

假设你想从一个网站获得一些信息,如股票价格、最新的广告或最新的帖子。最简单的方法是连接到一个API。如果该网站有免费使用的API,你可以直接请求你需要的信息。
如果没有,还有第二个选择:网页爬取。
与其连接到一个 “官方 “资源,你可以使用一个机器人来抓取网站的内容,并解析它们以找到你需要的东西。
在这篇文章中,你将学习如何用Rust编程语言实现网页爬取。你将使用两个Rust库,reqwest和scraper,从IMDb上抓取前一百名电影列表。
在Rust中实现网页爬取器
你将在Rust中建立一个功能完备的网页爬取器。你的爬取目标将是IMDb,一个关于电影、电视剧和其他媒体的数据库。
最后,你会有一个Rust程序,可以在任何时候按用户评分搜出前一百部电影。
本教程假设你已经安装了Rust和Cargo(Rust的软件包管理器)。如果你没有,请按照官方文档来安装它们。
创建项目并添加依赖性
首先,你需要创建一个基本的Rust项目,并添加所有你要使用的依赖项。这最好用Cargo来完成。
要为一个Rust二进制文件生成一个新的项目,请运行:
cargo new web_scraper
接下来,将所需的库添加到依赖项中。对于这个项目,你将使用reqwest和scraper。
在你喜欢的代码编辑器中打开web_scraper文件夹,并打开cargo.toml文件。在文件的末尾,添加库的内容。
[dependencies]
reqwest = {version = "0.11", features = ["blocking"]}
scraper = "0.12.0"现在你可以移动到src/main.rs并开始创建你的网页爬虫。
获取网站HTML
爬取页面通常包括获取页面的HTML代码,然后解析它以找到你需要的信息。因此,你需要在你的Rust程序中提供IMDb页面的代码。要做到这一点,你首先需要了解浏览器的工作原理,因为它们是你与网页互动的常用方式。
为了在浏览器中显示一个网页,浏览器(客户端)向服务器发送一个HTTP请求,服务器以网页的源代码作为回应。然后,浏览器就会渲染这些代码。
HTTP有各种不同类型的请求,如GET(用于获取资源的内容)和POST(用于向服务器发送信息)。为了在你的Rust程序中获得IMDb网页的代码,你需要模仿浏览器的行为,向IMDb发送一个HTTP GET请求。
在Rust中,你可以使用reqwest来实现。这个常用的Rust库提供了一个HTTP客户端的功能。它可以做很多普通浏览器能做的事情,比如打开网页、登录和存储cookies。
要请求一个页面的代码,你可以使用reqwest::blocking::get方法。
fn main() {
let response = reqwest::blocking::get(
"https://www.imdb.com/search/title/?groups=top_100&sort=user_rating,desc&count=100",
)
.unwrap()
.text()
.unwrap();
}响应现在将包含你请求的页面的完整HTML代码。
从HTML中提取信息
网页爬取项目中最难的部分通常是将你需要的特定信息从HTML文档中获取。为此,Rust中一个常用的工具是scraper库。它的工作原理是将HTML文档解析成一个树状结构。你可以使用CSS选择器来查询你所感兴趣的元素。
第一步是使用库来解析你的整个HTML文档。
let document = scraper::Html::parse_document(&response);
接下来,找到并选择你需要的部分。要做到这一点,你需要检查网站的代码,找到唯一能识别这些项目的CSS选择器集合。
最简单的方法是通过你的普通浏览器来做。找到你需要的元素,然后通过检查该元素的代码。
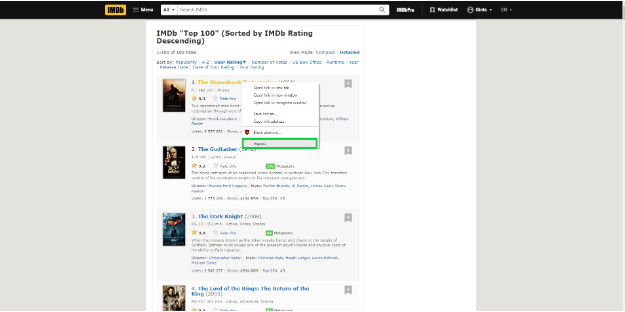
就 IMDb 而言,你需要的元素是电影的名字。当你检查这个元素时,你会发现它被包裹在一个<a>标签中。

不幸的是,这个标签不是唯一的。由于页面上有很多的<a>标签,把它们都爬取出来并不是一个聪明的主意,因为其中大部分都不是你需要的项目。相反,找到电影标题特有的标签,然后导航到该标签内的<a>标签。
在这种情况下,你可以选择lister-item-header类。

现在你需要使用scraper::Selector::parse方法创建一个查询。
你将给它一个h3.ister-item-header>a选择器。换句话说,它可以找到以<h3 >标签作为父标签的<h3>标签,该标签属于list-item-header类。
使用以下查询:
let title_selector = scraper::Selector::parse("h3.lister-item-header>a").unwrap();现在你可以用select方法将这个查询应用到你解析过的文档中。为了得到电影的实际标题而不是HTML元素,你要把每个HTML元素映射到它里面的HTML。
let titles = document.select(&title_selector).map(|x| x.inner_html());
titles现在是一个迭代器,持有所有前100个标题的名字。
你现在需要做的就是打印出这些名字。要做到这一点,首先用数字1到100来压缩你的标题列表。然后对产生的迭代器调用for_each方法,将迭代器中的每个项目打印在单独的一行上。
titles
.zip(1..101)
.for_each(|(item, number)| println!("{}. {}", number, item));你的网页爬取器现在已经完成。
以下是该爬取器的完整代码:
fn main() {
let response = reqwest::blocking::get(
"https://www.imdb.com/search/title/?groups=top_100&sort=user_rating,desc&count=100",
)
.unwrap()
.text()
.unwrap();
let document = scraper::Html::parse_document(&response);
let title_selector = scraper::Selector::parse("h3.lister-item-header>a").unwrap();
let titles = document.select(&title_selector).map(|x| x.inner_html());
titles
.zip(1..101)
.for_each(|(item, number)| println!("{}. {}", number, item));
}如果你保存该文件并使用cargo run来运行它,你应该在任何时候都能得到前一百名的电影列表。
1. The Shawshank Redemption 2. The Godfather 3. The Dark Knight 4. The Lord of the Rings: The Return of the King 5. Schindler's List 6. The Godfather: Part II 7. 12 Angry Men 8. Pulp Fiction 9. Inception 10. The Lord of the Rings: The Two Towers ... [文中代码源自Scrapingbee]
总 结
在本教程中,你学会了如何使用Rust来创建一个简单的网页爬取器。Rust并不是一种流行的脚本语言,但正如你所看到的,它能很容易地完成工作。
这只是Rust网页爬取的一个起点。根据你的需要,你可以用很多方法来升级这个爬取器。
这里有一些选择,你可以尝试一下,作为一种练习。
- 将数据解析到一个自定义结构中。你可以创建一个类型化的Rust结构来保存电影数据。这将使你更容易打印数据并在你的程序中进一步处理它。
- 将数据保存在一个文件中。你可以不打印出电影数据,而是将其保存在文件中。
- 创建一个登录到IMDb账户的
客户端。你可能希望IMDb在你解析电影之前根据你的喜好来显示电影。例如,IMDb以你居住的国家的语言显示电影标题。如果这是一个问题,你将需要配置你的IMDb偏好,然后创建一个可以登录和爬取偏好的网络爬虫。
然而,有时使用CSS选择器是不够的。你可能需要一个更高级的解决方案来模拟真实浏览器所采取的行动。在这种情况下,你可以使用thirtyfour,Rust的UI测试库,来实现更强大的网页爬取动作。
如果你喜欢低级语言,你可能也会喜欢我们的用C++进行网页爬取。

