

对于任何用C#从网络上提取内容并将其解析为可用格式的项目,你很可能会发现HTML Agility Pack。Agility Pack是用C#解析HTML内容的标准,因为它有几个方法和属性,可以方便地与DOM一起工作。
与其自己编写解析引擎,HTML Agility Pack拥有你所需要的一切,可以找到特定的DOM元素,遍历子节点和父节点,并检索指定元素中的文本和属性(例如HREF链接)。
第一步是在创建C# .NET项目后安装HTML Agility Pack。在这个例子中,我们使用一个.NET Core MVC网络应用。要安装Agility Pack,你需要使用NuGet。NuGet在Visual Studio界面中可以使用,进入工具->NuGet包管理器->管理解决方案的NuGet包。
在这个窗口中,搜索HTML Agility Pack,并将其安装到解决方案的依赖项中。安装后,你会注意到解决方案中的依赖关系,你会发现在你的使用语句中引用了它。如果你在使用语句中没有看到引用,你必须在每个使用Agility Pack的代码文件中添加以下一行:
using HtmlAgilityPack;
使用本地C#库从网页中提取HTML
安装了Agility Pack依赖项后,现在可以练习解析HTML了。在本教程中,我们将使用Hacker News。这是一个很好的例子,因为它是一个动态的页面,上面有热门链接的列表,可以供浏览者阅读。我们将采取Hacker News上的前10个链接,解析HTML并将其放入一个JSON对象。
在你爬取一个页面之前,你应该了解它的结构,并看一下页面上的代码。这可以在浏览器中使用 “检查元素 “选项来完成。我们使用的是Chrome浏览器,但这个功能在FireFox和Edge中也可用。右键单击并检查Hacker News上第一个链接的元素。
你会注意到,链接包含在一个表格中,每个标题都被列在一个表格行中,有特定的类名。这些类名可以用来在你爬取页面时拉出每个DOM元素内的内容。
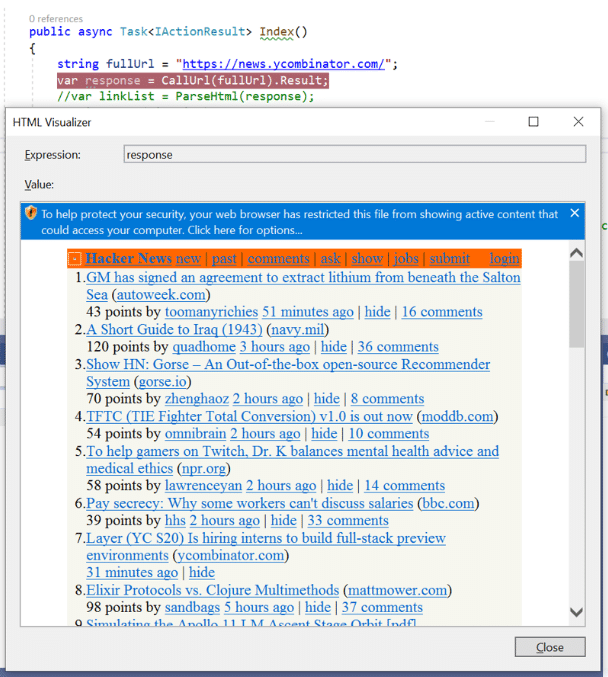
上图中被圈起来的元素显示了可以用来从DOM的其他部分解析元素的类。title类包含在页面上显示的主标题的元素,rank类显示标题的等级。storylink和score类也包含了关于链接的重要信息,我们可以将其添加到JSON对象中。
我们还想针对特定的DOM元素属性,包含我们需要的信息。<a>和<span>元素包含我们想要的内容,Agility Pack可以从DOM中提取它们并显示内容。
现在我们了解了页面的DOM结构,我们可以编写代码,拉出Hacker News的主页。在开始之前,在你的代码中添加以下using语句:
using HtmlAgilityPack; using System.Net.Http; using System.Net.Http.Headers; using System.Threading.Tasks; using System.Net; using System.Text;
有了using语句,你可以写一个小方法,动态地拉出任何网页,并将其加载到一个名为response的变量中。下面是一个使用本地库在C#中拉取网页的例子:
string fullUrl = "https://news.ycombinator.com/";
var response = CallUrl(fullUrl).Result;
private static async Task CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls13;
client.DefaultRequestHeaders.Accept.Clear();
var response = client.GetStringAsync(fullUrl);
return await respons你可以通过设置断点和使用HTML Visualizer查看内容来检查,以确保网页内容被拉出。
使用Agility Pack解析HTML
将HTML加载到一个变量中,现在可以用Agility Pack来解析它。你有两个主要选择。
- 使用XPath和SelectNodes
- 使用LINQ
当你想通过节点搜索来寻找特定的内容时,LINQ就很有用。XPath选项是Agility Pack特有的,被大多数开发者用来遍历几个元素。我们要用LINQ得到前10个故事,然后用XPath解析子元素,得到每个子元素的具体属性,并将其加载到JSON对象中。
我们使用JSON对象,因为它是一种通用语言,可以跨平台、API和编程语言使用。大多数系统都支持JSON,所以如果你需要的话,这是一个与外部应用程序合作的简单方法。
我们将创建一个新的方法来解析HTML。下面是这个新方法,它有一个LINQ查询,用来提取所有类名为 “thing “的项目和它们的子元素:
private void ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
}这段代码将HTML加载到Agility PackHtmlDocument 对象中。使用LINQ,我们拉出了所有类名中含有atthing的 tr元素。Take()方法告诉LINQ查询只从列表中抽取前10个。LINQ使得提取特定数量的元素并将其加载到一个通用列表中变得更加容易。
我们不希望每个表格行中都有所有的元素,所以我们需要迭代每个项目,使用Agility Pack只提取故事标题、URL、排名和分数。我们将把这个功能添加到ParseHtml() 方法中,因为这个新功能是解析过程的一部分。
下面的代码显示了在一个foreach循环中增加的功能:
private void ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
}
上面的代码遍历了Hacker News上的所有前10名链接,得到了我们想要的信息,但它并没有对这些信息做任何处理。我们现在需要创建一个JSON对象来包含这些信息。一旦我们有了JSON对象,我们就可以把它传递给任何我们想要的东西–我们代码中的另一个方法、外部平台上的API,或者另一个可以摄取JSON的应用程序。
创建JSON对象的最简单方法是将其从一个类中序列化。你可以在与你在前面的例子中创建代码相同的命名空间中创建一个类。我们将创建一个名为HackerNewsItems 的类来加以说明。
在这个例子中,我们一直在创建的代码是在ScrapingBeeScraper.Controllers的命名空间中。你的命名空间可能与我们的不同,但你可以在文件顶部的using 语句下找到它。在你用于本教程的同一文件中创建HackerNewsItems 类,并返回到ParseHtml()方法,在那里我们将创建对象。
注意:要使用本教程的例子,你需要从NuGet安装Newtonsoft.JSON依赖项。你可以用安装Agility Pack的同样方法来安装它。还有其他几个用于序列化和反序列化对象的JSON库,但Newtonsoft库是最受C#编码者欢迎的。安装后,在你的代码中添加以下using 语句:
using Newtonsoft.Json;
随着HackerNewsItems类的创建,现在我们可以在解析方法中加入JSON代码来创建一个JSON对象。现在看一下ParseHtml()方法:
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List newsLinks = new List();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
注意上面的代码,HackerNewsItems 类是由解析过的HTML填充的。然后每个HackerNewsItems对象被添加到一个通用列表中,该列表将包含所有10个项目。方法返回 语句前的最后一条语句是Newtonsoft将通用列表变成JSON对象。
就是这样 — 你已经从Hacker News中提取了前10个新闻链接并创建了一个JSON对象。下面是从头到尾的完整代码,最终的JSON对象包含在linkList 变量中:
string fullUrl = "https://news.ycombinator.com/";
var response = CallUrl(fullUrl).Result;
var linkList = ParseHtml(response);
private static async Task CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls13;
client.DefaultRequestHeaders.Accept.Clear();
var response = client.GetStringAsync(fullUrl);
return await response;
}
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List newsLinks = new List();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
}注意,你也可以用Agility Pack从父节点中选择子节点。如果你想在DOM树上逐项拉动表格元素,HTML Agility Pack会使用各种方法向下追踪DOM层次。
使用Selenium和Chrome浏览器实例拉动HTML
在某些情况下,你需要将Selenium与浏览器一起使用,以便从一个页面中提取HTML。这是因为有些网站是用客户端代码来呈现结果的。由于客户端代码是在浏览器加载HTML和脚本之后执行的,所以前面的例子不会得到你需要的结果。为了模拟浏览器中的代码加载,你可以使用一个名为Selenium的库。Selenium可以让你用浏览器的可执行程序从页面中提取HTML,然后你可以用Agility Pack来解析HTML,方法和我们上面的一样。
在你能在浏览器中进行解析之前,你需要从NuGet中安装Selenium.WebDriver,并在项目中添加using 语句。安装完Selenium后,将以下using 语句添加到你的文件中:
using OpenQA.Selenium; using OpenQA.Selenium.Chrome;
注意:你必须将Selenium驱动程序的更新作为Chrome浏览器的更新。如果你收到错误 “SessionNotCreatedException:消息:会话未创建。这个版本的ChromeDriver只支持Chrome的xx版本”,其中 “xx “是Chrome的版本号,你必须更新项目中的Selenium库。
我们将使用前一个例子中的相同变量,但改变主要代码,用Selenium拉出HTML,并将其载入一个对象中:
string fullUrl = "https://news.ycombinator.com/";
var options = new ChromeOptions()
{
BinaryLocation = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
options.AddArguments(new List() { "headless", "disable-gpu" });
var browser = new ChromeDriver(options);
browser.Navigate().GoToUrl(fullUrl);
var linkList = ParseHtml(browser.PageSource);注意在上面的代码中,使用了同样的ParseHtml()方法,但这次我们把Selenium页面源作为一个参数来传递。BinaryLocation 变量指向Chrome的可执行文件,但你的路径可能不同,所以要确保它是你自己代码中的准确路径位置。通过重复使用相同的方法,你可以在使用本地C#库直接加载HTML和加载客户端内容并进行解析之间进行切换,而无需为每个事件编写新的代码。
下面是执行请求和解析HTML的完整代码:
string fullUrl = "https://news.ycombinator.com/";
var options = new ChromeOptions()
{
BinaryLocation = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
options.AddArguments(new List() { "headless", "disable-gpu" });
var browser = new ChromeDriver(options);
browser.Navigate().GoToUrl(fullUrl);
var linkList = ParseHtml(browser.PageSource);
```c#
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List newsLinks = new List();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
}
[文中代码源自Scrapingbee]代码仍然解析HTML,并将其转换为HackerNewsItems 类的JSON对象,但HTML是在加载到虚拟浏览器后解析的。在这个例子中,我们使用了带有Selenium的无头Chrome浏览器,但Selenium也有NuGet提供的无头FireFox的驱动。
目前,我们使用LINQ和XPath来选择CSS类,但Agility Pack的创建者承诺,CSS选择器即将到来。
最后的想法
HTML Agility Pack是一个很好的爬取网站的工具,但它缺少一些关键功能。例如,我们需要额外的库(Selenium)来爬取用SPA框架(如React.js、Angular.js或Vue.js)制作的单页面应用程序。
XPath也很重要,因为这种查询语言比CSS选择器要灵活得多。总的来说,它是一个很好的解析HTML的库,但你仍然需要额外的库来获得更多的灵活性。
我们的C#例子使用Agility Pack和Selenium进行单页应用,你也可以阅读我们关于用C#进行网页爬取教程。

