

你是否有想过定期以结构化方式从某个网站获得数据,但该网站还没有提供标准化的API,如JSON REST接口?不要着急,网页爬取技术可以帮助你。
欢迎来到网页爬取的世界
网页爬取,或网络爬行,是指从一个网站获取和提取任意数据的过程。这包括下载该网站的HTML代码,解析该HTML代码,并从中提取所需的数据。
如果上述的REST API不可用,当涉及到从一个网站收集信息时,爬取通常是唯一的解决方案。这是一个常用的商业标准,以自动化的方式获得数据,可以用于你选择的任何主题。例如,分析你的竞争对手的定价方案的变化,从不同的新闻机构汇总最新的故事,或为你的最新营销活动收集地址信息。
基本上做的是标准网络浏览器的工作,对于你可以收集的信息几乎没有任何限制,最棘手的部分通常是从多媒体内容(即图像、音频、视频)中获取信息。
在这篇文章中,我们将指导你如何在Java中设置一个基本的网络爬虫,获取一个网站,解析和提取数据,并将所有内容存储在一个JSON结构中。
准备条件
由于我们的演示项目将使用Java,请确保在继续进行之前,你已具备以下先决条件。
- Java 8的SDK
- 一个合适的Java集成开发环境(如Eclipse)。
- 如果不是你的IDE的一部分,Maven用于依赖性管理
当然,对Java和XPath的概念有一个基本的了解也会加快事情的进展。
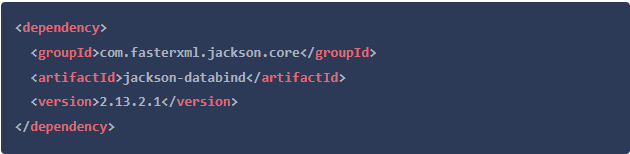
请确认你已经在pom.xml文件中加入了HtmlUnit作为依赖项。

如果你使用Eclipse,建议在细节窗格中设置输出的最大长度(当你点击变量标签时),这样你就会收到整个页面的HTML代码。
让我们爬取一下Craigslist网站
对于我们这里的例子,我们将专注于Craigslist,并希望得到一个纽约所有分类广告的列表,出售iPhone 13。
由于Craigslist不提供API,我们唯一的选择是走爬取的道路,直接从网站上提取数据。为此,我们将抓取网站,收集所有物品的名称、价格和图片,并将其全部导出为JSON结构。
寻找正确的搜索网址
首先,让我们看看当你在Craigslist上搜索东西时会发生什么。
- 转到https://newyork.craigslist.org
- 在左边的搜索框中输入
iphone13。 - 按回车键
你将立即被重定向到包含所有找到的产品的搜索页面。在这个例子中,地址栏中的URL将是目前最有趣的东西。

在这一点上,我们已经确定了这个特定查询的搜索URL是什么,以及它需要哪些参数(例如query)。
现在你可以打开你最喜欢的IDE,是时候进行编码了。
获取页面
要向一个网站发出请求,你首先需要一个HTTP客户端来发送该请求。恰好,HtmlUnit为这个任务提供了一个默认的类,叫做WebClient。
你可以调整相当多的参数来定制它的行为(例如代理设置、CSS支持等等),但在我们的例子中,我们将使用没有CSS和JavaScript支持的原始配置。
// Define the search term String searchQuery = "iphone 13"; // Instantiate the client WebClient client = new WebClient(); client.getOptions().setCssEnabled(false); client.getOptions().setJavaScriptEnabled(false); // Set up the URL with the search term and send the request String searchUrl = "https://newyork.craigslist.org/search/moa?query=" + URLEncoder.encode(searchQuery, "UTF-8"); HtmlPage page = client.getPage(searchUrl);
在这一点上,我们在page变量中拥有网站的内容,我们可以用asXml()方法访问整个文档,然而我们对HTML文档的特定数据项更感兴趣。
为此,我们在浏览器中使用开发工具的检查器功能(F12)来检查网站的结构。
基于这一点,我们现在知道,所有项目都是<li>标签,位于<ul>容器标签下面,其ID是search-results。此外,每个<li>标签都将被分配有HTML类result-row。
提取数据
有了这些知识,我们现在可以使用XPath来访问返回的产品和它们的项目属性。HtmlUnit为此提供了一些方便的方法(例如getHtmlElementById,getFirstByXPath,getByXPath),这些方法允许你使用XPath表达式来精确访问从文档中获取的数据。关于支持的方法的更多信息,请参考HtmlUnit的JavaDoc。
让我们一步一步地看一下下面的代码。
- 我们正在获取所有上述的
<li>标签与类结果行,并将它们存储在变量项中。 - 我们正在对
项目进行迭代,并将每个条目存储为项目。 - 对于每个
项目,我们要看- 产品细节,在
<a>标签下(包含在<p>标签内,类别为结果-信息)。 - 产品价格,在
<span>标签下(包含在<a>标签中),类别为结果-价格。
- 产品细节,在
- 一旦我们有了细节和价格,我们就在屏幕上打印。
// Retrieve all
- elements
List items = (List) page.getByXPath(“//li[@class=’result-row’]”);
if (!items.isEmpty()) {
// Iterate over all elements
for (HtmlElement item : items) {// Get the details fromHtmlAnchor itemAnchor = ((HtmlAnchor) htmlItem.getFirstByXPath(“.//p[@class=’result-info’]/a”));// Get the price from
HtmlElement spanPrice = ((HtmlElement) htmlItem.getFirstByXPath(“.//a/span[@class=’result-price’]”)) ;String itemName = itemAnchor.asText()
String itemUrl = itemAnchor.getHrefAttribute()// It is possible that an item doesn’t have any price
String itemPrice = spanPrice == null ? “0.0” : spanPrice.asText() ;System.out.println( String.format(“Name : %s Url : %s Price : %s”, itemName, itemPrice, itemUrl));}
}
else {
System.out.println(“No items found !”);
}
瞧,我们已经解析了整个页面,并设法提取了单个产品项目。
转化为JSON
虽然前面的例子对如何快速爬取网站提供了一个很好的概述,但我们可以更进一步,将数据转换成结构化和机器可读的格式,如JSON。
为此,我们只需要对我们的代码做一些小的修改。
- 一个POJO数据类
- 将数据映射到我们的类,而不是直接打印它
POJO
我们添加一个额外的POJO(Plain Old Java Object)类,它将代表JSON对象并保存我们的数据。
public class Item {
private String title;
private BigDecimal price;
private String url;
public String getTitle()
{
return title;
}
public void setTitle(String title)
{
this.title = title;
}
public BigDecimal getPrice()
{
return price;
}
public void setPrice(BigDecimal price)
{
this.price = price;
}
public String getUrl()
{
return url;
}
public void setUrl(String url)
{
this.url = url;
}
}绘图
现在,我们可以扩展之前的for循环,为每个找到的项目创建一个Item实例,并将其映射为JSON对象。
for(HtmlElement htmlItem : items){
HtmlAnchor itemAnchor = ((HtmlAnchor) htmlItem.getFirstByXPath(".//p[@class='result-info']/a"));
HtmlElement spanPrice = ((HtmlElement)htmlItem.getFirstByXPath(".//a/span[@class='result-price']"));
// It is possible that an item doesn't have any
// price, we set the price to 0.0 in this case
String itemPrice = spanPrice == null ? "0.0" : spanPrice.asText();
Item item = new Item();
item.setTitle(itemAnchor.asText());
item.setUrl(baseUrl + itemAnchor.getHrefAttribute());
item.setPrice(new BigDecimal(itemPrice.replace("$", "")));
ObjectMapper mapper = new ObjectMapper();
String jsonString = mapper.writeValueAsString(item);
System.out.println(jsonString);
}代码样本
你可以在Github资源库中找到这个例子的完整源代码。
让我们继续
到目前为止,我们的项目为我们提供了一个快速的概述,即什么是网络抓取,它的基本概念,以及如何使用Java和XPath建立我们自己的爬行器。
目前,这是一个相对简单的例子,采取一个定义的搜索词,并作为JSON返回在纽约市地区销售的所有产品。如果我们想获得不止一个城市的数据呢?让我们来看看。
多城市支持
如果你仔细观察我们之前用于搜索的URL,你会发现,Craigslist按城市对其广告进行编目,并将该信息作为URL的主机名的一部分。例如,我们在纽约市的广告都在下面的URL后面
https://newyork.craigslist.org
如果我们想获取与波士顿有关的广告,我们就会使用https://boston.craigslist.org。
现在,让我们说,我们想检索东海岸的所有iPhone 13广告,特别是纽约、波士顿和华盛顿特区的广告,在这种情况下,我们只需重新审视我们的代码,从获取页面和扩展它一点,以支持其他城市。
// Define the search term
String searchQuery = "iphone 13";
String[] cities = new String[]{"newyork", "boston", "washingtondc"};
// Instantiate the client
WebClient client = new WebClient();
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
for (String city : cities)
{
// Set up the URL with the search term and send the request
String searchUrl = "https://" + city + ".craigslist.org/search/moa?query=" + URLEncoder.encode(searchQuery, "UTF-8");
HtmlPage page = client.getPage(searchUrl);
// Here goes the rest of the code handling the content in "page"
}我们现在所做的是添加
- 一个额外的字符串数组,用于显示城市和
- 一个for-loop,对所述数组进行迭代,以获取每个定义的城市条目的广告。
瞧,我们现在为每个城市单独运行请求。
参数的传递
到目前为止,我们对iPhone的搜索列表相当满意,但如果我们想把搜索范围缩小一点呢?
幸运的是,Craigslist确实为你提供了按特定标准过滤搜索的能力。例如,你可以告诉它只返回有图片的广告。或者,你可能只对今天发布的广告感兴趣。
一旦你勾选了这两个框,你会注意到地址栏中的URL变成了
https://newyork.craigslist.org/search/moa?hasPic=1&postedToday=1&query=iphone%2013
这个URL与我们之前使用的相当相似,但我们现在在查询字符串中还有两个参数。
hasPic的值为1,表示只返回有图片的广告。
postedToday的值为1,表示只应返回今天的广告。
有了这个网址,我们将只得到今天发布的、带图片的房源。不错,是吗?
但是,等等,还有更多。除了刚才提到的两个参数外,你还可以指定以下内容,以进一步缩小搜索范围。
srchType的值为T,只搜索广告的标题。
bundleDuplicates的值为1,用于捆绑同一卖家的广告。
searchNearby的值为1,以包括有关城市的附近地区。
以下网址将返回今天发布的所有广告,并将文本搜索限制在标题上。
https://newyork.craigslist.org/search/moa?query=iphone%2013&postedToday=1&srchType=T
输出定制
您可能会遇到这样的情况:您的爬虫可能必须支持不同的输出格式。例如,你可能必须支持JSON和CSV。在这种情况下,你可以简单地在你的代码中添加一个开关,根据其值来改变输出格式。
String outputType = argv.length == 1 ? argv[0] : "";
for(HtmlElement htmlItem : items){
HtmlAnchor itemAnchor = ((HtmlAnchor) htmlItem.getFirstByXPath(".//p[@class='result-info']/a"));
HtmlElement spanPrice = ((HtmlElement)htmlItem.getFirstByXPath(".//a/span[@class='result-price']"));
// It is possible that an item doesn't have any
// price, we set the price to 0.0 in this case
String itemPrice = spanPrice == null ? "0.0" : spanPrice.asText();
switch (outputType)
{
case "json":
Item item = new Item();
item.setTitle(itemAnchor.asText());
item.setUrl(baseUrl + itemAnchor.getHrefAttribute());
item.setPrice(new BigDecimal(itemPrice.replace("$", "")));
ObjectMapper mapper = new ObjectMapper();
String jsonString = mapper.writeValueAsString(item);
System.out.println(jsonString);
break;
case "csv":
// TODO: CSV-escaping
System.out.println(String.format("%s,%s,%s", itemAnchor.asText(), itemPrice, baseUrl + itemAnchor.getHrefAttribute()));
break;
default:
System.out.println("Error: no format specified");
break;
}
}
[文中代码源自Scrapingbee]如果你现在把json作为爬虫调用的第一个参数,它将为每个条目返回一个JSON对象(就像我们最初在Mapping下显示的那样)。如果你传递csv,它将为每个条目打印一个用逗号分隔的行。
接下来的步骤
到目前为止提到的例子提供了一点关于如何爬取Craigslist的见解,但肯定仍有一些可以改进的地方。
- 正确处理分页
- 支持一个以上的标准
- 以及更多
当然,爬取的内容很多,不仅仅是获取一个HTML页面和运行几个XPath表达式。特别是当涉及到分布式爬取、完全处理JavaScript和验证码时,这个话题会很快变得非常复杂。
甚至更多
不要被封锁
还可以查看我们最近的博客文章《如何进行网页爬取而不被阻止》,其中详细介绍了如何优化你的爬取方法,以避免被反爬取措施所阻止。
用Chrome浏览器进行爬取,完全支持JavaScript
虽然HtmlUnit是一个很好的无头浏览器,但你可能还是想看看我们的另一篇关于无头浏览器介绍的文章,因为这将为你提供更多关于如何使用Chrome无头模式的见解,该模式具有完整的JavaScript支持,就像你对日常驱动浏览器的期望那样。
请提供一个CSS选择器
如今,CSS选择器的用途远不止是应用颜色和间距。很多时候,它们与XPath表达式的使用环境相同。
也许是Python?
在这一点上,Python已经是多年来最流行的语言之一,事实上,它也常用于网页抓取。如果Python是你选择的语言,你可能就会喜欢我们关于使用Python爬取网页的其他指南。

