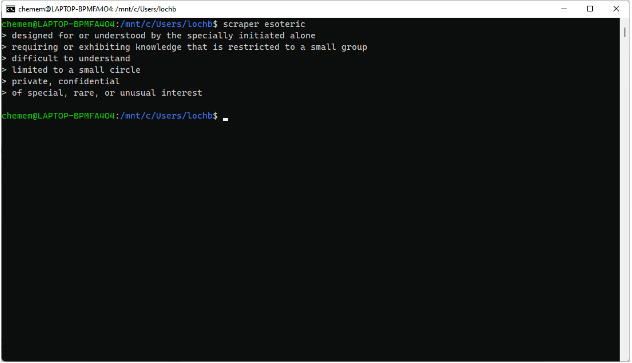
要运行你的爬取器,用g++编译它。在你的控制台中输入以下内容来编译和运行你的爬取器。它应该拉出 “esoteric “这个词的六个列出的定义。
$ g++ scraper.cc -lcurl -lgumbo -std=c++11 -o scraper $ ./scraper esoteric
你应该看到以下内容:
总 结
正如你在本教程中所看到的,通常用于系统编程的C++,由于其能够解析HTTP,因此也能很好地用于网页爬取。这种新增的功能可以帮助你扩展你的C++知识。
你会注意到,这个例子相对简单,并没有解决如何对一个更多的JavaScript重的网站进行爬取,例如使用Selenium的网站。要在一个动态渲染的网站上进行爬取,你可以使用一个无头浏览器和一个用于Selenium的C++库。
要检查你在这个教程上的工作,请参考这个GitHub gist。

