

由于JavaScript的大规模改进和被称为NodeJS的运行时的引入,它已经成为最流行和最广泛使用的语言之一。无论是网络还是移动应用,JavaScript现在都有合适的工具。本文将解释NodeJS的充满活力的生态系统如何让你有效地爬取网页,以满足你的大多数要求。
准备要求
这篇文章主要是针对那些有一定程度的JavaScript经验的开发者。然而,如果你对网页爬取有坚定的理解,但对JavaScript没有经验,它仍然可以作为JavaScript的轻度介绍。不过,拥有以下领域的经验肯定会有帮助:
- ✅ 拥有JavaScript的经验
- ✅ 使用浏览器的DevTools提取元素选择器的经验
- ✅ 对ES6 JavaScript有一些经验(可选)
会有什么收获
读完这篇文章后将能够:
- 对NodeJS有功能性的了解
- 使用多个HTTP客户端来协助网络爬取过程
- 使用多个现代的、经过战斗检验的库来爬取网络
了解NodeJS
JavaScript最初是为了给浏览器增加基本的脚本能力,以便让网站支持更多与用户互动的定制方式,比如显示一个对话框或即时创建额外的HTML内容。
为此,浏览器提供了一个运行环境(有全局对象,如文档和窗口),使你的代码能够与浏览器实例和页面本身进行交互。十多年来,JavaScript确实主要局限于这种使用情况和浏览器。然而,当Ryan Dahl在2009年推出NodeJS时,情况发生了变化。
NodeJS采用了Chrome的JavaScript引擎,并将其带到了服务器上(或更好的命令行)。与浏览器环境相反,它没有更多访问浏览器窗口或cookie存储的权限,相反,它得到的是对系统资源的完全访问。现在,它可以很容易地打开网络连接,在数据库中存储记录,甚至只是读写你硬盘上的文件。
从本质上讲,Node.js将JavaScript作为一种服务器端语言引入,并提供了一个常规的JavaScript引擎,摆脱了通常的浏览器沙盒桎梏,而是用一个标准的系统库来进行网络和文件访问。
JavaScript的事件循环
它所保留的,是事件循环。与许多语言通过多线程处理并发的方式不同,JavaScript一直只使用一个线程,并以异步的方式执行阻塞操作,主要依靠回调函数(或函数指针,C语言开发者可以称之为函数指针)。
让我们用一个简单的网络服务器例子来快速检查一下。
const http = require('http');
const PORT = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World');
});
server.listen(port, () => {
console.log(`Server running at PORT:${port}/`);
});在这里,我们用require导入HTTP标准库,然后用createServer创建一个服务器对象,并传递给它一个匿名的处理函数,该库将对每个传入的HTTP请求进行调用。最后,我们在指定的端口上进行监听–实际上就是这样。
这里有两个有趣的地方,都已经暗示了我们的事件循环和JavaScript的异步性。
我们传递给createServer的处理函数
事实上,listen不是一个阻塞性的调用,而是立即返回
在大多数其他语言中,我们通常会有一个接受函数/方法,它将阻塞我们的线程并返回连接客户端的连接套接字。在这一点上,最晚,我们将不得不切换到多线程,因为否则我们可以一次处理一个连接。然而,在这种情况下,我们不需要处理线程管理,由于回调和事件循环,我们始终保持一个线程。
如前所述,listen将立即返回,但是–尽管在我们的listen调用之后没有代码–应用程序不会立即退出。这是因为我们仍然有一个通过createServer(我们传递的那个函数)注册的回调。
每当客户端发送请求时,Node.js就会在后台对其进行解析,并调用我们的匿名函数并传递请求对象。我们在这里唯一要注意的是迅速返回,不要阻塞函数本身,但这很难做到,因为几乎所有的标准调用都是异步的(通过回调或承诺)–只要确保你不运行while(true);
但理论够多了,让我们来看看,好吗?
如果你安装了Node.js,你需要做的就是把代码保存到MyServer.js文件中,然后在你的shell中用node MyServer.js运行它。现在,只要打开你的浏览器并加载http://localhost:3000– voilà,你应该得到一个可爱的 “Hello World “问候语。这很容易,不是吗?
人们可以认为单线程方法可能会带来性能问题,因为它只有一个线程,但实际上恰恰相反,这就是异步编程的魅力所在。单线程、异步编程可以有,特别是对于I/O密集型工作,相当多的性能优势,因为不需要预先分配资源(例如线程)。
好吧,这是一个非常好的例子,说明我们如何在Node.js中轻松地创建一个网络服务器,但我们的业务是爬取,不是吗?因此,让我们来看看JavaScript HTTP客户端库。
HTTP客户端:查询网络
HTTP客户端是能够向一个服务器发送请求,然后从它那里接收响应的工具。本文将讨论的几乎每一个工具都在引擎盖下使用一个HTTP客户端,以查询你将试图爬取的网站的服务器。
1.内置的HTTP客户端
正如在你的服务器例子中所提到的,Node.js确实默认带有一个HTTP库。该库也有一个内置的HTTP客户端。
const http = require('http');
const req = http.request('http://example.com', res => {
const data = [];
res.on('data', _ => data.push(_))
res.on('end', () => console.log(data.join()))
});
req.end();它相当容易上手,因为没有任何第三方的依赖性需要安装或管理,然而–正如你从我们的例子中注意到的–这个库确实需要一点模板,因为它只提供整块的响应,你最终需要手动将它们拼接起来。你还需要为HTTPS URLs使用一个单独的库。
简而言之,它很方便,因为它是开箱即用的,但它可能需要你写更多的代码,而你可能不愿意。因此,让我们来看看其他的HTTP库。我们可以吗?
2.获取API
另一个内置方法是Fetch API。
虽然浏览器已经支持了一段时间,但Node.js花了更长时间,但从18版开始,Node.js确实支持fetch()。公平地说,就目前而言,它仍然被认为是一个实验性的功能,所以如果你喜欢安全,你也可以选择polyfill/wrapper库node-fetch,它提供了相同的功能。
Fetch API大量使用Promises,再加上await,这确实可以为你提供精简和清晰的代码。
async function fetch_demo()
{
const resp = await fetch('https://www.reddit.com/r/programming.json');
console.log(await resp.json());
}
fetch_demo();我们必须采用的唯一解决办法是将我们的代码包入一个函数中,因为await在顶层还不支持。除此之外,我们实际上只是用我们的URL调用了fetch(),等待响应(当然是在后台发生的Promise-magic),并使用我们Response对象的json()函数(再次等待)来获取响应。请注意,这是一个已经经过JSON解析的响应。
不错,两行代码,没有手动处理数据,没有区分HTTP和HTTPS,还有一个本地JSON对象。
fetch可以接受一个额外的options参数,在这里你可以用一个特定的请求方法(如POST)、额外的HTTP头或传递认证凭证来微调你的请求。
3. Axios
Axios与Fetch非常相似。它也是一个基于承诺的HTTP客户端,它可以在浏览器和Node.js中运行。TypeScript的用户也会喜欢它内置的类型支持。
然而,有一个缺点,与我们到目前为止提到的库相反,我们确实必须先安装它。
npm install axios
很好,让我们看看第一个普通承诺的例子。
const axios = require('axios')
axios
.get('https://www.reddit.com/r/programming.json')
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
});相当简单明了。依靠Promises,我们当然也可以再次使用await,使整个事情不那么冗长。所以,让我们再把它包装成一个函数。
async function getForum() {
try {
const response = await axios.get(
'https://www.reddit.com/r/programming.json'
)
console.log(response)
} catch (error) {
console.error(error)
}
}你所要做的就是调用getForum!你可以在Github上找到Axios库。
4. SuperAgent
与Axios非常相似,SuperAgent是另一个强大的HTTP客户端,它支持承诺和async/await语法糖。它和Axios一样有一个相当直接的API,但SuperAgent有更多的依赖性,而且不太受欢迎。
无论如何,用SuperAgent使用承诺、async/await和回调进行HTTP请求看起来像这样。
const superagent = require("superagent")
const forumURL = "https://www.reddit.com/r/programming.json"
// callbacks
superagent
.get(forumURL)
.end((error, response) => {
console.log(response)
})
// promises
superagent
.get(forumURL)
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
})
// promises with async/await
async function getForum() {
try {
const response = await superagent.get(forumURL)
console.log(response)
} catch (error) {
console.error(error)
}
}你可以在GitHub上找到SuperAgent库,安装SuperAgent就像npm install superagent一样简单
SuperAgent插件
使SuperAgent区别于其他库的一个特点是其可扩展性。它有相当多的插件,可以对请求或响应进行调整。例如,superagent-throttle插件允许你为你的请求定义节流规则。
5. Request
尽管它不再被积极维护,但Request仍然是JavaScript生态系统中一个流行的、广泛使用的HTTP客户端。
用Request做一个HTTP请求是相当简单的
const request = require('request')
request('https://www.reddit.com/r/programming.json', function (
error,
response,
body
) {
console.error('error:', error)
console.log('body:', body)
})你一定会注意到,我们既没有使用普通的Promises,也没有使用await。这是因为Request仍然采用了传统的回调方法,但是也有一些包装库支持await。
你可以在GitHub上找到Request库,安装它就像运行npm install request一样简单。
你应该使用Request吗?我们将Request列入这个列表,因为它仍然是一个流行的选择。然而,开发工作已经正式停止,它不再被积极维护。当然,这并不意味着它不能使用,仍然有很多库在使用它,但这一事实本身还是会让我们在为一个全新的项目使用它之前三思而后行,尤其是在有很多可行的替代品和本地获取支持的情况下。
在JavaScript中提取数据
毋庸置疑,获取一个网站的内容是任何爬取项目的重要步骤,但这只是第一步,我们实际上还需要定位和提取数据。这就是我们接下来要检查的内容,我们如何在JavaScript中处理一个HTML文档,以及如何定位和选择信息进行数据提取。
正则表达式:艰难的方法
最简单的方法是对你从HTTP客户端收到的HTML内容使用一堆正则表达式,就可以在没有任何依赖的情况下开始进行网络爬取。但这有一个很大的代价。
虽然正则表达式在其领域内绝对是个好东西,但对于解析像HTML这样的文档结构来说并不理想。此外,新来的人经常为如何正确使用正则表达式而苦恼(”我需要前视还是后视?”)。对于复杂的网络抓取,正则表达式也可能会失去控制。说到这里,我们还是来试试吧。
假设有一个标签,里面有一些用户名,我们想要这个用户名。这与你依靠正则表达式所要做的事情类似。
const htmlString = '' const result = htmlString.match(/
我们在这里使用String.match(),它将为我们提供一个包含正则表达式评估数据的数组。由于我们使用了一个捕获组((.+)),第二个数组元素(result[1])将包含该组设法捕获的东西。
虽然这在我们的例子中肯定是有效的,但任何更复杂的东西要么不工作,要么需要一个更复杂的表达式。试想一下,你的HTML文档中有几个<label>元素。
不要误会我们的意思,正则表达式是一个难以想象的伟大工具,只是不适合HTML 😊 – 所以让我们向你介绍CSS选择器和DOM的世界。
Cheerio: 用于遍历DOM的核心jQuery
Cheerio是一个高效而轻巧的库,它允许你在服务器端使用jQuery丰富而强大的API。如果你以前使用过jQuery,你会对Cheerio有宾至如归的感觉。它为你提供了一种非常简单的方法,将HTML字符串解析成DOM树,然后你可以通过你可能熟悉的jQuery的优雅界面(包括函数连接)来访问它。
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world
‘) $(‘h2.title’).text(‘Hello there!’) $(‘h2’).addClass(‘welcome’) $.html() //
Hello there!
正如你所看到的,使用Cheerio真的与你使用jQuery的方式几乎相同。
请记住,Cheerio真正关注的是DOM操作,你将无法在Cheerio中一对一地直接 “移植 “jQuery功能,如XHR/JAX请求或鼠标处理(如onClick)。
当你需要自己处理DOM时,Cheerio是一个伟大的工具,适用于大多数使用情况。当然,如果你想抓取一个JavaScript密集的网站(例如典型的单页应用程序),你可能需要一些更接近于完整的浏览器引擎。我们马上就会在《JavaScript中的无头浏览器》中讨论这个问题。
是时候来个快速的Cheerio例子了,你不同意吗?为了证明Cheerio的威力,我们将尝试抓取Reddit中的r/programming论坛,并获得一个帖子名称的列表。
首先,通过运行以下命令安装Cheerio和Axios:npm install cheerio axios。
然后创建一个名为crawler.js的新文件,复制/粘贴以下代码:
const axios = require('axios');
const cheerio = require('cheerio');
const getPostTitles = async () => {
try {
const { data } = await axios.get(
'https://old.reddit.com/r/programming/'
);
const $ = cheerio.load(data);
const postTitles = [];
$('div > p.title > a').each((_idx, el) => {
const postTitle = $(el).text()
postTitles.push(postTitle)
});
return postTitles;
} catch (error) {
throw error;
}
};
getPostTitles()
.then((postTitles) => console.log(postTitles));getPostTitles()是一个异步函数,它将抓取subreddit r/programming论坛。首先,使用Axios HTTP客户端库的简单HTTP GET请求获得网站的HTML。然后,使用cheerio.load()函数将HTML数据送入Cheerio。
很好,我们现在有了完全解析的HTML文档,作为DOM树,用老式的jQuery方式,在$。下一步是什么?好吧,知道从哪里获得我们的帖子标题可能不是一个坏主意。所以,让我们右击其中一个标题,然后选择检查。这应该能让我们在浏览器的开发工具中找到正确的元素。
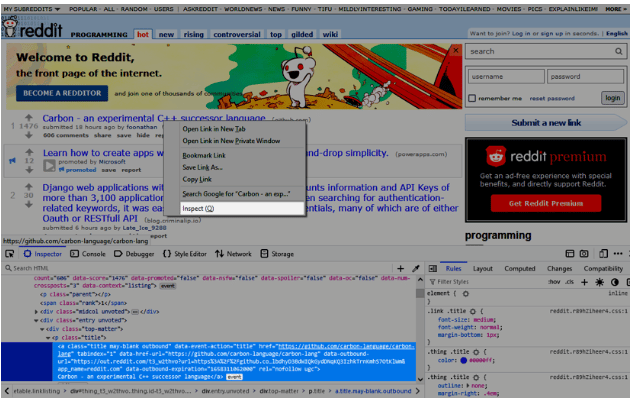
很好,有了XPath或CSS选择器的知识,我们现在可以很容易地组成我们对该元素需要的表达式。在我们的例子中,我们选择了CSS选择器,下面这个表达式就很好用。
div > p.title > a
如果你用过jQuery,你可能知道我们在做什么,对吗?
$('div > p.title > a')Cheerio的调用和jQuery是一样的(我们之前使用$作为DOM变量是有原因的),使用Cheerio和我们的CSS选择器会给我们匹配选择器的元素列表。
现在,我们只需要用each()遍历所有元素,并调用它们的text()函数来获得它们的文本内容。 jQuery,不是吗?
解释了这么多。是时候运行我们的代码了。
打开你的shell,运行node crawler.js。然后你会看到一个由大约25或26个不同的帖子标题组成的数组(它将是相当长的)。虽然这是一个简单的用例,但它展示了Cheerio所提供的API的简单性质。
如果你的用例需要执行JavaScript和加载外部资源,以下几个选项会有帮助。
jsdom:Node的DOM
与Cheerio在服务器端复制jQuery的方式类似,jsdom对浏览器的原生DOM功能也有同样的作用。
然而,与Cheerio不同的是,jsdom不仅将HTML解析为DOM树,它还可以处理嵌入的JavaScript代码,并允许你与页面元素 “互动”。
实例化一个jsdom对象是相当容易的。
const { JSDOM } = require('jsdom')
const { document } = new JSDOM(
'Hello world
‘ ).window const heading = document.querySelector(‘.title’) heading.textContent = ‘Hello there!’ heading.classList.add(‘welcome’) heading.innerHTML //
Hello there!
在这里,我们用require导入库,用构造函数创建了一个新的jsdom实例,并传递了我们的HTML片段。然后,我们简单地使用querySelector()(正如我们在前端开发中所知道的那样)来选择我们的元素,并对其属性做了一些调整。这很标准,当然,我们也可以用Cheerio来做。
然而,让jsdom与众不同的是前面提到的对嵌入式JavaScript代码的支持,我们现在就来看看这个。
下面的例子使用了一个简单的本地HTML页面,其中一个按钮添加了一个带有ID的<div>。

这里没有太复杂的东西:
- 我们
require()jsdom - 设置我们的
HTML文档 - 将
HTML传给我们的jsdom构造函数(很重要,我们需要启用runScripts)。 - 通过调用
querySelector()选择按钮。 - 并
click()它
这应该给我们提供这样的输出
Element before click: null Element after click: [object HTMLDivElement]
相当直接,这个例子展示了我们如何使用jsdom来实际执行页面的JavaScript代码。当我们加载文档时,最初没有<div>。只有当我们点击按钮时,它才被网站的代码添加,而不是我们爬虫的代码。
在这种情况下,重要的细节是runScripts和资源。这些标志指示jsdom运行页面的代码,以及获取任何相关的JavaScript文件。正如jsdom的文档所指出的,这有可能让任何网站逃出沙盒,仅仅通过抓取就能进入你的本地系统。请谨慎行事。
jsdom是一个伟大的库,可以在你的本地Node.js实例中处理大多数典型的浏览器任务,但它仍然有一些局限性,这就是无头浏览器真正的优势所在。
JavaScript中的无头浏览器
网站变得越来越复杂,通常常规的HTTP抓取已经不够用了,但实际上需要一个成熟的浏览器引擎,以便从网站上获得必要的信息。
这对于严重依赖JavaScript和动态及异步资源的SPA来说尤其如此。
浏览器自动化和无头浏览器在这里发挥了作用。让我们看看它们如何帮助我们轻松地抓取单页应用程序和其他使用JavaScript的网站。
1.Puppeteer:无头浏览器
顾名思义,Puppeteer允许你以编程方式操纵浏览器,就像木偶被其操纵者操纵一样。它通过向开发者提供高级别的API来实现这一目标,默认情况下,它可以控制无头版的Chrome浏览器,并可以配置为非无头版的运行。
Puppeteer比上述工具特别有用,因为它允许你抓取网络,就像一个真正的人在与浏览器互动一样。这开启了一些以前没有的可能性。
- 你可以获得屏幕截图或生成页面的PDF文件。
- 你可以抓取一个单页应用程序并生成预渲染的内容。
- 你可以将许多不同的用户互动自动化,如键盘输入、表格提交、导航等。
它还可以在网络抓取范围之外的许多其他任务中发挥很大作用,如UI测试、辅助性能优化等。
很多时候,你可能想对网站进行截图,或者,了解竞争对手的产品目录。Puppeteer可以用来做这件事。首先,通过运行以下命令来安装Puppeteer:npm install puppeteer
这将下载一个捆绑的Chromium版本,大约需要180到300MB,取决于你的操作系统。你可以通过指定几个Puppeteer环境变量,如PUPPETEER_SKIP_CHROMIUM_DOWNLOAD,来避免这一步,并使用已经安装好的设置。不过,一般来说,Puppeteer确实推荐使用捆绑的版本,不支持自定义设置。
让我们尝试在Reddit的r/programming论坛上获得一个截图和PDF,创建一个名为crawler.js的新文件,并复制/粘贴以下代码。
const puppeteer = require('puppeteer')
async function getVisual() {
try {
const URL = 'https://www.reddit.com/r/programming/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
await page.screenshot({ path: 'screenshot.png' })
await page.pdf({ path: 'page.pdf' })
await browser.close()
} catch (error) {
console.error(error)
}
}
getVisual()getVisual()是一个异步函数,它将对我们的页面进行截图,并将其导出为PDF文档。
首先,通过运行puppeteer.launch() 创建一个浏览器的实例。接下来,我们用newPage()创建一个新的浏览器标签/页面。现在,我们只需要在我们的页面实例上调用goto(),并将我们的URL传给它。
所有这些函数都是异步的,并将立即返回,但由于它们返回的是一个JavaScript Promise,而我们使用的是await,这个流程看起来仍然是同步的,因此,一旦goto“返回”,我们的网站应该已经加载。
很好,我们已经准备好获得漂亮的图片了。让我们在我们的页面实例上调用screenshot(),并把图片文件的路径传给它。我们对pdf()做同样的操作,然后,我们应该在指定的位置有两个新文件。因为我们是负责任的网民,所以我们也在我们的浏览器对象上调用close(),以清理我们自己。就这样了。
有一点要记住,当goto()返回时,页面已经加载,但它可能没有完成所有的异步加载。因此,根据您的网站,您可能想在生产型爬虫中添加额外的逻辑,以等待某些JavaScript事件或DOM元素。
但让我们来运行代码。弹出一个shell窗口,输入node crawler.js,片刻之后,你的目录中应该正好有上述两个文件。
2. Nightmare: Puppeteer 的替代品
Nightmare是另一个类似Puppeteer的高级浏览器自动化库。它使用Electron,网络和爬取基准显示它的性能明显优于其前身PhantomJS。如果Puppeteer对你的使用情况来说太复杂,或者默认的Chromium捆绑程序有问题,那么Nightmare可能就是适合你的东西。
就像很多时候一样,我们的旅程从NPM开始:npm install nightmare
一旦 Nightmare在你的系统上可用,我们将使用它通过Brave搜索找到Dailiservers的网站。要做到这一点,请创建一个名为crawler.js的文件,并将以下代码复制/粘贴到其中。
const Nightmare = require('nightmare')
const nightmare = Nightmare()
nightmare
.goto('https://search.brave.com/')
.type('#searchbox', 'Dailiservers')
.click('#submit-button')
.wait('#results a')
.evaluate(
() => document.querySelector('#results a').href
)
.end()
.then((link) => {
console.log('Dailiservers Web Link:', link)
})
.catch((error) => {
console.error('Search failed:', error)
})在使用require导入常规库后,我们首先创建一个新的Nightmare实例,并将其保存在nightmare中。之后,我们将在函数链和承诺方面有很多乐趣。
- 我们使用
goto()从https://search.brave.com,以加载Brave。 - 我们在Brave的搜索输入中
输入我们的搜索词 Dailiservers”,并使用CSS选择器#searchbox(Brave的命名相当直接,不是吗?) - 我们
点击提交按钮,开始我们的搜索。同样,这是用CSS选择器#submit-button(Brave真的很直接,我们喜欢这个) - 让我们快速休息一下,直到Brave返回搜索列表。
等待,配合正确的选择器在这里有奇效。等待也接受时间值,如果你需要等待一个特定的时间段。 - 一旦Nightmare从Brave那里得到了链接列表,我们只需使用
evaluate()在页面上运行我们的自定义代码(这里是querySelector()),得到第一个与我们的选择器匹配的<a>元素,并返回其href属性。 - 最后但同样重要的是,我们调用
end()来运行并完成我们的任务队列。
就这样,伙计们。end()返回一个标准的Promise,其中包含我们调用evaluate()的值。当然,你也可以在这里使用await。
3.Playwright – 新的网页爬取框架
Playwright是由微软支持的新的跨语言、跨平台的无头框架。
与Puppeteer相比,它的主要优势在于它是跨平台的,而且非常容易使用。
下面是如何用它简单地刮取一个页面。
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: false // setting this to true will not run the UI
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/world-indices');
await page.waitForTimeout(5000); // wait for 5 seconds
await browser.close();
}
main();
[文中代码源自Scrapingbee]总 结
我们希望我们的例子能够让你初步了解用JavaScript进行网页抓取的世界,以及你可以用哪些库来抓取你需要的信息。
让我们来简单回顾一下,我们今天学到的东西是。
- ✅NodeJS是一个JavaScript运行时间,允许JavaScript在服务器端运行。由于事件循环(Event Loop)的存在,它具有非阻塞的特性。
- ✅HTTP客户端,如本地库和fetch,以及Axios、SuperAgent、node-fetch和Request,用于向服务器发送HTTP请求并接收响应。
- ✅Cheerio将jQuery的优点抽象出来,唯一的目的是在服务器端运行jQuery以进行网页抓取,但不执行JavaScript代码。
- ✅JSDOM根据标准的JavaScript规范从HTML字符串中创建一个DOM,并允许你对它进行DOM操作。
- ✅Puppeteer和Nightmare是高水平的浏览器自动化库,允许你以编程方式操纵网络应用,就像一个真正的人在与它们互动一样。

