

网页爬取是每个开发者在其职业生涯的某个阶段都会使用的一个基本工具。因此,开发人员必须了解什么是网页爬取器,以及如何建立一个网页爬取器。维基百科对网页爬取的定义如下。
网页爬取、网络采集或网络数据提取是用于从网站中提取数据的数据爬取。网页爬取软件可以使用超文本传输协议或网络浏览器直接访问万维网。虽然网页爬取可以由软件用户手动完成,但该术语通常指的是使用机器人或网络爬虫实现的自动化过程。这是一种复制形式,从网上收集和复制特定的数据,通常是复制到一个中央本地数据库或电子表格,以便以后检索或分析。
换句话说,网页爬取是一个从网站上提取数据的过程,用于许多情况,从数据分析到线索生成。这项任务可以手动完成,也可以通过脚本或软件自动完成。
网页爬取有多种使用情况。请看几个例子。
收集数据。网页爬取的最有用的应用或用途是收集数据。数据是引人注目的,以正确的方式分析数据可以使一个公司领先于另一个公司。网页爬取是收集数据的一个基本工具–编写一个简单的脚本可以使数据收集比做手工工作更容易和更快。此外,数据还可以输入电子表格,以便更好地进行可视化和分析。
进行市场调查和产生线索。做市场研究和产生线索是至关重要的网页爬取任务。可以从各个网站爬取电子邮件、电话号码和其他重要信息,然后用于这些重要任务。
建立价格比较工具。你可能已经注意到了浏览器扩展程序,它可以提醒你电子商务平台上产品的价格变化。这类工具也是使用网络刮刀建立的。
在这篇文章中,你将学习如何使用Go创建一个简单的网页爬取器。
Robert Griesemer、Rob Pike和Ken Thompson在谷歌创建了Go编程语言,并从2009年开始进入市场。Go,也被称为Golang,有许多出色的功能。开始使用Go语言是快速而直接的。因此,这种相对较新的语言在开发者世界中获得了很大的吸引力。
用Go实现网页爬取
对并发性的支持使Go成为一种快速、强大的语言,而且由于该语言容易上手,你只需几行代码就可以建立你的网页爬取器。对于用Go创建网页爬取器,有两个库非常流行。
在这篇文章中,你将使用Colly来实现爬取器。首先,你将学习建立一个爬取器的基本知识,你将从维基百科页面实现一个URL爬取器。一旦你知道了用Colly进行网页爬取的基本构件,你就会提高技能,实现一个更高级的爬取器。
准备条件
在继续阅读本文之前,请确保你的计算机上安装了以下工具和库。你将需要以下东西。
- 对围棋的基本了解
- Go(最好是最新版本-1.17.2,截至本文写作时)。
- 你选择的IDE或文本编辑器(首选Visual Studio Code)。
- 用于IDE的Go扩展(如果有的话)
了解Colly和Collector 组件
Colly包用于构建网络爬虫和刮削器。它是基于Go的Net/HTTP和goquery包。goquery包在Go中提供了一个类似jQuery的语法,以HTML元素为目标。单独使用这个包也可以用来构建刮削器。
Colly的主要组件是采集器。根据文档,Collector组件管理网络通信,当Collector工作运行时,它也负责附加的Callbacks。这个组件是可配置的,你可以修改UserAgent字符串或添加Authenticationheaders,在这个组件的帮助下限制或允许URLs。
了解Colly Callbacks
Callbacks 也可以被添加到Collector组件中。Colly库有Callbacks,如OnHTML和OnRequest。你可以参考文档来了解所有的Callbacks。这些Callbacks在 Collector的生命周期中的不同点运行。例如,OnRequestCallbacks是在采集器发出HTTP请求之前运行。
OnHTML方法是构建网页爬取器时最常用的Callbacks方法。它允许Collector在到达网页上的特定HTML标签时为其注册一个Callbacks。
初始化项目目录和安装Colly
在开始写代码之前,你必须先初始化项目目录。打开你选择的IDE,并打开一个文件夹,你将在其中保存所有的项目文件。现在,打开一个终端窗口,并找到你的目录。然后,在终端输入以下命令:
go mod init github.com/Username/Project-Name
在上述命令中,将[github.com](http://github.com)改为你存储文件的域,如Bitbucket或Gitlab。另外,将Username改为你的用户名,Project-Name改为你想给它起的任何项目名称。
一旦你输入命令并按下回车键,你会发现一个新的文件被创建,名字是go.mod。这个文件保存了项目所需的直接和间接依赖关系的信息。下一步是安装Colly的依赖关系。要安装这个依赖关系,在终端键入以下命令:
go get -u github.com/go-colly/colly/...
这将下载Colly库并生成一个名为go.sum的新文件。现在你可以在go.mod文件中找到这个依赖关系。go.sum文件列出了直接和间接依赖关系的校验和,以及版本。你可以在这里阅读更多关于go.sum和go.mod文件的信息。
建造一个基本的爬虫
现在你已经用必要的依赖关系设置了项目目录,你可以继续编写一些代码。基本的爬取器旨在爬取特定维基百科页面上的所有链接,并将其打印在终端。这个爬取器的建立是为了让你对Colly库的构建模块感到舒服。
在该文件夹中创建一个扩展名为.go的新文件--例如,main.go。所有的逻辑都将归入这个文件。首先写下package main。这一行告诉编译器,这个包应该被编译为一个可执行程序,而不是一个共享库。
package main
下一步是开始编写主函数。如果你使用的是Visual Studio Code,它将自动完成必要的包的导入工作。否则,在其他IDE的情况下,你可能不得不手动完成。Colly的Collector是通过下面这行代码初始化的。
func main() {
c := colly.NewCollector(
colly.AllowedDomains("en.wikipedia.org"),
)
}这里,NewCollector被初始化,作为一个选项,en.wikipedia.org被作为一个允许的域传递。同样的Collector也可以在不传递任何选项的情况下被初始化。现在,如果你保存了这个文件,Colly会自动导入到你的main.go文件中;如果没有,请在package main一行之后添加以下几行。
import (
"fmt"
"github.com/gocolly/colly"
)以上几行在main.go文件中导入了两个包。第一个包是fmt包,第二个包是Colly库。
现在,在你的浏览器中打开这个网址。这是维基百科上关于网页爬取的页面。网页爬取器将爬取这个页面上的所有链接。很好地理解浏览器的开发工具是网页爬取的一项宝贵技能。通过右键单击页面并选择 “Inspect“来打开浏览器检查工具。这将打开页面检查器。你将能够从这里看到整个HTML、CSS、网络调用和其他重要信息。具体到这个例子,找到mw-parser-outputdiv。
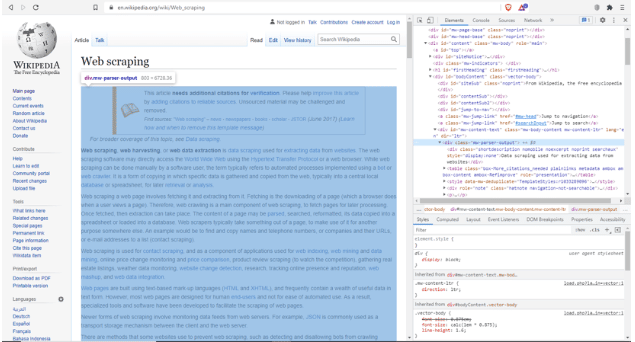
这个div元素包含页面的主体。锁定这个div内的链接将提供文章内使用的所有链接。
接下来,你将使用OnHTML方法。下面是爬取器的剩余代码:
// Find and print all links
c.OnHTML(".mw-parser-output", func(e *colly.HTMLElement) {
links := e.ChildAttrs("a", "href")
fmt.Println(links)
})
c.Visit("https://en.wikipedia.org/wiki/Web_scraping")OnHTML方法接收两个参数。第一个参数是HTML元素。到达它要执行Callbacks函数,它被作为第二个参数传入。在Callbacks函数里面,链接变量被分配给一个方法,该方法返回与元素属性相匹配的所有子属性。e.ChildAttrs("a", "href")函数Callbacks mw-parser-outputdiv内部所有链接的字符串片断。fmt.Println(links)函数在终端打印这些链接。
最后,使用c.Visit("https://en.wikipedia.org/wiki/Web_scraping")命令访问该URL。完整的爬取器代码将看起来像这样:
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector(
colly.AllowedDomains("en.wikipedia.org"),
)
// Find and print all links
c.OnHTML(".mw-parser-output", func(e *colly.HTMLElement) {
links := e.ChildAttrs("a", "href")
fmt.Println(links)
})
c.Visit("https://en.wikipedia.org/wiki/Web_scraping")
}用go run main.go命令运行这段代码,将得到页面上的所有链接。
爬取表格数据

要爬取表格数据,你可以删除你在c.OnHTML里面写的代码,或者按照上面提到的步骤创建一个新项目。为了制作和编写CSV文件,你将使用Go中的编码/CSV库。下面是启动代码:
package main
import (
"encoding/csv"
"log"
"os"
)
func main() {
fName := "data.csv"
file, err := os.Create(fName)
if err != nil {
log.Fatalf("Could not create file, err: %q", err)
return
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()在主函数中,第一个动作是定义文件名。这里,它被定义为data.csv。然后使用os.Create(fName)方法,以data.csv为名创建文件。如果在创建文件的过程中发生任何错误,它也会记录错误并退出程序。defer file.Close()命令将在周围函数返回时关闭文件。
writer := csv.NewWriter(file)命令初始化了CSV写入器,以写入文件,而writer.Flush()将把缓冲区内的所有东西扔给写入器。
一旦文件创建过程完成,就可以开始爬取过程。这与上面的例子类似。
接下来,在defer writer.Flush()行结束后添加以下几行代码:
c := colly.NewCollector()
c.OnHTML("table#customers", func(e *colly.HTMLElement) {
e.ForEach("tr", func(_ int, el *colly.HTMLElement) {
writer.Write([]string{
el.ChildText("td:nth-child(1)"),
el.ChildText("td:nth-child(2)"),
el.ChildText("td:nth-child(3)"),
})
})
fmt.Println("Scrapping Complete")
})
c.Visit("https://www.w3schools.com/html/html_tables.asp")在这段代码中,Colly正在被初始化。Colly使用ForEach方法来迭代内容。因为该表有三列或td元素,使用第n个孩子的伪选择器,三列被选中。el.ChildText返回元素内部的文本。把它放在writer.Write方法里面会把元素写进CSV文件。最后,打印语句在爬取完成后打印出一条信息。因为这段代码的目标不是表头,所以它不会打印表头。这个爬取器的完整代码将是这样的:
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"github.com/gocolly/colly"
)
func main() {
fName := "data.csv"
file, err := os.Create(fName)
if err != nil {
log.Fatalf("Could not create file, err: %q", err)
return
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
c := colly.NewCollector()
c.OnHTML("table#customers", func(e *colly.HTMLElement) {
e.ForEach("tr", func(_ int, el *colly.HTMLElement) {
writer.Write([]string{
el.ChildText("td:nth-child(1)"),
el.ChildText("td:nth-child(2)"),
el.ChildText("td:nth-child(3)"),
})
})
fmt.Println("Scrapping Complete")
})
c.Visit("https://www.w3schools.com/html/html_tables.asp")
}
[文中代码源自Scrapingbee]一旦成功,输出将显示如下:
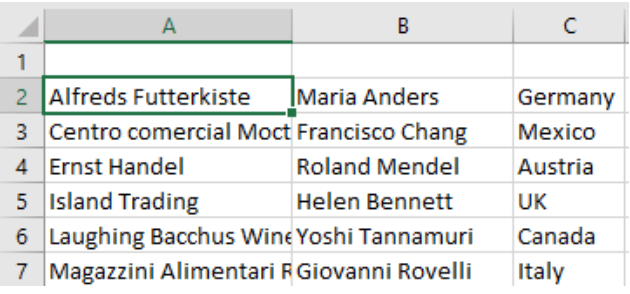
总 结
在这篇文章中,你了解了什么是网页爬取器,以及一些使用案例和如何在Colly库的帮助下用Go实现它们。
然而,本教程中描述的方法并不是实现爬取器的唯一可能方式。可以考虑自己进行实验,寻找新的方法。Colly还可以与goquery库一起工作,以制作一个更强大的爬取器。
根据你的使用情况,你可以修改Colly以满足你的需求。网页爬取对于关键词研究、品牌保护、推广、网站测试和其他许多事情都非常方便。因此,知道如何建立自己的网页爬取器可以帮助你成为一个更好的开发者。
如果你喜欢低级别的语言,你可能也会喜欢我们的《用C++进行网页爬取》。

