

在这篇文章中,我们将介绍几乎所有在Python中进行网络抓取的工具,它可以作为我们关于网页爬取而不被阻止的指南的后续文章来阅读。我们将从基本的到高级的,涵盖每个工具的优点和缺点。当然,我们不可能涵盖我们讨论的每个工具的每一个方面,但是这篇文章应该让你对每个工具的作用和何时使用一个工具有一个很好的概念。
网络基础知识
互联网是复杂的:在浏览器中查看一个简单的网页,涉及许多底层技术和概念。这篇文章的目的不是要对这些方面的每一个细节进行深入研究,而是要为你提供用 Python 从网络中提取数据的最重要的部分。
超文本传输协议
超文本传输协议(HTTP)使用客户/服务器模型。一个HTTP客户端(浏览器、你的Python程序、cURL、Requests等库……)打开一个连接,向一个HTTP服务器(Nginx、Apache……)发送消息(”我想看那个页面:/product”)。然后,服务器回答一个响应(例如HTML代码)并关闭连接。
HTTP被称为无状态协议,因为每个交易(请求/响应)是独立的。例如,FTP是有状态的,因为它维护连接。
基本上,当你在浏览器中输入一个网站地址时,HTTP请求看起来像这样。
GET /product/ HTTP/1.1 Host: example.com Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Encoding: gzip, deflate, sdch, br Connection: keep-alive User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36
在这个请求的第一行,你可以看到以下内容。
HTTP方法或动词。在我们的例子中是GET,表示我们想获取数据。还有很多其他的HTTP方法(例如,用于上传数据),这里有一个完整的列表。
我们想与之互动的文件、目录或对象的路径。在这里的情况下,目录产品就在根目录下面。
HTTP协议的版本。在本教程中,我们将专注于HTTP 1。
多个头文件字段。连接,用户代理…以下是HTTP头的详尽列表
以下是最重要的标头字段。
- 主机。这个头表示你要发送请求的主机名。这个头对基于名字的虚拟主机特别重要,这也是当今主机世界的标准。
- 用户代理(User-Agent)。这包含了关于发起请求的客户端的信息,包括操作系统。在这种情况下,它是我在MacOS上的网络浏览器(Chrome)。这个标头很重要,因为它要么用于统计(有多少用户在手机上与桌面上访问我的网站),要么用于防止机器人的侵犯。因为这些标头是由客户发送的,它们可以被修改(”标头欺骗”)。这正是我们将对我们的搜刮器所做的–使我们的搜刮器看起来像一个普通的网络浏览器。
- Accept。这是一个MIME类型的列表,客户端将接受这些类型作为服务器的响应。有很多不同的内容类型和子类型:text/plain, text/html, image/jpeg, application/json…
- Cookie:这个头域包含一个名-值对列表(name1=value1;name2=value2)。Cookie是网站在你的机器上存储数据的一种方式。这可能是到某个到期日(标准cookies),或者只是暂时的,直到你关闭浏览器(会话cookies)。Cookies被用于许多不同的目的,从认证信息到用户偏好,再到更邪恶的事情,如用个性化的、独特的用户标识符进行用户跟踪。然而,它们是提到认证的一个重要的浏览器功能。当你提交一个登录表格时,服务器将验证你的凭证,如果你提供了一个有效的登录,就会发出一个会话cookie,清楚地识别你特定用户账户的用户会话。您的浏览器将收到该cookie,并将其与所有后续请求一起传递。
- Referer。Referer的标头(请注意这个错别字)包含了请求实际URL的URL。这个标头很重要,因为网站使用这个标头,根据用户的来源改变其行为。例如,很多新闻网站都有付费订阅,只让你查看文章的10%,但如果用户来自像Reddit这样的新闻聚合网站,他们会让你查看全部内容。他们使用推荐人来检查这一点。有时我们将不得不欺骗这个头,以获得我们想要提取的内容。
这个列表还在继续……你可以在这里找到完整的头文件列表。
一个服务器会有这样的回应。
HTTP/1.1 200 OK Server: nginx/1.4.6 (Ubuntu) Content-Type: text/html; charset=utf-8 Content-Length: 3352 ...[HTML CODE]
在第一行,我们有一个新的信息,HTTP代码200 OK。代码为200意味着请求被正确处理。你可以在维基百科上找到一个所有可用代码的完整列表。在状态行之后,是响应头信息,其作用与我们刚才讨论的请求头信息相同。在响应头之后,你会有一个空白行,然后是与该响应一起发送的实际数据。
一旦你的浏览器收到该响应,它将解析HTML代码,获取所有嵌入的资产(JavaScript和CSS文件、图像、视频),并将结果呈现在主窗口中。
我们将通过用Python执行HTTP请求的不同方式,从响应中提取我们想要的数据。
1.手动打开一个Socket并发送HTTP请求
Socket
在Python中执行HTTP请求的最基本方法是打开一个TCP socket,并手动发送HTTP请求。
import socket
HOST = 'www.google.com' # Server hostname or IP address
PORT = 80 # The standard port for HTTP is 80, for HTTPS it is 443
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (HOST, PORT)
client_socket.connect(server_address)
request_header = b'GET / HTTP/1.0\r\nHost: www.google.com\r\n\r\n'
client_socket.sendall(request_header)
response = ''
while True:
recv = client_socket.recv(1024)
if not recv:
break
response += str(recv)
print(response)
client_socket.close()现在我们有了HTTP响应,从其中提取数据的最基本方法是使用正则表达式。
正则表达式
正则表达式(也叫regex)是一种非常通用的工具,用于处理、解析和验证任意文本。正则表达式本质上是一个字符串,它使用标准的语法定义了一个搜索模式。例如,你可以快速识别一个网页上的所有电话号码。
与经典的搜索和替换相结合,正则表达式还允许你以相对简单的方式对动态字符串进行字符串替换。最简单的例子是,在网络爬取的背景下,可以用适当的小写字母替换格式不好的HTML文档中的大写字母标签。
你现在可能想知道为什么在 Python 中进行网络爬取时理解正则表达式很重要。这是一个公平的问题,毕竟有许多不同的Python模块可以用XPath和CSS选择器解析HTML。
在一个理想的语义世界里,数据很容易被机器读取,而且信息被嵌入到带有有意义的属性的相关HTML元素里面。但是,现实世界是混乱的。你经常会在一个<p>元素里面发现大量的文本。例如,如果你想提取大量文本内的特定数据(一个价格、一个日期、一个名字……),你将不得不使用正则表达式。
注意:这里有一个测试你的正则表达式的好网站:https://regex101.com/。另外,这里有一个很棒的博客,可以了解更多关于它们的信息。这篇文章只涵盖了你能用正则表达式做的一小部分事情。
当你有这样的数据时,正则表达式会很有用。
Price : 19.99$
我们可以用XPath表达式选择这个文本节点,然后用这种正则表达式来提取价格。
^Price\s*:\s*(\d+\.\d{2})\$如果你只有HTML,那就有点麻烦了,但毕竟没有那么多麻烦。你可以简单地在表达式中指定标签,然后对文本使用一个捕获组。
import re html_content = '
Price : 19.99$
‘ m = re.match(‘
(.+)<\/p>’, html_content) if m: print(m.group(1))
正如你所看到的,用套接字手动发送HTTP请求,并用正则表达式解析响应是可以做到的,但它很复杂,有更高级别的API可以使这项任务更容易。
2. urllib3 & XPath
urllib3
免责声明:在Python中很容易迷失在urllib的世界中。标准库包含 urllib 和 urllib2 (有时还有 urllib3)。在 Python3 中,urllib2 被分割成多个模块,urllib3 很快就不会成为标准库的一部分。这种混乱的情况将是另一篇博文的主题。在这一部分,我决定只谈 urllib3,因为它在 Python 世界中被广泛使用,包括 Pip 和 Requests。
Urllib3 是一个高级包,允许你对 HTTP 请求做几乎任何你想做的事情。有了 urllib3,我们可以用更少的代码行做我们在上一节做的事情。
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)正如你所看到的,这比套接字版本要简明得多。不仅如此,API也很直白。而且,你可以很容易地做许多其他的事情,如添加HTTP头,使用代理,POST形式……
例如,如果我们决定设置一些头信息并使用代理,我们只需要做以下工作(你可以在bestproxyreviews.com了解更多关于代理服务器的信息)。
import urllib3
user_agent_header = urllib3.make_headers(user_agent="")
pool = urllib3.ProxyManager(f'', headers=user_agent_header)
r = pool.request('GET', 'https://www.google.com/')看到了吗?有完全相同的行数。然而,有一些事情是 urllib3 不太容易处理的。例如,如果我们想添加一个 cookie,我们必须手动创建相应的头信息并将其添加到请求中。
还有一些事情是 urllib3 可以做的,而 Requests 不能做:例如,创建和管理池和代理池,以及管理重试策略等。
简单地说,在抽象方面,urllib3 介于 Requests 和 Socket 之间,尽管它比 Socket 更接近于 Requests。
说实话,如果你要用 Python 做网络爬取,你可能不会直接使用 urllib3,特别是如果你是第一次使用。
接下来,为了解析响应,我们将使用 LXML 包和 XPath 表达式。
XPath
XPath 是一种技术,它使用路径表达式来选择 XML 文档(或 HTML 文档)中的节点或节点集。如果你熟悉CSS选择器的概念,那么你可以把它想象成相对类似的东西。
与文档对象模型一样,XPath自1999年以来一直是W3C的标准。尽管XPath本身不是一种编程语言,但它允许你编写表达式,可以直接访问一个特定的节点或特定的节点集,而不必穿过整个HTML树(或XML树)。
要用XPath从HTML文档中提取数据,我们需要三样东西。
- 一个HTML文档
- 一些XPath表达式
- 一个可以运行这些表达式的XPath引擎
首先,我们将使用我们从 urllib3 得到的 HTML。现在我们想从谷歌主页上提取所有的链接。所以,我们将使用一个简单的XPath表达式,//a,并且我们将使用LXML来运行它。LXML是一个快速且易于使用的XML和HTML处理库,支持XPath。
安装:
pip install lxml
下面是紧接在前一个片段之后的代码。
from lxml import html
# We reuse the response from urllib3
data_string = r.data.decode('utf-8', errors='ignore')
# We instantiate a tree object from the HTML
tree = html.fromstring(data_string)
# We run the XPath against this HTML
# This returns an array of element
links = tree.xpath('//a')
for link in links:
# For each element we can easily get back the URL
print(link.get('href'))而输出结果应该是这样的:
https://books.google.fr/bkshp?hl=fr&tab=wp https://www.google.fr/shopping?hl=fr&source=og&tab=wf https://www.blogger.com/?tab=wj https://photos.google.com/?tab=wq&pageId=none http://video.google.fr/?hl=fr&tab=wv https://docs.google.com/document/?usp=docs_alc ... https://www.google.fr/intl/fr/about/products?tab=wh
请记住,这个例子真的非常简单,并没有向你展示XPath的强大功能(注意:我们也可以使用/a/@href,直接指向href属性)。如果你想了解更多关于XPath的信息,你可以阅读这个有用的介绍。LXML文档也写得很好,是一个很好的起点。
XPath表达式,像正则表达式一样,功能强大,是从HTML中提取信息的最快方式之一。和正则表达式一样,XPath可以很快变得混乱,难以阅读,也难以维护。
3.Requests 与 BeautifulSoup
Requests
Requests是Python包中的王者。它有超过11,000,000次的下载,是Python中使用最广泛的包。
如果你正在构建你的第一个Python爬取器,我们建议从Requests和BeautifulSoup开始。
安装:
pip install requests
使用–双关语–Requests进行请求很容易:
使用Requests,很容易执行POST请求,处理cookies,查询参数…。你还可以用Request下载图片。
在下一页,你将学习如何使用带有代理的Request。这几乎是大规模搜刮网络的必修课。
对Hacker News进行认证
假设你正在构建一个Python刮刀,它可以自动将我们的博文提交给Hacker news或任何其他论坛,如Buffer。在发布我们的链接之前,我们需要在这些网站上进行认证。这就是我们要用Requests和BeautifulSoup来做的事情!
这里是Hacker News的登录表格和相关的DOM。
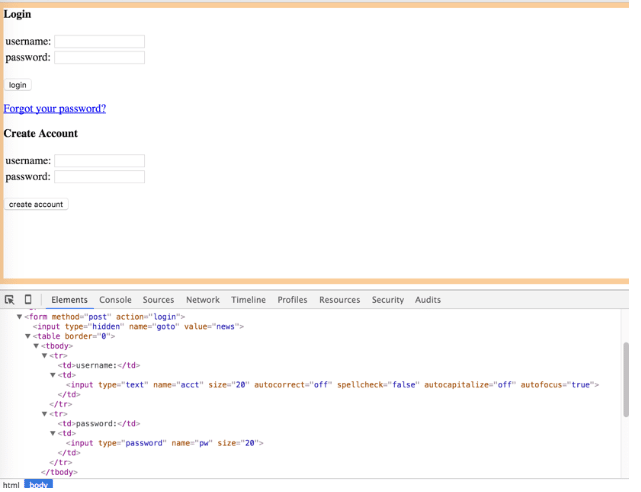
在这个表单上有三个带有名字属性的<input>标签(其他输入元素没有被发送)。第一个有一个隐藏的类型,名字是 “goto”,另外两个是用户名和密码。
如果你在你的Chrome浏览器内提交这个表单,你会看到有很多事情发生:一个重定向和一个cookie正在被设置。这个cookie将由Chrome在以后的每次请求中发送,以便服务器知道你已经通过了认证。
用Requests做这件事很容易。它将自动为我们处理重定向,而处理cookie可以用Session对象来完成
BeautifulSoup
我们接下来需要的是BeautifulSoup,它是一个Python库,将帮助我们解析服务器返回的HTML,以发现我们是否已经登录。
安装:
pip install beautifulsoup4
所以,我们要做的就是把这三个输入和我们的证书一起POST到/login端点,并检查是否存在一个只有在登录后才会显示的元素。
import requests
from bs4 import BeautifulSoup
BASE_URL = 'https://news.ycombinator.com'
USERNAME = ""
PASSWORD = ""
s = requests.Session()
data = {"goto": "news", "acct": USERNAME, "pw": PASSWORD}
r = s.post(f'{BASE_URL}/login', data=data)
soup = BeautifulSoup(r.text, 'html.parser')
if soup.find(id='logout') is not None:
print('Successfully logged in')
else:
print('Authentication Error')太棒了,只用了几行Python代码,我们就成功地登录了一个网站并检查了登录是否成功。现在,下一个挑战是:在主页上获得所有的链接。
顺便说一下,Hacker News提供了一个强大的API,所以我们是作为一个例子来做的,但你应该使用API,而不是搜刮它!
我们需要做的第一件事是检查Hacker News的主页,以了解其结构和我们要选择的不同CSS类。
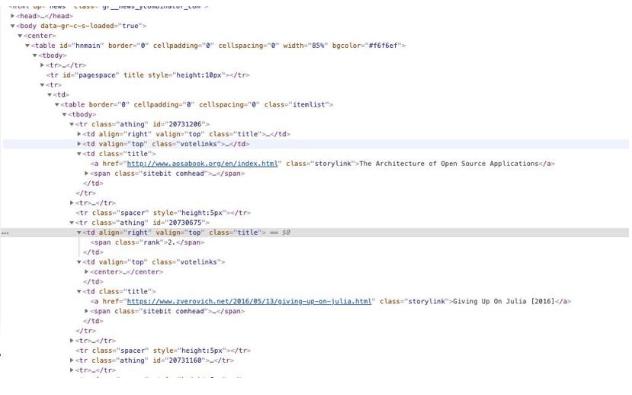
从截图中可以看出,所有的帖子都是<tr>标签的一部分,类别为thing。所以,让我们简单地找到所有这些标签。然而,我们也可以用一行代码来做这件事。
links = soup.findAll('tr', class_='athing')然后,对于每个链接,我们将提取其ID、标题、URL和等级。
import requests
from bs4 import BeautifulSoup
r = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
formatted_links = []
for link in links:
data = {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(link.find_all('td')[0].span.text.replace('.', ''))
}
formatted_links.append(data)
print(formatted_links)很好,只用了几行Python代码,我们就成功地加载了Hacker News的网站,并获得了所有发帖的细节。但是在我们的大数据之旅中,我们不仅想打印数据,实际上我们还想把它持久化。现在让我们试着让我们的Python scraper更强大一些吧!
在PostgreSQL中存储我们的数据
我们选择了一个好的关系型数据库作为我们的例子–PostgreSQL!
首先,我们需要一个有效的数据库实例。请查看www.postgresql.org/download,为你的操作系统选择合适的软件包,并按照其安装说明进行安装。一旦你安装了PostgreSQL,你就需要建立一个数据库(我们把它命名为scrape_demo),并为我们的Hacker News链接添加一个表(我们把它命名为hn_links),模式如下。
CREATE TABLE "hn_links" ( "id" INTEGER NOT NULL, "title" VARCHAR NOT NULL, "url" VARCHAR NOT NULL, "rank" INTEGER NOT NULL );
对于数据库的管理,你可以使用PostgreSQL自己的命令行客户端或可用的UI界面之一。
好了,数据库应该已经准备好了,我们可以再次转向我们的代码。
首先,我们需要一些能让我们与PostgreSQL对话的东西,Psycopg是一个真正伟大的库。像往常一样,你可以用pip快速安装它。
pip install psycopg2
剩下的就相对简单明了了。我们只需要获得连接
con = psycopg2.connect(host="127.0.0.1", port="5432", user="postgres", password="", database="scrape_demo")
该连接将允许我们获得一个数据库游标
cur = con.cursor()
一旦我们有了游标,我们就可以使用execute方法,来实际运行我们的SQL命令。
cur.execute("INSERT INTO table [HERE-GOES-OUR-DATA]")很好,我们已经把所有的东西都储存在数据库中了
请抓紧时间。不要忘记提交你的(隐式)数据库事务。再来一次con.commit()(和几次关闭),我们就真的可以开始了。
作为压轴戏,这里是完整的代码,包括之前的搜刮逻辑,这次是将所有内容存储在数据库中。
import psycopg2
import requests
from bs4 import BeautifulSoup
# Establish database connection
con = psycopg2.connect(host="127.0.0.1",
port="5432",
user="postgres",
password="",
database="scrape_demo")
# Get a database cursor
cur = con.cursor()
r = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
for link in links:
cur.execute("""
INSERT INTO hn_links (id, title, url, rank)
VALUES (%s, %s, %s, %s)
""",
(
link['id'],
link.find_all('td')[2].a.text,
link.find_all('td')[2].a['href'],
int(link.find_all('td')[0].span.text.replace('.', ''))
)
)
# Commit the data
con.commit();
# Close our database connections
cur.close()
con.close()总 结
正如你所看到的,Requests和BeautifulSoup是用于提取数据和自动化不同操作的伟大库,例如发布表单。如果你想运行大规模的网络爬取项目,你仍然可以使用Requests,但你需要自己处理很多部分。
就像很多时候一样,当然也有很多机会可以改进。
- 找到一种方法来并行化你的代码以使其更快
- 处理错误
- 过滤结果
- 节约你的请求,使你不至于让服务器过载
幸运的是,有一些工具可以为我们处理这些问题。
GRequests
虽然Requests包很容易使用,但如果你有数百个页面要搜刮,你可能会发现它有点慢。开箱后,它只允许你发送同步请求,这意味着如果你有25个URL要搜刮,你将不得不一个一个地做。
因此,如果一个页面需要10秒的时间来获取,那么获取这25个页面将需要4分钟以上。
import requests
# An array with 25 urls
urls = [...]
for url in urls:
result = requests.get(url)加快这一过程的最简单方法是同时进行几次调用。这意味着你可以不按顺序发送每个请求,而是以五次为一个批次发送请求。
在这种情况下,每个批次将同时处理五个URL,这意味着你将在10秒内搜刮五个URL,而不是50秒,或者在50秒内搜刮整个25个URL,而不是250。对于节省时间来说,这还不错。
通常情况下,这是用基于线程的并行性实现的。不过,一如既往,线程可能很棘手,特别是对初学者来说。幸运的是,有一个Requests包的版本为我们做了所有艰苦的工作,即GRequests。它以Requests为基础,但也结合了gevent,一个广泛用于网络应用的异步Python API。这个库允许我们以一种简单而优雅的方式同时发送多个请求。
对于初学者,让我们安装GRequests。
pip install grequests
现在,这里是如何分批发送我们的25个初始URL,每批5个。
import grequests
BATCH_LENGTH = 5
# An array with 25 urls
urls = [...]
# Our empty results array
results = []
while urls:
# get our first batch of 5 URLs
batch = urls[:BATCH_LENGTH]
# create a set of unsent Requests
rs = (grequests.get(url) for url in batch)
# send them all at the same time
batch_results = grequests.map(rs)
# appending results to our main results array
results += batch_results
# removing fetched URLs from urls
urls = urls[BATCH_LENGTH:]
print(results)
# [, , ..., , ]就这样了。GRequests对小脚本来说是完美的,但对生产代码或大规模的网络爬取来说就不太理想了。为此,我们有Scrapy。
4.网络抓取框架
Scrapy
Scrapy是一个强大的Python网络刮擦和网络爬行框架。它提供了很多异步下载网页的功能,并以各种方式处理和持久化其内容。它提供了对多线程、爬行(从一个链接到另一个链接以找到网站中的每一个URL的过程)、网站地图等的支持。
Scrapy也有一个互动模式,叫做Scrapy Shell。通过Scrapy Shell,你可以快速测试你的搜刮代码,确保你所有的XPath表达式或CSS选择器都能顺利工作。Scrapy的缺点是学习曲线很陡峭。有很多东西需要学习。
为了继续我们关于Hacker News的例子,我们要写一个Scrapy Spider,它可以搜刮前15页的结果,并将所有内容保存在一个CSV文件中。
你可以用pip轻松地安装Scrapy。
pip install Scrapy
然后你可以使用Scrapy CLI为我们的项目生成模板代码。
scrapy startproject hacker_news_scraper
在hacker_news_scraper/spider中,我们将创建一个新的 Python 文件,其中包含我们的蜘蛛代码。
from bs4 import BeautifulSoup
import scrapy
class HnSpider(scrapy.Spider):
name = "hacker-news"
allowed_domains = ["news.ycombinator.com"]
start_urls = [f'https://news.ycombinator.com/news?p={i}' for i in range(1,16)]
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
for link in links:
yield {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(link.td.span.text.replace('.', ''))
}在Scrapy中,有很多惯例。我们首先在start_urls中提供所有需要的URLs。然后Scrapy会获取每个URL,并为每个URL调用parse,在这里我们将使用我们的自定义代码来解析响应。
然后我们需要对Scrapy进行一些微调,以使我们的蜘蛛在目标网站上表现得很好。
# Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html AUTOTHROTTLE_ENABLED = True # The initial download delay AUTOTHROTTLE_START_DELAY = 5
你应该总是打开这个功能。基于响应时间,这个功能会自动调整请求率和并发线程的数量,确保你的蜘蛛不会被请求淹没在网站中。我们不希望这样,不是吗?
你可以用Scrapy CLI和不同的输出格式(CSV、JSON、XML…)运行这段代码。
scrapy crawl hacker-news -o links.json
就这样了!你现在有了所有的链接,而且是格式良好的JSON文件。
PySpider
PySpider是Scrapy的一个替代品,尽管有点过时了。它的最后一个版本是2018年的。然而,它仍然是相关的,因为它做了许多Scrapy无法处理的事情,开箱即用。
首先,PySpider可以很好地处理JavaScript页面(SPA和Ajax调用),因为它自带PhantomJS,一个无头浏览库。而在Scrapy中,你需要安装中间件才能做到这一点。除此之外,PySpider还带有一个漂亮的用户界面,可以很容易地监控你所有的抓取工作。
然而,由于一些原因,你可能还是喜欢使用Scrapy。
- 比PySpider好得多的文档,有易于理解的指南
- 一个内置的HTTP缓存系统,可以加快你的爬虫速度
- 自动的HTTP认证
- 支持3XX重定向,以及HTML meta refresh标签
5.无头浏览
Selenium & Chrome
Scrapy对于大规模的网络抓取任务来说是非常好的。然而,用它来处理那些大量使用JavaScript的网站是很困难的,例如,作为SPA(单页应用)。Scrapy不能独立处理JavaScript,只能得到静态的HTML代码。
一般来说,刮取SPA是很有挑战性的,因为经常有大量的AJAX调用和WebSocket连接。如果性能是一个问题,总是检查出JavaScript代码到底在做什么。这意味着用浏览器检查器手动检查所有的网络调用,并复制包含有趣数据的AJAX调用。
不过,通常情况下,涉及到的HTTP调用太多,无法获得你想要的数据,在无头浏览器中渲染页面会更容易。另一个很好的用例是对页面进行截图,这就是我们要用Hacker News主页(我们确实喜欢Hacker News,不是吗?)和Selenium的帮助来做的。
我不明白,什么时候我应该使用Selenium或不使用?
以下是你需要Selenium时最常见的三种情况。
- 你在寻找一个在浏览器上加载网页后几秒钟才出现的信息。
- 你要搜刮的网站使用了大量的JavaScript。
- 你想搜刮的网站有一些JavaScript检查来阻止 “经典 “的HTTP客户端。
你可以用pip来安装Selenium包。
pip install selenium
你还需要ChromeDriver。在mac操作系统上,你可以用brew来安装。
brew install chromedriver
然后,我们只需从Selenium包中导入Webdriver,用headless=True配置Chrome,设置一个窗口大小(否则会非常小),启动Chrome,加载页面,最后得到我们漂亮的屏幕截图。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=r'/usr/local/bin/chromedriver')
driver.get("https://news.ycombinator.com/")
driver.save_screenshot('hn_homepage.png')
driver.quit()诚然,作为好网民,我们当然也要退出()WebDriver实例。现在,你应该得到一个漂亮的主页截图。
然,你可以用Selenium API和Chrome浏览器做更多的事情。毕竟,它是一个完整的浏览器实例。
- 运行JavaScript
- 填写表格
- 点击元素
- 用CSS选择器/XPath表达式提取元素
Selenium和Chrome在无头模式下是刮取任何你想要的东西的终极组合。你可以自动完成所有你能在普通Chrome浏览器上完成的事情。
最大的缺点是,Chrome浏览器需要大量的内存/CPU能力。通过一些微调,你可以把每个Chrome实例的内存占用减少到300-400mb,但你仍然需要每个实例有一个CPU核心。
如果你需要同时运行几个实例,这将需要一台有足够硬件设置的机器,并有足够的内存为所有的浏览器实例服务。
RoboBrowser
RoboBrowser是一个Python库,它将Requests和BeautifulSoup包装成一个简单易用的软件包,并允许你编译自己的自定义脚本来控制RoboBrowser的浏览工作流程。它是一个轻量级的库,但它不是一个无头浏览器,仍然有我们前面讨论的Requests和BeautifulSoup的限制。
例如,如果你想登录Hacker-News,而不是用Requests手动制作一个请求,你可以写一个脚本,弹出表单并点击登录按钮。
# pip install RoboBrowser
from robobrowser import RoboBrowser
browser = RoboBrowser()
browser.open('https://news.ycombinator.com/login')
# Get the signup form
signin_form = browser.get_form(action='login')
# Fill it out
signin_form['acct'].value = 'account'
signin_form['password'].value = 'secret'
# Submit the form
browser.submit_form(signin_form)正如你所看到的,代码写得就像你在一个真正的浏览器中手动完成任务一样,尽管它不是一个真正的无头浏览库。
RoboBrowser很酷,因为它的轻量级方法允许你在你的电脑上轻松地并行化。然而,由于它没有使用真正的浏览器,它将无法处理像AJAX调用或单页应用程序这样的JavaScript。
不幸的是,它的文档也是轻量级的,我不会向新人或尚未使用BeautilfulSoup或RequestsAPI的人推荐它。
6.刮取Reddit的数据
有时你甚至不需要使用HTTP客户端或无头浏览器来搜刮数据。你可以直接使用目标网站所暴露的API。这就是我们现在要对Reddit的API进行的尝试。
为了访问API,我们将使用Praw,一个伟大的Python包,它包装了Reddit的API。
安装它:
pip install praw
然后,你将需要获得一个API密钥。进入https://www.reddit.com/prefs/apps。
滚动到底部,创建应用程序。
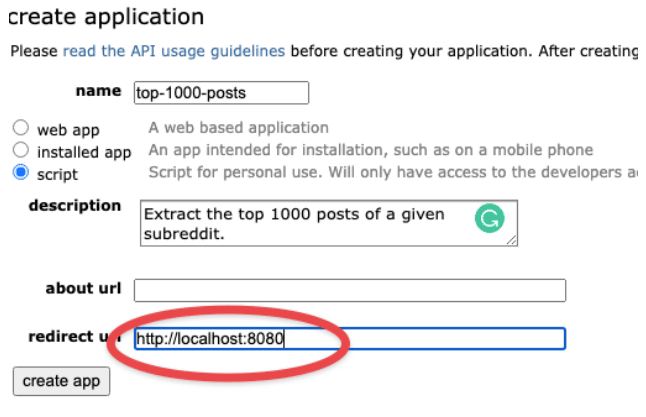
正如Praw的文档中所述,确保提供http://localhost:8080作为 “重定向URL”。
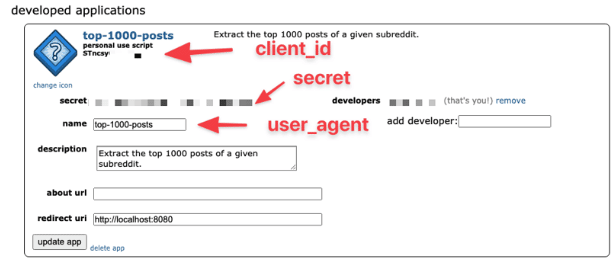
点击创建应用程序后,将加载带有API细节和证书的屏幕。在我们的例子中,你需要客户的ID、秘密和用户代理。
现在我们要从/r/Entrepreneur获取前1000个帖子,并将其导出为CSV文件。
import praw
import csv
reddit = praw.Reddit(client_id='you_client_id', client_secret='this_is_a_secret', user_agent='top-1000-posts')
top_posts = reddit.subreddit('Entrepreneur').top(limit=1000)
with open('top_1000.csv', 'w', newline='') as csvfile:
fieldnames = ['title','score','num_comments','author']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for post in top_posts:
writer.writerow({
'title': post.title,
'score': post.score,
'num_comments': post.num_comments,
'author': post.author
})
[文中代码均来源于Scrapingbee]正如你所看到的,实际提取部分只有一行Python代码。在subreddit上运行top,并将帖子存储在top_posts。
Praw还有很多其他用例。你可以做各种疯狂的事情,比如用情感分析库实时分析sub reddits,预测下一个$GME …
总 结
以下是我们在这篇博文中讨论的每一项技术的快速回顾表。
| 名称 | socket | urllib3 | requests | scrapy | selenium |
|---|---|---|---|---|---|
| 使用的便利性 | – – – | + + | + + + | + + | + |
| 灵活性 | + + + | + + + | + + | + + + | + + + |
| 执行的速度 | + + + | + + | + + | + + + | + |
| 常见用例 | * 编写低级别的编程接口 | * 需要对HTTP进行精细控制的高层应用(管道、AWS客户端、请求、流媒体)。 | * 调用一个API * 简单的应用(就HTTP需求而言) | * 抓取一个重要的网站列表 * 筛选、提取和加载搜刮的数据 | * JS渲染 * 刮取SPA * 自动测试 * 程序化截图 |
| 了解更多 | *官方文档 *伟大的教程 | *官方文档 *urllib3的PIP用法 | *官方文档 *Requests使用urllib3 | *官方文档 | *官方文档 *爬取SPA |
我希望你喜欢这篇博文!这是对最常用的网络爬取的Python工具的快速介绍。在接下来的文章中,我们将更深入地介绍所有的工具或主题,比如XPath和CSS选择器。

