

网页爬取或爬取是通过下载和解析HTML代码来提取你想要的数据,从而从第三方网站获取数据的过程。
“但你为什么不使用API来做这个?”
好吧,不是每个网站都提供API,而且API并不总是暴露你需要的每一条信息。因此,爬取往往是提取网站数据的唯一解决方案。
网络爬取有许多用例。
- 电子商务价格监测
- 新闻聚合
- 潜在客户
- SEO(搜索引擎结果页监测)
- 银行账户汇总(美国的Mint,欧洲的Bankin’)。
- 个人和研究人员建立数据集,否则无法获得。
主要的问题是,大多数网站不希望被爬取。他们只想为使用真实网络浏览器的真实用户提供内容(除了涉及到谷歌的时候–他们都想被谷歌搜刮)。
因此,当你爬取时,你不希望被认为是一个机器人。有两种主要的方法可以让你看起来像人:使用人类的工具和模仿人类的行为。
这篇文章将指导你了解网站用来阻止你的所有工具,以及你可以成功克服这些障碍的所有方法。
1.模仿工具:无头浏览器
为什么采用无头浏览?
当你打开浏览器并进入一个网页时,几乎总是意味着你向一个HTTP服务器索取一些内容。从HTTP服务器提取内容的最简单的方法之一是使用经典的命令行工具,如cURL。
问题是,如果你只是运行curl www.google.com,谷歌有很多方法可以知道你不是人类(例如通过查看头信息)。标头是一些小的信息,这些信息伴随着进入服务器的每个HTTP请求。这些信息中的一个确切地描述了提出请求的客户端,即臭名昭著的 “User-Agent “标头。只要看一下 “User-Agent “头,Google就知道你在使用cURL。如果你想了解更多关于标头的信息,维基百科的页面很不错。作为一个实验,就到这里来。这个网页只是显示你的请求的头信息。
用cURL改变头是很容易的,提供一个合适的浏览器的User-Agent头可以做到这一点。在现实世界中,你需要设置一个以上的头。但是,用cURL或任何库人为地伪造一个HTTP请求,使请求看起来和用浏览器发出的请求一模一样,这并不困难。大家都知道这一点。因此,为了确定你是否在使用一个真正的浏览器,网站会检查一些cURL和库无法做到的事情:执行JavaScript代码。
你会用JavaScript吗?
这个概念很简单,网站在其内容中嵌入一个JavaScript片段,一旦执行,将 “解锁 “网页。如果你使用的是真正的浏览器,你不会注意到这种差别。如果你不是,你会收到一个含有一些晦涩的JavaScript代码的HTML页面。
再次,这个解决方案也不是完全无懈可击的,主要是因为现在用Node.js在浏览器之外执行JavaScript非常容易。然而,网络已经发展了,还有其他的技巧来确定你是否在使用一个真正的浏览器。
无头浏览器如何工作?
试图用Node.js在侧面执行JavaScript片段是很困难的,而且不健全。更重要的是,只要网站有一个更复杂的检查系统,或者是一个大的单页应用程序,cURL和用Node.js执行的伪JS就变得毫无用处。因此,看起来像一个真正的浏览器的最好方法是真正使用一个浏览器。
无头浏览器会表现得像一个真正的浏览器,因为它们是真正的浏览器,只不过你会很容易地以编程方式使用它们。最流行的是Chrome Headless,这是一个Chrome选项,表现得像Chrome,没有所有的用户界面包装。
使用Headless Chrome的最简单方法是调用一个将所有功能包装成简单API的驱动程序。 Selenium Playwright和Puppeteer是三个最有名的解决方案。然而,通常情况下,即使是无头浏览器也无法做到这一点,因为现在也有检测这些的方法,而且这种军备竞赛已经(并将)持续了相当长的时间。
浏览器指纹识别
如今,这是一个相当众所周知的事实,特别是在网络开发人员中,浏览器的行为可能非常不同。有时是关于渲染CSS,有时是关于它们如何执行JavaScript,有时只是表面的细节。这些差异中的大多数都是众所周知的,现在有可能检测出一个浏览器是否真的是它所假装的那样。这意味着网站会问:”所有的浏览器属性和行为是否与我所知道的这个浏览器发送的用户代理相符?
这就是为什么在想要冒充真正的浏览器的网络搜刮者和想要将无头浏览器与其他浏览器区分开来的网站之间存在着持久的军备竞赛。然而,网络爬取者往往有很大的优势,原因就在这里。
大多数时候,当JavaScript代码试图检测它是否在无头模式下运行时,这是当恶意软件试图逃避行为指纹识别。这意味着,JavaScript代码在扫描环境内会表现得很好,但在真正的浏览器环境下会追求其真正的目标。而这就是为什么Chrome无头模式背后的团队正试图使其与真实用户的网络浏览器无法区分,以阻止恶意软件这样做。网络搜刮者也可以从这种努力中获利。
还有一点需要知道的是,虽然并行运行20个cURL是微不足道的,而且Chrome Headless对于小的用例来说也比较容易使用,但是要把它放在规模上就比较麻烦了。因为它使用大量的内存,管理20个以上的实例是一个挑战。
至少在冒充真正的浏览器方面是这样的。接下来,让我们让我们的搜刮器表现得像一个真正的人。
TLS指纹识别
它是什么?
TLS是传输层安全(Transport Layer Security)的缩写,是SSL的后继者,基本上是HTTPS的 “S “所代表的含义。
该协议确保了两个通信的计算机应用程序(在我们的例子中,一个网络浏览器或脚本和一个HTTP服务器)之间的数据保密性和完整性。与浏览器指纹相似,TLS指纹的目标是根据浏览器使用TLS的方式来唯一地识别浏览器。这个协议是如何工作的,可以分成两个大的部分。
首先,当客户端连接到服务器时,正在进行一次TLS握手。在这个握手过程中,双方来回发送信息,以确保每个人实际上都是他们声称的人,并设置基本的连接参数。
然后,如果握手成功,该协议定义了客户端和服务器应如何以安全的方式加密和解密数据。如果你想要一个详细的解释,请查看Cloudflare的这个伟大的介绍。
用于建立指纹的大部分数据点都来自TLS握手,如果你想看看TLS指纹是什么样子的,你可以去访问这个很棒的在线数据库。该网站包含不同TLS指纹的统计数据,而且–截至撰写本文时–该网站上最常用的是133e933dd1dfea90,这似乎是来自苹果在iOS上的Safari浏览器,在过去一周中,每五个请求中就有一个使用该指纹。
这是一个相当大的数字,至少比最常见的浏览器指纹高两个数量级。这实际上是有道理的,因为TLS指纹的计算参数要比浏览器指纹少得多。
这些参数是,除其他外。
- TLS版本
- 握手版
- 支持的密码套件
- TLS扩展
如果你想查看更多关于浏览器TLS指纹的信息,SSL Labs将为你提供关于该问题的进一步见解和细节。
我怎样才能改变它呢?
理想情况下,为了提高你在搜刮网络时的隐蔽性,你应该改变你的TLS参数。然而,这比它看起来更难。
首先,因为没有那么多的TLS指纹,简单地将这些参数随机化是不行的。你的指纹将是如此罕见,以至于它将立即被标记为假的。其次,TLS参数是低级别的东西,严重依赖系统的依赖性。所以,改变它们并不简单。例如,著名的Python请求模块不支持改变TLS指纹的开箱。
这里有一些资源,可以用你喜欢的语言改变你的TLS版本和密码套件。
- 带有HTTPAdapter和请求的Python
- 带有TLS包的NodeJS
- 使用OpenSSL的Ruby
💡 请记住,这些库大多依赖于你系统的SSL和TLS实现。OpenSSL是使用最广泛的,你可能需要改变它的版本,以便完全改变你的指纹。
2.模仿用户行为。代理服务器、解决验证码和请求模式
一个使用真实浏览器的人很少会在同一网站上每秒请求20个页面。因此,如果你想从同一个网站上请求大量的页面,你应该让网站相信所有这些请求来自不同的地方,即不同的IP地址,最好是来自世界各地的不同地点/ISPs。这就是代理服务器的用武之地。
代理不是很贵:每个IP大约1美元。然而,如果你需要每天对同一个网站进行超过1万次的请求,成本会迅速上升,需要数百个地址。需要考虑的一点是,代理经常停止工作,所以应该不断监测这些代理,以便抛弃和替换这些代理。
代理服务商名单
市场上有几个代理供应商,最常用的是Proxy-seller、Bright Data、Soax 和 SmartProxy等有旋转网络代理。
也有很多免费的代理列表,不过,我不建议使用这些列表,因为它们往往很慢,而且不可靠,提供这些列表的网站对这些代理的位置并不总是透明的。免费代理列表通常是公开的,因此,网站更容易直接阻止这些代理地址。
这正是许多反爬取服务所做的,他们维护代理名单,并允许网站所有者自动阻止来自这些地址的流量,因此代理的 “质量 “很重要。
在代理列表方面,付费几乎总是胜过免费,这就是为什么我建议使用付费代理网络或创建自己的代理设置。
运行你自己的代理网络
CloudProxy是一个伟大的开源解决方案,可以运行你自己的代理网络。它是一个Docker镜像,允许你维护一个云托管的服务器实例列表,并让它自动管理和配置它们。
目前,CloudProxy支持DigitalOcean、AWS、Google和Hetzner作为服务提供者。你所需要做的就是指定你的账户API令牌,CloudProxy将从那里得到它,并根据你的配置设置提供和扩展代理实例。
ISP和移动代理服务器
使用代理列表(甚至是你自己的代理)需要考虑的一件事是,它们大多数时候都是在数据中心的背景下运行的,而数据中心对于你试图爬取的网站来说可能是一个直接的红旗。
问问自己,有多少 “普通 “用户会从数据中心的地下室浏览你的网站?
这就是ISP代理可能是有趣的地方。这样的代理设置仍然在数据中心环境中托管,然而,他们位于传统的ISP,而不是托管供应商,可能比直接来自谷歌数据中心的请求更好地融入标准流量行为。此外,由于仍在数据中心运行,它们当然仍具有数据中心的连接性和可靠性–两者都是最好的!
我们有另一篇关于这个主题的文章,所以请查看ISP代理的更多细节。
另一个不容错过的网络世界是移动世界。移动代理通过分配给移动网络运营商的IP地址块运行,并为任何主要迎合移动优先或仅有移动用户的网站和服务提供一个漂亮的本地方法。比较受欢迎的移动代理提供商有Proxy-Seller,Proxy-IPv4, Proxy-Cheap等,它们均提供性价比较高的移动IP。
Tor
另一个选择是Tor网络,又称 “The Onion Router”。它是一个世界性的计算机网络,旨在通过许多不同的服务器路由流量以隐藏其来源。Tor的使用使得网络监控/流量分析非常困难。使用Tor有很多用途,如隐私、言论自由、独裁政权中的记者,当然还有非法活动。
在网络搜刮方面,Tor的工作原理与代理非常相似,也会隐藏你的IP地址,并每10分钟改变你的机器人的IP地址。Tor出口节点的IP地址是公开的。一些网站使用一个简单的规则来阻止Tor的流量:如果服务器收到来自Tor公共出口节点之一的请求,它将阻止它。这就是为什么在许多情况下,与经典代理相比,Tor不会帮助你。值得注意的是,由于多层的重新路由,通过Tor的流量本身也要慢得多。
CAPTCHA
通常,仅仅改变你的IP地址是不行的。网站要求其访问者完成验证码的情况越来越普遍。CAPTCHA是一种挑战-回应测试,理想情况下人类很容易解决,但对机器来说很难甚至不可能。
大多数情况下,网站只对来自可疑IP地址的请求显示验证码,在这种情况下,切换代理可能会起到作用。如果不是这种情况,那么你实际上可能也需要解决验证码。
虽然许多验证码仍然可以用程序解决(例如用OCR)–与这个想法的实际承诺相反–但也有一些实现方式确实需要人为因素。
在这种情况下,2Captcha和Death by Captcha是两个例子,它们提供付费的API服务,从你的搜刮器中自动解决验证码。另一方面,这些API是由人类支持的,并承诺以一小部分美元及时解决验证码。
但是,即使你处理了验证码并使用了代理,网站仍然经常可以根据你发送请求的方式来确定你不是一个普通用户。
请求模式
另一种方法,即网站用来检测搜刮的方法,是试图在你发送的请求中找到模式。
1.请求率
例如,你有URL模板https://www.myshop.com/product/[ID],并想搜刮ID为1至10,000的内容。如果你按顺序并以恒定的请求率做这件事,就很容易说你可能是一个搜刮者。与其从1到10,000进行循环,不如有一个ID列表,在每次爬虫迭代时随机挑选一个。另外,确保你的请求率是随机的(例如,在几秒钟到一分钟之间的任何时间)。
2.指纹识别
有些网站也会评估你的浏览器指纹,如果你用无头浏览器的标准配置打出这些请求,就会被阻止。请参考我们之前在本文中讨论的关于指纹的内容。
3.地点
另一个赠品可能是你的位置。一些网站有非常狭窄的地理用途。一个巴西的食品递送服务在巴西以外的地方不会太有用,如果你通过美国或越南的代理刮取该网站,这可能很快会引起注意。
我知道一个例子,一个网站封锁了另一个国家的所有IP范围,只是因为它被该国自己的公司刮走了。
我可以根据经验告诉你,当涉及到寻找请求的模式时,最重要的因素是速率限制。你的机器人采用的自我约束越多,爬取网站的速度越慢,你在雷达下飞行的机会就越大,看起来就像网站的一个普通访问者。
3.模仿代码行为。
越来越多的网站不只是提供普通的HTML输出,而是实际提供适当的API端点,即使这些端点可能是非官方的和没有记录的。
特别是在它们只供内部使用的情况下,你仍然应该小心,大部分提到的规则仍然适用,但至少它可能提供一个更标准化的界面,互动元素,如JavaScript,可能是较少的因素。
API的逆向工程
这里主要归结为:
- 分析一个网页的行为,找到有趣的和相关的API调用
- 从你的代码中伪造这些API调用
例如,假设我想获得一个著名社交网络的所有评论。现在,当我点击 “加载更多评论 “按钮时,我可以在浏览器开发工具的检查器标签中观察到以下请求。
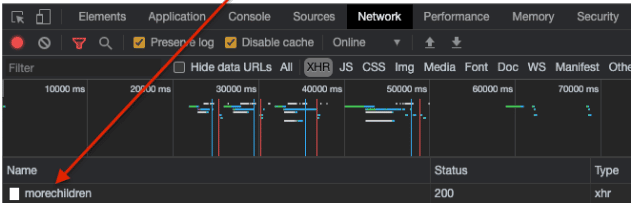
现在,如果我们检查我们收到的响应,我们注意到我们得到了一个包含所有重要数据的JSON对象。
再加上Headers标签中的数据,我们现在应该有了重放请求所需的一切,并了解哪些参数是预期的,以及它们的含义。这应该也为我们提供了从脚本中制作此类请求的机会。
对请求参数的分析部分是这项任务中最难的部分,因为可能存在一定的模糊性,你可能需要一些样本请求,以便能够调整你的请求并正确解释响应。另外,有时也要考虑到内置的搜刮保护层,如防止简单的请求重复的单一使用的令牌。
在任何情况下,你的浏览器的开发工具将极大地帮助你完成这项工作,你也可以将请求集导出为HAR文件,并在你最喜欢的HTTP工具中使用它们进行进一步分析(我喜欢Paw和Postman)。
移动应用程序的逆向工程
与API调试类似的原则,也适用于移动应用程序的逆向工程。你要拦截你的移动应用程序向服务器发出的请求,并用你的代码重放它。
做到这一点可能很难,原因有二。
- 为了拦截请求,你将需要一个中间人代理。
- 移动应用程序可以比网页应用程序更容易地标记和混淆他们的请求
例如,当Pokemon Go在几年前发布时,很多人都在使用允许他们操纵分数的工具。他们和这些工具的开发者不知道的是,Niantic增加了额外的参数,而这些作弊脚本并没有考虑到这些。在此基础上,Niantic识别和禁止这些玩家是小菜一碟。游戏发布几周后,大量玩家因作弊被禁。
另一个有趣的例子是星巴克和其非官方的API。有人真的花时间逆向开发了星巴克的API并记录了他的发现。他们似乎采用了很多我们在这篇文章中提到的技术:设备指纹、加密、一次性请求等等。
总 结
以下是我们在本文中看到的所有反机器人技术的回顾。
| 反机器人技术 | 应对措施 |
|---|---|
| 浏览器指纹识别 | 无头浏览器 |
| IP速率限制 | 轮换代理 |
| 禁止数据中心的IP | 住宅IP |
| TLS指纹识别 | 伪造和旋转TLS指纹 |
| 可疑活动的验证码 | 上述全部 |
| 始终在线的验证码 | 解决CAPTCHA的工具和服务 |
我希望这一概述能帮助你更好地了解网络扫描员可能遇到的困难以及如何应对或完全避免这些困难。

