

PHP和Web爬取有很多共同点:就像PHP一样,Web爬取既可以用快速和肮脏的方式,也可以用更精细的方式,并在其他工具和服务的帮助下支持。
在这篇文章中,我们将看一下用PHP爬取网页的一些方法。请记住,没有什么 “最好的方法”–每一种方法都有它的用途,取决于你需要什么,你喜欢怎么做,以及你想实现什么。
作为一个例子,我们将尝试得到一个有相同生日的人的列表,例如,你可以在famousbirthdays.com 上看到。如果你想一起编码,请确保你已经安装了当前版本的PHP和Composer。
创建一个新的目录,并在其中运行以下命令。
$ composer init --require="php >= 8.1" --no-interaction $ composer update
1.HTTP请求
当涉及到浏览网络时,你需要熟悉的一个重要通信协议是HTTP,即超文本传输协议。它定义了万维网上的参与者如何相互沟通。有服务器托管资源,有客户向其请求资源。
你的浏览器就是这样一个客户端,当我们打开开发者控制台(按F12),选择 “网络 “标签并打开著名的example.com,我们可以看到发送到服务器的完整请求,以及完整的响应。
这是相当多的请求和响应头,但在其最基本的形式下,一个请求看起来像这样。
GET / HTTP/1.1 Host: www.example.com
让我们试着用PHP来重现浏览器刚刚为我们做的事情吧!
fsockopen()
通常情况下,我们不会使用很多这样的 “低级 “通信,但只是为了这个目的,让我们用PHP所提供的最基本的工具fsockopen()来创建这个请求。
<?php
# fsockopen.php
// HTTP requires "\r\n" In HTTP, lines have to be terminated with "\r\n" because of
$request = "GET / HTTP/1.1\r\n";
$request .= "Host: www.example.com\r\n";
$request .= "\r\n"; // We need to add a last new line after the last header
// We open a connection to www.example.com on the port 80
$connection = fsockopen('www.example.com', 80);
// The information stream can flow, and we can write and read from it
fwrite($connection, $request);
// As long as the server returns something to us...
while(!feof($connection)) {
// ... print what the server sent us
echo fgets($connection);
}
// Finally, close the connection
fclose($connection);而事实上,如果你把这段代码放到文件fsockopen.php中,然后用php fsockopen.php运行它,你会看到与你在浏览器中打开http://example.com时一样的HTML。
说实在的:fsockopen()通常不是用来在PHP中执行HTTP请求的;我只是想用最简单的例子告诉你这是可能的。虽然可以用它来处理HTTP任务,但这并不有趣,而且需要很多我们不需要写的模板代码–执行HTTP请求是一个已经解决的问题,在PHP中(以及其他很多语言),它是通过以下方式解决的
cURL
输入cURL(一个URL的客户端)!
让我们直接跳到代码中,它是非常直接的。
<?php # curl.php // Initialize a connection with cURL (ch = cURL handle, or "channel") $ch = curl_init(); // Set the URL curl_setopt($ch, CURLOPT_URL, 'http://www.example.com'); // Set the HTTP method curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET'); // Return the response instead of printing it out curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Send the request and store the result in $response $response = curl_exec($ch); echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL; echo 'Response Body: ' . $response . PHP_EOL; // Close cURL resource to free up system resources curl_close($ch);
现在,这看起来已经没有我们之前的例子那么低级了,不是吗?不需要手动编写HTTP请求,建立和管理TCP连接,或者逐个处理响应。相反,我们只需要初始化cURL句柄,传递实际的URL,并使用curl_exec来执行请求。
例如,如果我们想让cURL自动处理HTTP重定向30x代码,我们只需要添加curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);。此外,还有一些额外的选项和标志来支持其他的使用情况。
很好!现在让我们开始实际的爬取工作吧!
2.字符串、正则表达式和维基百科
让我们看看维基百科作为我们的第一个数据提供者。一年中的每一天都有自己的历史事件页面,包括生日例如,当我们打开12月10日的页面时,我们可以在开发者控制台中检查HTML,看看 “出生 “部分是如何结构的。
这看起来很好,很有条理!我们可以看到,
- 有一个
<h2>标题元素,包含<span id="Births" ...>Births</span>(整个页面上只有一个元素应该有一个名为 “Births “的ID)。 - 下面,是各个纪元的小标题
(<h3>)及其列表条目元素(<ul>)的列表。 - 每个列表条目由
<li>项表示,包含年份、破折号、人名、逗号,以及该人以什么闻名的预告。
这是我们可以利用的东西,不是吗?我们走吧!
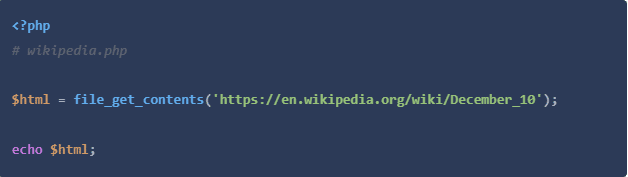
等等什么?惊喜吧!是的,file_get_contents()利用了PHP的fopen包装器,(只要它们被启用)可以用来获取HTTP URL。尽管它主要是针对本地文件的,但它可能是执行基本的HTTP GET请求的最简单和最快速的方法,对于我们这里的例子或快速的一次性脚本来说,只要你小心使用它就可以。
你读过脚本打印出来的所有HTML吗?我希望没有,因为它有很多重要的是,我们知道我们应该从哪里开始找:我们只对以id="Births "开始,在下一个<h2>之前结束的部分感兴趣。
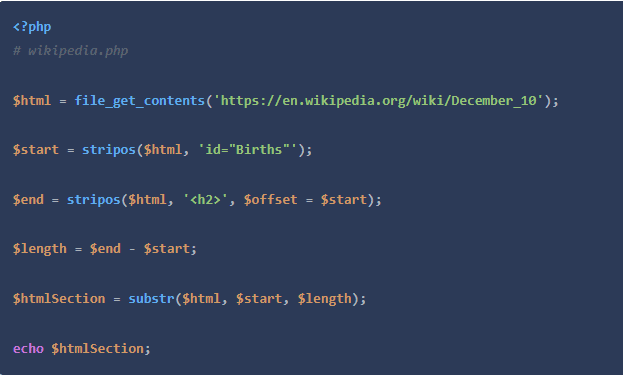
这不再是有效的HTML了,但至少我们可以看到我们正在处理的内容让我们使用正则表达式将所有的列表项加载到一个数组中,这样我们就可以逐一处理每个项目了。

{{< img src=”669B2D1F-5AC9-4CE7-B1AE-CB890768E12D.png” alt=”清洁器结果(之二)” caption=”清洁器结果(之二)” >}}。
对于年份和名字……我们可以从输出中看到,第一个数字是出生年份。后面是一个HTML-Entity–(破折号)。最后,名字位于下面的<a>元素中。让我们把它们都抓住,我们就完成了

很完美,不是吗?它很有效,而且我们成功地得到了我们想要的数据,对吗?嗯,它确实有效,但我们没有选择一个特别优雅的方法。我们没有处理DOM树,而是采用了对HTML代码进行 “暴力 “字符串解析的方法,这样就错过了DOM解析器已经提供的大部分开箱即用的功能。这并不理想。
我们可以做得更好!
3.Guzzle、XML、XPath和IMDb
Guzzle是一个流行的PHP的HTTP客户端,它使发送HTTP请求变得简单和愉快。它为你提供了一个直观的API,广泛的错误处理,甚至有可能用额外的插件/中间件来扩展其功能。这使得Guzzle成为你不想错过的强大工具。你可以用composer require guzzlehttp/guzzle 从你的终端安装 Guzzle。
让我们切入正题,看看https://www.imdb.com/search/name/?birth_monthday=12-10的HTML(维基百科的URLs肯定更漂亮)。
我们可以直接看到,在这里我们需要一个比字符串函数和正则表达式更好的工具。我们看到的不是一个带有列表项的列表,而是嵌套的<div>s。没有id="...",我们可以用它来跳到相关的内容。但最糟糕的是:出生年份要么被埋没在传记的摘录中,要么根本就不可见
我们稍后会试着为年份的情况找到一个解决方案,但现在,至少让我们用XPath(一种从DOM文档中选择节点的查询语言)来获得我们禧年的名字。
在我们的新脚本中,我们将首先用Guzzle获取页面,将返回的HTML字符串转换为DOMDocument对象,然后用它初始化一个XPath解析器。
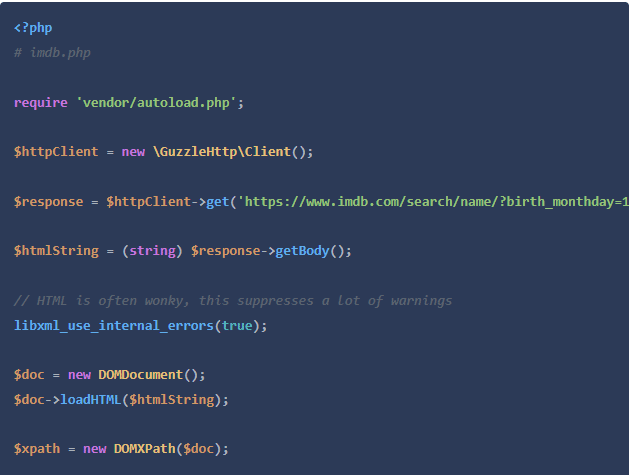
让我们仔细看一下上面窗口中的HTML。
- 列表包含在一个
<div class="list-list">元素中 - 这个容器的每个直接子代都是一个
<div>,在class属性中设置了两个类,即lister-item和mode-detail。 - 最后,名字可以在
<a>中找到,在<h3>中找到,在<div>中找到,有一个lister-item-content的类
如果我们仔细观察,我们可以把它变得更简单,跳过子神和类名:一个列表项中只有一个<h3>,所以让我们直接针对它。
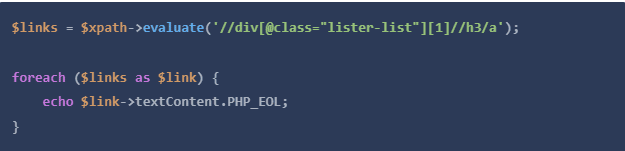
让我们把这个问题快速分解一下。
//div[@class="lister-list"][1]返回第一个([1])div标签,其属性名为class,其精确值为lister-list。- 在该div内,从所有
<h3>元素(//h3)返回所有锚点(<a>)。 - 然后我们对结果进行迭代,打印出锚点元素的文本内容
Guzzle是一个伟大的HTTP客户端,但其他许多客户端也同样优秀–它恰好是最成熟和下载最多的一个。PHP有一个庞大而活跃的社区;无论你需要什么,很有可能别人已经为它写了一个库或框架,网络爬取也不例外。
4.Goutte和IMDB
Goutte是一个为网络抓取而制作的HTTP客户端。它是由Symfony框架的创建者Fabien Potencier创建的,它结合了几个Symfony组件,使网络爬取非常舒适。
- BrowserKit组件模拟了一个网络浏览器的行为,你可以通过编程来使用。
- 把DomCrawler组件看作是DOMDocument和XPath的类固醇–除了类固醇之外,DomCrawler是很好的!
- CssSelector组件将CSS选择器翻译成XPath表达式。
- Symfony HTTP客户端是由Symfony团队开发和维护的,自然很容易集成到整个Symfony生态系统中。
让我们用composer require fabpot/goutte来安装Goutte,并用它来重新创建之前的XPath例子。
<?php # goutte_xpath.php require 'vendor/autoload.php'; $client = new \Goutte\Client(); $crawler = $client->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10');
$links = $crawler->evaluate('//div[@class="lister-list"][1]//h3/a');
foreach ($links as $link) {
echo $link->textContent.PHP_EOL;
}这一点就已经很不错了–我们省去了必须明确禁用XML警告的步骤,也不需要自己实例化一个XPath对象。现在,让我们使用一个 “原生 “的CSS选择器,而不是手动的XPath评估(感谢集成到Goutte中的CssSelector组件)。
我喜欢这样的发展方向;我们的脚本越来越像一个非程序员也能理解的对话,而不仅仅是代码。然而,现在是找出你是否在顺着编码的时候了:这个脚本在运行时是否返回结果?因为对我来说,一开始没有–我花了一个小时来调试原因,最后发现了一个解决方案。
这一次,我不会事先解释我们要执行的单一步骤,而只是向你们介绍最后的剧本;我相信它可以自己说话。
<?php # imdb_birthdates.php require 'vendor/autoload.php'; $client = new \Goutte\Client(); $client ->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10')
->filter('div.lister-list h3 a')
->each(function ($node) use ($client) {
$name = $node->text();
$birthday = $client
->click($node->link())
->filter('#name-born-info > time')->first()
->attr('datetime');
$year = (new DateTimeImmutable($birthday))->format('Y');
echo "{$name} was born in {$year}\n";
});由于页面上有50个人,因此必须进行50次额外的GET请求,所以现在脚本的运行将花费更长的时间,但是我们现在也有了这50个人中每个人的生日信息。
很好,但你说其他人呢?你是对的,IMDb上有超过1000人,他们以12月10日为生日,我们不应该忽视他们。让我们进入美丽的分页乐趣世界吧!
分页
当内容被分割成不同的页面时,它总是变得有点棘手,因为你也需要处理页面管理,一旦你访问了当前页面上的所有数据,就会改变到下一个页面。在无尽滚动的情况下,这可能特别棘手,但幸运的是,IMDb采用了传统的下一步»按钮的方式。
因此,让我们以一种方式扩展我们之前的代码示例,使其不仅抓取第一页,而且抓取所有页面。为此,我们将引入一个新的$url变量,用我们的起始URL初始化它,然后将我们的主爬虫代码移到一个while循环中,最后,在每次迭代中检查是否有下一个链接。如果没有,我们就到达了最后一页,在编制了一长串我们现在要发送生日快乐卡的人的名单之后,就可以结束了。但是,如果我们真的找到了下一个链接,我们就会知道我们还没有完成,将链接的URL存储在$url中,并开始我们的循环的另一次迭代。

摘要
在这一点上,我们的代码仍然是相当简洁的,但却完全完成了我们所要做的。它从给定的IMDb链接开始,从各个演员的页面上收集列出的个人资料和出生日期,然后继续到下一组演员,只要有进一步的数据。
由于Guzzle在默认情况下是按请求来处理一切的,它肯定会花一点时间来获取所有1000多份资料,而这正是一个可以进一步增强的机会。
- Guzzle确实支持并发请求;也许我们可以利用这一点来提高处理速度。
- IMDb的大部分列表都有图片,如果有每个演员的简介图片,那不是很好吗?(提示:
div.lister-item-image img[src])
5.无头浏览器
这里有一个问题:当我们在开发者控制台查看HTML DOM树时,我们看到的不是从服务器发送到浏览器的实际HTML代码,而是浏览器对DOM树解释的最终结果。如果一个网站不使用JavaScript,这个输出结果不会有太大的差别,但是网站运行的JavaScript越多,它就越有可能改变DOM树与服务器最初发送的结果。
当一个网站使用AJAX动态加载内容,或者甚至用JavaScript动态生成完整的HTML时,我们不能只从服务器下载原始的HTML文档来访问它。当涉及到浏览器行为时,像Goutte这样的工具可以模拟很多,但它们仍然有其局限性。这就是所谓的无头浏览器发挥作用的地方。
无头浏览器运行的是一个成熟的浏览器引擎,没有图形用户界面,它可以以类似于我们之前对模拟浏览器的方式进行编程控制。
Symfony Panther是一个独立的库,提供与Goutte相同的API–这意味着你可以在我们以前的Goutte脚本中使用它作为落地的替代。一个很好的特点是,它可以使用你电脑上已有的Chrome或Firefox的安装,这样你就不需要安装额外的软件。
既然我们已经实现了从IMDB获取生日的目标,让我们以从我们如此勤奋地解析的页面中获取截图来结束我们的旅程。
用composer require symfony/panther安装Panther后,我们可以这样写我们的脚本,比如。
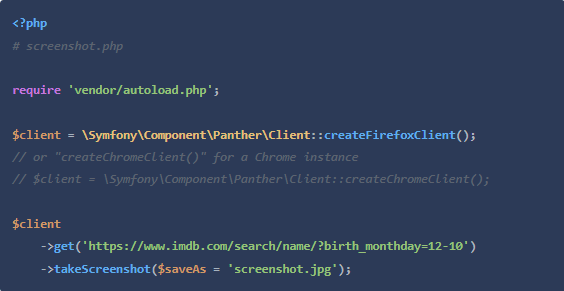
[文中代码源自Scrapingbee]
总 结
我们今天已经了解了几种用PHP爬取网页的方法。不过,还是有几个话题我们没有讲到–例如,网站所有者往往希望他们的网站只能由最终用户访问,如果以任何自动化的方式访问他们的网站,他们都不会太高兴。
- 当我们使用Goutte快速加载所有页面时,IMDb可能会将此解释为不寻常,并可能阻止我们的IP地址进一步访问他们的网站。
- 许多网站都有速率限制,以防止 “拒绝服务 “攻击。
- 根据你居住的国家和服务器的位置,一些网站可能无法从你的电脑上获得。
- 为不同的使用情况管理无头浏览器会对你的机器造成性能损失

