

XPath是一种技术,它使用路径表达式来选择XML文档(或者在我们的例子中是HTML文档)中的节点或节点集。即使XPath本身不是一种编程语言,它也允许你写一个表达式,可以直接指向一个特定的HTML元素,甚至是标签属性,而不需要手动遍历任何元素列表。
在我们上一篇关于用Python爬取网页的文章中,我们已经简单地讨论了XPath表达式。现在是时候对这个主题进行更深入的挖掘了。
为什么要学习XPath
- 当从网页中提取数据时,知道如何使用基本的XPath表达式是一项必备的技能。
- 它比CSS选择器更强大(例如,你可以引用父元素)。
- 它允许你在任何方向上导航DOM
- 可以匹配HTML元素内的文本
关于XPath的主题已经写了整整一本书,我现在当然不想声称这篇文章将为这个主题的每一个方面提供全面的指导,它只是对XPath的一个介绍,我们将通过真实的例子看到你如何将它用于你的网络爬取项目。
但首先,让我们谈一谈DOM的情况
文档对象模型(DOM)
我将假设你已经知道HTML,所以这只是一个小小的复习。
正如你已经知道的那样,网页是一个由HTML标签组成的层次结构的文件,它描述了整个页面的布局(即段落、列表)并包含相关的内容(即文本、链接、图像)等等。让我们看看一个基本的HTML页面,以了解什么是文档对象模型。
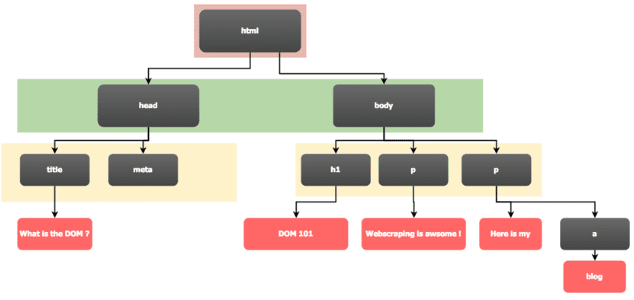
正如你从图片中注意到的那样(缩进线提供了另一个提示),HTML文档可以被视为一棵树。这正是大多数HTML解析器(即你的网络浏览器)要做的事情,它们会将HTML内容解析成一个内部的树状表示–这就是所谓的DOM,即文档 对象 模型。
下图是Chrome浏览器开发者工具的截图,显示了DOM的文本表述,在我们的例子中,它与我们的HTML代码非常相似。
有一点要记住,虽然在我们的例子中,DOM树与我们的HTML代码非常相似,但不能保证永远如此,DOM树 可能与服务器最初发送的HTML代码 有很大不同。你问这是为什么?我们的好朋友JavaScript。
只要不涉及JavaScript,DOM树就会与服务器发送的内容基本一致,但是如果有了JavaScript,所有的赌注都会取消,DOM树可能已经被它严重操纵了。特别是SPA通常只发送一个基本的HTML骨架,然后由JavaScript来 “丰富 “它的内容。以Twitter为例,每当你滚动到页面底部,一些JavaScript代码就会获取新的推文,并将它们追加到页面上,也就是追加到DOM树上。
现在,我们已经学习了(或者说刷新了)HTML和DOM的基础知识,我们可以深入研究XPath。
XPath语法
首先让我们看一下一些XPath词汇。
- Nodes–有不同类型的节点,根节点、元素节点、属性节点,以及所谓的原子值,这是HTML文档中文本节点的同义词。
- Parents– 包含当前元素的直接元素。每个元素节点都有一个父元素。在我们上面的例子中,
html是head和body的父元素,而body是网站实际内容的父元素。 - Children– 当前元素所包含的直接元素。元素结点可以有任何数量的子元素。在我们的例子中,
h1和两个p元素都是body的子元素。 - Siblings– 与当前元素处于同一层次的节点。在我们的例子中,
head和body是兄弟姐妹(在它们作为html的子女的功能中),h1和两个p元素也是兄弟姐妹(在它们作为body的子女的功能中)。 - Ancestors– 当前元素的所有父元素的列表。
- Descendants– 当前元素的所有子元素(有自己的孩子)的列表。
下面是一个基本语法元素的列表,你将使用它们来组合你的XPath表达式
| XPath元素 | 描述 |
|---|---|
| nodename | 这是最简单的一个,它选择所有具有该节点名称的节点 |
/ | 从根节点选择(对编写绝对路径很有用)。 |
// | 从当前节点中选择符合以下条件的节点 |
. | 选择当前节点 |
.. | 选择当前节点的父节点 |
@ | 选择属性 |
* | 匹配任何元素 |
preceding:: | 选择 |
| following:: | |
| function() | 在给定的上下文中调用一个XPath函数(例如text(),contains())。 |
XPath谓词
XPath也支持谓词,它允许你对你用原始表达式得到的元素列表进行过滤。谓词被添加到你的XPath表达式的方括号中,[mypredicate]。几个谓词的例子是
| 谓语 | 描述 |
|---|---|
//li[last()] | 选择每一层的最后一个li元素。 |
//div[@class="product"] | 选择所有具有class属性值为product的div元素。 |
//li[3] | 选择每一层的第三个(XPath是基于一个)li元素。 |
//div[@class='product'] | 选择所有具有 product 值的 class 属性的div元素。 |
XPath例子
好了,现在我们已经涵盖了基本的语法,让我们根据之前的例子中的HTML代码来看看几个例子。
| XPath表达式 | 描述 |
|---|---|
/html | 选择文档的根元素。 |
/html/head/title/text() | 选择<title>的文本内容。 |
//meta/@charset | 选择文档中所有<meta>标签的charset属性。 |
//p[last()] | 选择每一层的最后一个<p>标签。 |
//* | 选择整个文档中的每一个元素。 |
//*[1] | 选择每一层的第一个元素(即html、head、title和h1)。 |
//h1/.. | 选择每个<h1>标签的父元素。 |
浏览器中的XPath
幸运的是,浏览器原生支持XPath,所以只要打开你最喜欢的网站,按F12键进入开发工具,然后切换到Elements/Inspector标签,就可以看到当前页面的DOM树。
现在,只需按下Ctrl/Cmd+F,你就会得到一个DOM搜索字段,你可以在这里输入任何XPath表达式,输入后,你的浏览器就会突出显示下一个匹配项。
开发者工具还提供了一种方便的方法来获取任何DOM元素的XPath表达式。只要右击一个DOM元素并复制XPath。
使用Python的XPath
有很多Python包都支持XPath:
在下面的例子中,我们将在无头模式下使用Selenium和Chrome。
1.电子商务产品数据提取
在这个例子中,我们将加载一个亚马逊页面
并使用几个XPath表达式来选择产品名称、价格和亚马逊图片。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, service=Service(ChromeDriverManager().install()))
driver.get("https://www.amazon.com/Dyson-V10-Allergy-Cordless-Cleaner/dp/B095LD5SWQ/")
title = driver.find_element(by=By.XPATH, value='//span[@id="productTitle"]')
current_price = driver.find_element(by=By.XPATH, value='//div[@id="corePrice_feature_div"]//span[@data-a-color="price"]/span[1]')
image = driver.find_element(by=By.XPATH, value='//div[@id="imgTagWrapperId"]/img')
product_data = {
'title': title.text,
'current_price': current_price.get_attribute('innerHTML'),
'image_url': image.get_attribute('src')
}
print(product_data)
driver.quit()虽然所有的浏览器设置调用都很吸引人(毕竟我们真的用这些代码运行了一个成熟的浏览器实例),但在本教程中,我们真正想关注的是以下表达。
//span[@id=”productTitle”]
//div[@id=”corePrice_feature_div”]//span[@data-a-color=”price”]/span[1]
//div[@id=”imgTagWrapperId”]/img
这三个表达式都是相对的(注意是//),这意味着我们是从整个DOM树中选择元素,而不是指定一个完全的绝对路径。每个表达式还使用了一个谓词,根据元素的ID进行过滤。
- 第一个表达式只是选择一个ID为 “productTite “的标签。这应该会给我们产品的名称。
- 第二个表达式选择一个ID为 “corePrice_feature_div “的标签,然后在其子代中搜索一个标签,并使用第一个直接的子代来表示产品价格。
- 最后但并非最不重要的是,图片的URL。在这里,我们搜索一个标签,并选择其直接的
子。
我们的例子还是比较简单的,因为我们有奢侈的HTML ID,它应该是唯一的。例如,如果你要过滤HTML类,你可能要更注意,可能要借助于绝对路径。
2.用XPath提交登录表格的通用方法
当你爬取网站时,你经常要对网站进行认证。虽然登录表格有不同的风格和布局,但它们通常遵循类似的格式,一个文本字段是用户名,另一个是密码,最后一个是提交按钮。
即使格式相同,DOM结构也会因网站而异–而这正是我们可以运用XPath及其DOM导航功能来创建一个 “通用 “认证函数的地方。我们的函数将接受一个Selenium驱动对象、一个URL、一个用户名和一个密码,并将使用所有这些来登录网站。
def autologin(driver, url, username, password): # Load the page driver.get(url) # Find a password input field and enter the specified password string password_input = driver.find_element(by=By.XPATH, value="//input[@type='password']") password_input.send_keys(password) # Find a visible input field preceding out password field and enter the specified username username_input = password_input.find_element(by=By.XPATH, value=".//preceding::input[not(@type='hidden')]") username_input.send_keys(username) # Find the form element enclosing our password field form_element = password_input.find_element(by=By.XPATH, value=".//ancestor::form") # Find the form's submit element and click it submit_button = form_element.find_element(by=By.XPATH, value=".//*[@type='submit']") submit_button.click() return driver
好吧,我们到底在这里做了什么?
1. 我们只是用get()方法将指定的URL加载到我们的驱动对象中。到目前为止很简单,对吗?
2. 现在我们用表达式//input[@type="password"] 找到一个<input type="password" />标签,并且–因为我们大胆地假设这是我们唯一的密码字段–输入提供的密码(send_keys())。还是很简单,不是吗?别着急,事情越来越复杂了,我们现在正在向后搜索。
3. 接下来,找到用户名字段。从密码字段开始,我们在DOM中向后走(preceding::input),试图找到紧接着的没有隐藏的<input />字段。再次,我们大胆地假设这是我们的用户名字段,并输入所提供的用户名(send_keys())。隐藏的部分在这里相当重要,因为表单往往包含这样的附加字段,例如用一次性来防止跨站请求伪造的尝试。如果我们不排除这种隐藏字段,我们就会选择错误的输入元素。
4. 我们编译了表单,只需要提交它,但为此我们应该首先找到表单。我们用祖先::表单找到了<form>标签,它包含了我们的密码字段。
5. 我们成功了。我们找到了表单元素,编译了相关的认证元素,现在只需要提交表单。为此,我们使用*[@type="submit"]从表单上下文中获取任何 “submit “类型的标签并点击它。完成了,尘埃落定!
请记住,虽然这个例子对很多网站都适用,而且可以节省你手动分析每个登录页面的时间,但它主要还是一个XPath的基本展示,而且会有很多网站无法使用它(即结合注册/登录页面),所以请不要把它作为你所有爬取程序的直接解决方案。
3.处理和过滤HTML内容
让我们用XPath的方式爬取–https://news.ycombinator.com/newest 的前三页
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, service=Service(ChromeDriverManager().install()))
driver.get("https://news.ycombinator.com/newest")
articles = []
for i in range(0, 3):
elems = driver.find_elements(by=By.XPATH, value="//a[@class='titlelink'][starts-with(text(), 'Ask HN')]/../..")
for elem in elems:
link = elem.find_element(by=By.XPATH, value=".//a[@class='titlelink']")
articles.append({
"id": elem.get_attribute("id"),
"link": link.get_attribute("href"),
"title": link.text
})
next = driver.find_element(by=By.XPATH, value="//a[@rel='next']")
next.click()
print(articles)
driver.quit()再一次,让我们一步步深入了解我们在这里究竟做了什么。
1. 我们从大量的初始化开始
2. 然后,我们加载了我们的起始页 https://news.ycombinator.com/newest
3. 根据我们收到的HTML内容,我们使用一个带有两个谓词和父级指针的XPath表达式来获得所选元素的祖先
4. 现在,我们对所有找到的元素进行循环,并将它们的ID存储在一个数组中,同时还有一个子<a>标签的链接细节。
5. 我们说过我们想要前三页,对吗?所以,让我们找到下一个按钮,点击它,然后GOTO 2
6. 我们现在已经收集了相当多的信息,所以至少不打印出来是一种浪费,不是吗?
和以前一样,在现实世界中,我们可以在一定程度上优化这段代码(例如,我们不需要搜索锚点标签,只需要直接进入它们的表行父类),但这个练习的重点当然是展示更多的XPath用例–偶尔肯定会有一些网站的HTML结构需要这样的杂技。
总 结
当涉及到XML(以及HTML)时,XPath是一个非常通用、紧凑和富有表现力的工具,而且通常比CSS选择器更强大,当然,CSS选择器的性质非常相似。
虽然XPath表达式一开始看起来很复杂,但真正具有挑战性的部分往往不是表达式本身,而是获得正确的路径,要足够精确地选择所需的元素,同时要足够灵活,在DOM树有微小变化时不会立即中断。

