

Playwright是一个用于Node.js的浏览器自动化库(类似于Selenium或Puppeteer),只需几行代码就可以实现可靠、快速、高效的浏览器自动化。它的简单性和强大的自动化功能使它成为网页爬取和数据挖掘的理想工具。它还带有无头浏览器支持。与Puppeteer相比,最大的区别是它的跨浏览器支持。
什么是无头浏览器,为什么它们被用于网页爬取?
在我们讨论Playwright之前,让我们先退一步,探讨一下什么是无头浏览器。好吧,无头浏览器是一个没有用户界面的浏览器。没有用户界面的明显好处是对资源的需求较少,而且能够在服务器上轻松运行。由于无头浏览器需要的资源较少,我们可以同时生成许多实例。这在一次从几个网页上爬取数据时很方便。
无头浏览器被用于网页抓取的主要原因是,越来越多的网站使用单页应用框架(SPA)构建,如React.js、Vue.js、Angular……。如果你用Axios这样的普通HTTP客户端来抓取这些网站,你会得到一个空的HTML页面,因为它是由前端的Javascript代码构建的。无头浏览器通过执行Javascript代码来解决这个问题,就像你的普通桌面浏览器一样。
开始使用Playwright
学习的最好方法是建立一些有用的东西。我们将使用Playwright编写一个网络刮刀,爬取金融数据。
第一步是创建一个新的Node.js项目并安装Playwright库。
nmp init --yes npm i playwright
让我们创建一个index.js文件,并写下我们的第一个playwright代码:
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: false // setting this to true will not run the UI
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/world-indices');
await page.waitForTimeout(5000); // wait for 5 seconds
await browser.close();
}
main();在上面的例子中,我们正在创建一个新的无头浏览器的chromium实例。注意,我暂时将无头浏览器设置为false(第4行),这将在我们运行代码时弹出一个用户界面。设置为 “true “将在无头模式下运行Playwright。我们在浏览器中创建一个新的页面,然后我们访问雅虎财经网站。我们在等待5秒钟,然后关闭浏览器。
让我们在浏览器中跳入雅虎财经网站。检查雅虎财经的主页。假设我们正在建立一个金融应用程序,我们想为我们的应用程序爬取所有的股票市场数据。在雅虎的主页上,你会看到头顶的综合市场数据显示在标题中。我们可以在浏览器检查器中检查标题元素和它的DOM节点,如下图所示:
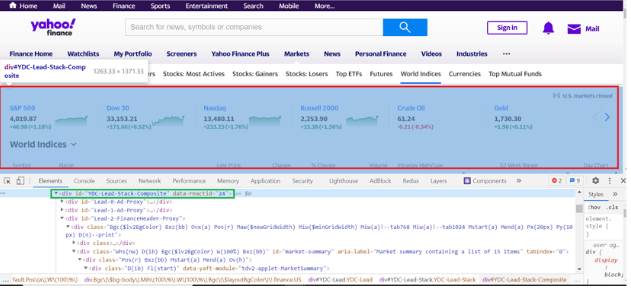
请注意,这个头有一个id=YDC-Lead-Stack-Composite。我们可以针对这个id,提取其中的信息。我们可以在我们的代码中添加以下几行:
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/world-indices');
const market = await page.$eval('#YDC-Lead-Stack-Composite', headerElm => {
const data = [];
const listElms = headerElm.getElementsByTagName('li');
listElms.forEach(elm => {
data.push(elm.innerText.split('\n'));
});
return data;
});
console.log('Market Composites--->>>>', market);
await page.waitForTimeout(5000); // wait
await browser.close();
}
main();page.$eval函数需要两个参数。第一个是一个选择器标识符。在这种情况下,我们传入了我们想要抓取的节点的id。第二个参数是一个匿名函数。任何你能想到的在浏览器中运行的客户端代码都可以在这个函数中运行。
让我们 再 仔细看一下*$eval* 代码块:
const market = await page.$eval('#YDC-Lead-Stack-Composite', headerElm => {
const data = [];
const listElms = headerElm.getElementsByTagName('li');
listElms.forEach(elm => {
data.push(elm.innerText.split('\n'));
});
return data;
});突出显示的部分是简单的客户端JS代码,正在抓取头节点内的所有li元素。然后我们做一些数据处理并返回。
你可以在这里的官方文档中了解更多关于这个$eval函数。
执行这段代码,在终端打印出以下内容:

我们已经成功地爬取到了第一条信息。
用Playwright爬取元素列表
接下来,让我们从一个表中爬取一个元素列表。我们将从https://finance.yahoo.com/most-active,爬取交易最活跃的股票。下面我提供了一个页面的截图和我们感兴趣的信息。
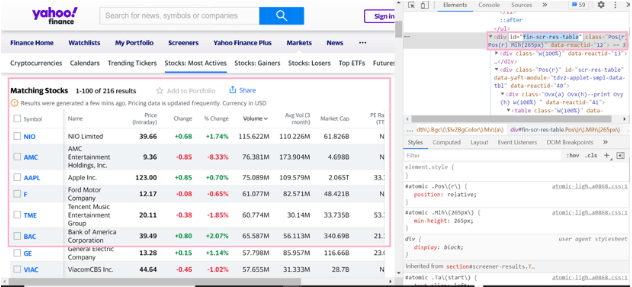
你可以看到,我们感兴趣的id是fin-scr-res-table。我们可以将我们的搜索深入到针对该DOM节点中的表元素。
这里有一个脚本,可以做这个动作:
const playwright = require('playwright');
async function mostActive() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/most-active?count=100');
const mostActive = await page.$eval('#fin-scr-res-table tbody', tableBody => {
let all = []
for (let i = 0, row; row = tableBody.rows[i]; i++) {
let stock = [];
for (let j = 0, col; col = row.cells[j]; j++) {
stock.push(row.cells[j].innerText)
}
all.push(stock)
}
return all;
});
console.log('Most Active', mostActive);
await page.waitForTimeout(30000); // wait
await browser.close();
}
mostActive();page.$eval的作用类似于客户端JavaScript的querySelector属性(了解更多关于querySelector)。
如果我想爬取一个网页中某一类型(如a、li)的所有标签,怎么办?
在这种情况下,我们可以简单地使用page.$(selector)函数来实现。这将返回在给定页面中匹配特定选择器的所有元素。
async function allLists() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/');
const allList = await page.$$('li', selected => {
let data = []
selected.forEach((item) => {
data.push(item.innerText)
});
return data;
});
console.log('Most Active', allList);
}搜集图片
接下来,让我们从一个网页上爬取一些图片。在这个例子中,我们将使用scrapingbee.com的主页。我们将在这里爬取ScrapingBeeBot的图片。
基本思路是一样的。首先,我们以DOM节点为目标,抓取我们感兴趣的图片。然而,为了下载图像,我们需要图像src。一旦我们有了源码,我们就必须向源码发出HTTP GET请求并下载图片。让我们来看看下面的例子:
const playwright = require('playwright');
const axios = require("axios");
const fs = require("fs");
async function saveImages() {
const browser = await playwright.chromium.launch({
headless: true
});
const page = await browser.newPage();
await page.goto('https://www.scrapingbee.com/');
const url = await page.$eval(".pdxItem.pdxItem--img-solid img", img => img.src);
const response = await axios.get(url);
fs.writeFileSync("scrappy.svg", response.data);
await browser.close();
}
saveImages();拍下屏幕截图如何?
我们也可以用Playwright对页面进行截图。Playwright包含一个page.screenshot方法。使用这个方法,我们可以对网页进行一次或多次截图。
async function takeScreenShots() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage()
await page.setViewportSize({ width: 1280, height: 800 }); // set screen shot dimention
await page.goto('https://finance.yahoo.com/')
await page.screenshot({ path: 'my_screenshot.png' })
await browser.close()
}
takeScreenShots()我们也可以将我们的截图限制在屏幕的一个特定部分。我们必须指定我们视口的坐标。下面是一个如何做到这一点的例子:
const options = {
path: 'clipped_screenshot.png',
fullPage: false,
clip: {
x: 5,
y: 60,
width: 240,
height: 40
}
}
async function takeScreenShots() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage()
await page.setViewportSize({ width: 1280, height: 800 }); // set screen shot dimention
await page.goto('https://finance.yahoo.com/')
await page.screenshot(options)
await browser.close()
}
takeScreenShots()x和y坐标从屏幕的左上角开始。
用XPath表达式选择器进行查询
Playwright的另一个简单而强大的功能是它能够用XPath表达式来定位和查询DOM元素。什么是XPath表达式? XPath表达式是一种定义的模式,用来选择DOM中的一组节点。
你可以在我们的XPath—实用的网页爬取技术文章中了解更多的信息。
解释这个问题的最好方法是用一个全面的例子来证明。比方说,我们试图从StackOverflow博客中抓取所有的导航链接。观察一下,我们想抓取DOM中的导航元素。我们可以看到,我们感兴趣的导航元素被悬挂在树上,其层次结构如下html > body > div > header > nav
利用这些信息,我们可以创建我们的xpath表达式。本例中我们的表达式将是xpath=//html/body/div/header/nav。
这里的脚本将使用xpath表达式来定位DOM中的nav元素。
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://stackoverflow.blog/');
const xpathData = await page.$eval('xpath=//html/body/div/header/nav',
navElm => {
let refs = []
let atags = navElm.getElementsByTagName("a");
for (let item of atags) {
refs.push(item.href);
}
return refs;
});
console.log('StackOverflow Links', xpathData);
await page.waitForTimeout(5000); // wait
await browser.close();
}
main();Playwright内部的XPath引擎等同于本地Document.evaluate()表达式。你可以在这里了解更多关于它的信息。
提交表格和爬取认证的路线
有的时候,我们会想爬取一个有认证保护的网页。现在,Playwright的一个好处是,它使提交表单变得非常简单。让我们深入了解这种情况的一个例子。
// Example taken from playwright official docs
const playwright = require('playwright');
async function formExample() {
const browser = await playwright.chromium.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://github.com/login');
// Interact with login form
await page.fill('input[name="login"]', "MyUsername");
await page.fill('input[name="password"]', "Secrectpass");
await page.click('input[type="submit"]');
}
formExample();
// Verify app is logged in
[代码源自Scrapingbee]正如你在上面的例子中看到的,我们可以很容易地模拟点击和填表事件。运行上述脚本将产生如下结果:
查看官方文件,了解更多关于与剧作家的认证。
Playwright vs 其他(Puppeteer, Selenium)
Playwright与其他一些已知的解决方案(如Puppeteer和Selenium)相比如何?Playwright 的主要卖点是易于使用。与Selenium相比,它对开发者非常友好。另一方面,Puppeteer也对开发者友好,易于设置;因此,Playwright在与Puppeteer的竞争中没有明显的优势。
让我们来看看这三个库的npm趋势和受欢迎程度
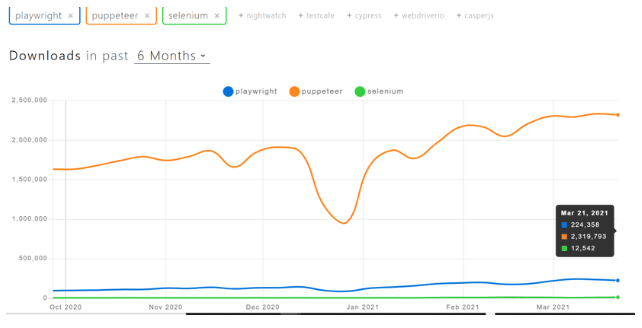
你可以看到,Puppeteer显然是三个中最受欢迎的选择。 然而,看看这些库的GitHub活动,我们可以得出结论,Playwright和Puppeteer背后都有一个强大的开源开发者社区。
来源https://www.npmtrends.com/playwright-vs-puppeteer-vs-selenium
文档方面如何?
Puppeteer和Playwright都有优秀的文档。另一方面,Selenium也有相当好的文档,但它可以做得更好。
性能比较
对这三个框架进行细微的比较超出了本文的范围。对我们来说,幸运的是,其他人之前已经做了这个。你可以看一下这篇详细的文章,了解这些工具的性能比较。当我们在这三种环境中运行相同的爬取脚本时,与Playwright和Puppeteer相比,我们发现Selenium的执行时间更长。Puppeteer和Playwright的性能在我们运行的大部分爬取作业中几乎是相同的。然而,看一下各种性能基准(像上面的链接那样更精细的调整),似乎 Playwright 在少数情况下确实比 Puppeteer 表现更好。
最后,这里是我们对这些图书馆的比较总结。
| 类别 | Playwright | Puppeteer | Selenium Web Driver |
|---|---|---|---|
| 执行时间 | 快速和可靠 | 快速和可靠 | 启动时间慢 |
| 文件 | 优秀 | 优秀 | 总的来说,除了一些例外情况,文件记录得相当好。 |
| 开发者经验 | 非常好 | 非常好 | 公平 |
| 社区 | 小而活跃的社区。 | 拥有一个大型社区,有很多活跃的项目。 | 拥有一个庞大而活跃的社区 |
总 结
总而言之,Playwright是一个强大的无头浏览器,拥有优秀的文档,背后还有一个不断壮大的社区。如果你已经有了Node.js的经验,想快速启动和运行,关心开发者的快乐和性能,那么Playwright是你的网页爬取解决方案的理想选择。希望这篇文章能让你对Playwright有一个良好的初步了解。

