

在这篇文章中,我们将看到如何利用BeautifulSoup和CSS选择器从网页中提取结构化信息。
获取HTML
BeautifulSoup本身不是一个网络爬取库。它是一个允许你有效和容易地从HTML中提取信息的库。在现实世界中,它经常被用于网络爬取项目。
所以,对于初学者来说,我们需要一个HTML文档。为此,我们将使用Python的Requests包,获取HackerNews的主页面。
import requests
response = requests.get("https://news.ycombinator.com/")
if response.status_code != 200:
print("Error fetching page")
exit()
else:
content = response.content
print(content)
> b' content="width=device-width, initial-scale=1.0">用BeautifulSoup解析HTML
现在,HTML已经可以访问,我们将使用BeautifulSoup来解析它。如果你还没有,你可以通过简单的pip install beautifulsoup4 来安装该软件包。在本文的其余部分,我们将把BeautifulSoup4称为 “BS4″。
我们现在需要解析HTML,并将其加载到BS4结构中。
from bs4 import BeautifulSoup soup = BeautifulSoup(response.content, 'html.parser')
这个soup 对象非常方便,使我们能够轻松地访问许多有用的信息,如:
# The title tag of the page
print(soup.title)
>
# The title of the page as string
print(soup.title.string)
> Hacker News
# All links in the page
nb_links = len(soup.find_all('a'))
print(f"There are {nb_links} links in this page")
> There are 231 links in this page
# Text from the page
print(soup.get_text())
> Hacker News
> Hacker News
> new | past | comments | ask | show | jobs | submit
> login
> ...瞄准DOM元素
你可能开始看到一个如何使用这个库的模式。它允许你快速而优雅地锁定你需要的DOM元素。
如果你需要从它的标签中选择DOM元素(<p>,<a>,<span>, ….),你可以简单地做soup.<tag>来选择它。需要注意的是,它只能选择带有该标签的第一个HTML元素。
例如,如果我想要第一个链接,我只需要访问我的BeautifulSoup对象的a字段:
 该元素是该标签的完整表示,并带有相当多的HTML特定方法
该元素是该标签的完整表示,并带有相当多的HTML特定方法# The text of the link print(first_link.text) # Empty because first link only contains antag >"" # The href of the link print(first_link.get('href') > https://news.ycombinator.com
这是一个简单的例子。如果你想根据第一个元素的id或class属性来选择它,这并不难。
pagespace = soup.find(id="pagespace") print(pagespace) >
# class is a reserved keyword in Python, hence the ‘_’ athing = soup.find(class_=”athing”) print(athing) >
> ...
如果你不想要第一个匹配的元素,而是想要所有匹配的元素,只要用find_all替换find。
这个简单而优雅的界面允许你快速编写简短而强大的Python片段。例如,假设我想提取这个页面的所有链接,并找到页面上出现最多的前三个链接。我所要做的就是这样。
from collections import Counter
all_hrefs = [a.get('href') for a in soup.find_all('a')]
top_3_links = Counter(all_hrefs).most_common(3)
print(top_3_links)
> [('from?site=github.com', 3), ('item?id=22115671', 2), ('item?id=22113827', 2)]动态元素选择
到目前为止,我们总是传递一个静态标签类型,然而find_all的功能更多,也支持动态选择。例如,我们可以传递一个函数引用,find_all将为每个元素调用你的函数,并且只在你的函数返回真值时才包括该元素。
在下面的代码示例中,我们定义了一个函数my_tag_selector,它接受一个标签参数,只有当它得到一个带有 HTML 类titlelink 的<a>标签时才返回true。从本质上讲,我们只从主页面提取文章链接。
import requests
from bs4 import BeautifulSoup
import re
def my_tag_selector(tag):
# We only accept "a" tags with a titlelink class
return tag.name == "a" and tag.has_attr("class") and "titlelink" in tag.get("class")
response = requests.get("https://news.ycombinator.com/")
if response.status_code != 200:
print("Error fetching page")
exit()
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.find_all(my_tag_selector))
>[find_all并不只支持静态字符串作为过滤器,而是遵循一种通用的 “真实性 “方法,你可以传递不同类型的表达式,它们只需要评估为真即可。除了标签字符串和函数之外,目前还支持正则表达式和列表。除了find_all之外,还有其他的函数来导航DOM树,例如选择下面的DOM兄弟姐妹或元素的父级。
BeautifulSoup是一个很好的例子,它是一个既容易使用又强大的库。到目前为止,我们主要讨论了选择和寻找元素,但你也可以改变和更新整个DOM树。不过,这些内容我们不会在这篇文章中涉及,因为现在是CSS选择器的时间。
CSS选择器
如果BeautifulSoup已经有办法根据元素的属性来选择它们,为什么还要学习CSS选择器呢?
嗯,你很快就会明白。
查询DOM
通常情况下,DOM元素没有适当的ID或类名。虽然完全有可能(请看我们以前的例子),但在这种情况下选择元素可能相当繁琐,需要很多手动步骤。
例如,假设你想提取HN主页上一个帖子的分数,但你不能在代码中使用类名或ID。下面是你可以做的。
results = []
all_tr = soup.find_all('tr')
for tr in all_tr:
if len(tr.contents) == 2:
print(len(tr.contents[1]))
if len(tr.contents[0].contents) == 0 and len(tr.contents[1].contents) == 13:
points = tr.contents[1].text.split(' ')[0].strip()
results.append(points)
print(results)
>['168', '80', '95', '344', '7', '84', '76', '2827', '247', '185', '91', '2025', '482', '68', '47', '37', '6', '89', '32', '17', '47', '1449', '25', '73', '35', '463', '44', '329', '738', '17']正如承诺的那样,相当啰嗦,不是吗?
这正是CSS选择器发挥作用的地方。它们允许你将你的循环和ifs分解成一个表达式。
all_results = soup.select('td:nth-child(2) > span:nth-child(1)')
results = [r.text.split(' ')[0].strip() for r in all_results]
print(results)
>['168', '80', '95', '344', '7', '84', '76', '2827', '247', '185', '91', '2025', '482', '68', '47', '37', '6', '89', '32', '17', '47', '1449', '25', '73', '35', '463', '44', '329', '738', '17']这里的关键是td:nth-child(2) > span:nth-child(1)。这为我们选择了第一个 ,它是
的直接子元素,而
本身必须是其父元素(
)的第二个元素。下面的HTML说明了我们的选择器的一个有效的DOM摘录。
not the second child, are we?
HERE WE GO
this time not the first span
很容易调试
使得CSS选择器非常适合于网络爬取的另一点是,它们很容易被调试。让我们来看看。
在Chrome或Firefox中打开开发者工具(F12),选择文档标签,并使用Ctrl/⌘+F打开搜索栏。现在输入任何CSS表达式(例如:html body),浏览器将找到第一个匹配的元素。按回车键将遍历这些元素。
最棒的是,它也可以反过来使用。右键单击DOM检查器中的任何元素,从上下文菜单中选择复制—复制选择器。
高级表达法
CSS选择器提供了一个全面的语法来选择各种设置中的元素。
子女和后代
子代和孙代选择器允许你选择作为一个给定的父元素的直接或间接子代的元素。
# all
directly inside of an a > p # all
descendants of an a p
而且你可以把它们混在一起:
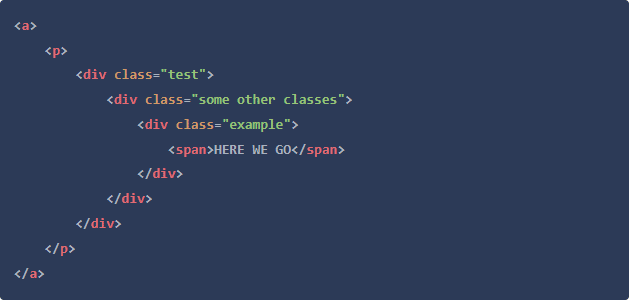
a > p > .test .example > span
这个选择器在这个HTML片段中可以完全正常工作:
兄弟姐妹
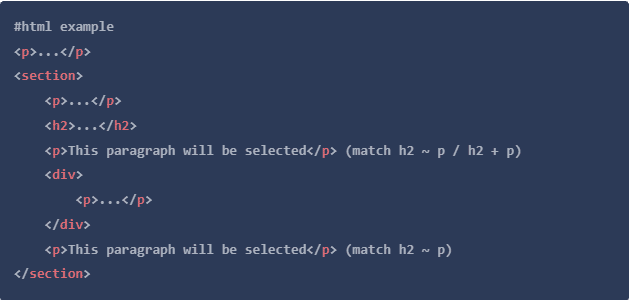
这个是我最喜欢的一个,因为它允许你根据DOM层次结构中同级别的元素来选择元素,因此有兄弟姐妹表达式。
属性选择器
属性选择器允许你选择具有特定属性值的元素。因此,p[data-test="foo"]将匹配

伪类
让我们假设我们有这个HTML文档。 
此外,让我们假设我们只想选择一个特定的<p>元素。欢迎来到伪类!
例如,伪类,如 :first-child,:last-child, 和:nth-child,允许你通过它们在DOM树中的位置选择特定的元素。

还有很多其他的伪类(比如input[type="checkbox"]:checked会选择所有的checkbox),你可以在这里找到一个完整的列表。如果你想了解更多关于CSS选择器的知识,你可能会发现这篇文章很有趣。
可维护的代码
我还认为,CSS表达式更容易维护。例如,在ScrapingBee,当我们做自定义网络刮削任务时,我们所有的脚本都是这样开始的。
TITLE_SELECTOR = "title" SCORE_SELECTOR = "td:nth-child(2) > span:nth-child(1)" ... [文中代码源自Scrapingbee]
这使得在对DOM进行修改时,可以很容易地修复脚本。
当然,确定正确的CSS选择器的一个相当简单的方法是,当你右击一个元素时,简单地复制/粘贴Chrome给你的信息。然而,你应该小心,因为这些选择器的路径往往是非常 “绝对 “的,而且往往既不是最有效的,也不是对DOM变化有很强的适应性。一般来说,在你的脚本中使用这些选择器之前,最好先手动验证它们。
我们发布了一个新功能,使整个过程变得更加简单。你现在可以通过一个简单的API调用从HTML中提取数据。请随意查看文档。如果您想尝试一下ScrapingBee,我们很乐意免费提供前1000个API调用。
总 结
BeautifulSoup和CSS选择器提供了一种非常优雅和轻量级的方法来从Python脚本中运行你的网络爬取工作。特别是,CSS是一种在Python领域之外使用的技术,它绝对值得添加到一个人的工具列表中。
我希望你喜欢这篇关于Python中的网络刮削的文章,它将使你的生活更轻松。如果你想阅读更多关于Python中的网页抓取,请不要犹豫,查看我们Python网页爬取指南。

