

这篇文章涵盖了在Ruby中进行网页爬取的主要工具和技术。我们首先介绍了如何使用常见的Ruby HTTP客户端构建一个网页爬取器,以及如何在Ruby中解析HTML文档。
然而,这种网页爬取的方法确实有其局限性,而且会带来相当多的挫折。特别是在单页应用程序的背景下,由于大量使用JavaScript,我们会很快遇到重大障碍。在本文的第二部分,我们将仔细研究如何使用网页爬取框架来解决这个问题。
注意:本文假设读者对Ruby平台很熟悉。虽然有大量的gems,但我们将专注于最流行的gems,并使用它们的Github指标(使用、星级和分叉)作为指标。虽然我们无法涵盖这些工具的所有使用情况,但我们将为你提供良好的基础,使你能够开始并自行探索更多。
第一部分:静态页面
设置
为了能够与这部分一起编码,你可能需要安装以下gems:
gem install 'pry' #debugging tool gem install 'nokogiri' #parsing gem gem install 'HTTParty' #HTTP request gem
此外,我们将使用open-uri、net/http和csv,它们是标准Ruby库的一部分,所以不需要单独安装。至于Ruby,我们的例子使用的是第3版,我们的主要玩法将是scraper.rb这个文件。
在Ruby中用HTTP客户端发出请求
在本节中,我们将介绍如何用Ruby爬取维基百科页面。
想象一下,你想建立一个终极道格拉斯-亚当斯粉丝维基。你肯定会先从维基百科上获取数据。为了向任何网站或网络应用发送请求,你需要使用一个HTTP客户端。让我们看看我们的三个主要选择:net/http、open-uri和HTTParty。你可以使用你最喜欢的以下任何一个客户端,它将与步骤2一起工作。
Net::HTTP
Ruby的标准库中有一个自己的HTTP客户端,即net-httpgem。为了轻松地请求道格拉斯-亚当斯的维基百科页面,我们首先需要使用open-urigem将我们的URL字符串转换为一个URI对象。一旦我们有了URI,我们就可以把它传递给get_response,它将为我们提供一个Net::HTTPResponse对象,其body方法将为我们提供HTML文档。
require 'open-uri' require 'net/http' url = "https://en.wikipedia.org/wiki/Douglas_Adams" uri = URI.parse(url) response = Net::HTTP.get_response(uri) html = response.body puts html #=> "\n\n\n\n\n..."
专业提示:如果你使用Net::HTTP的REST接口并需要处理JSON,只需要求’json’并使用JSON.parse(response.body)解析响应。
就是这样–它可以工作了然而,net/http的语法可能有点笨拙,不如HTTParty或open-uri直观,事实上,它们只是net/http的优雅包装。
HTTParty
HTTPartygem的创建是为了让http变得有趣。事实上,凭借直观和直接的语法,该宝石近年来已经广泛流行。下面两行是我们成功进行GET请求所需要的全部内容。
require "HTTParty"
response = HTTParty.get("https://en.wikipedia.org/wiki/Douglas_Adams")
html = response.body
puts html
# => "\n" + "\n" + "\n" + "\n" + "\n" + ...get返回一个HTTParty::Response对象,它再次为我们提供了响应的细节,当然也包括页面的内容。如果服务器提供的内容类型是application/json,HTTParty将自动把响应解析为JSON,并返回适当的Ruby对象。
OpenURI
然而,最简单的解决方案是用open-urigem提出请求,它也是标准Ruby库的一部分。
require 'open-uri'
html = URI.open("https://en.wikipedia.org/wiki/Douglas_Adams")
##<File:/var/folders/zl/8zprgb3d6yn_466ghws8sbmh0000gq/T/open-uri20200525-33247-1ctgjgo>这为我们提供了一个文件描述符,并允许我们从URL中逐行读取,就像它是一个文件一样。
OpenURI的简单性已经体现在它的名字中。它只发送一种类型的请求,而且做得很好,对SSL和重定向有合理的HTTP默认值。
用Nokogiri解析HTML
一旦我们得到了HTML,我们就需要提取我们感兴趣的部分。正如你可能注意到的,前面的每个例子都声明了一个html变量。我们现在将使用它作为Nokogiri::HTML方法的参数。不过别忘了要求 "nokogiri"
doc = Nokogiri::HTML(html)
# => #(Document:0x3fe41d89a238 {
# name = "document",
# children = [
# #(DTD:0x3fe41d92bdc8 { name = "html" }),
# #(Element:0x3fe41d89a10c {
# name = "html",
# attributes = [
# #(Attr:0x3fe41d92fe00 { name = "class", value = "client-nojs" }),
# #(Attr:0x3fe41d92fdec { name = "lang", value = "en" }),
# #(Attr:0x3fe41d92fdd8 { name = "dir", value = "ltr" })],
# children = [
# #(Text "\n"),
# #(Element:0x3fe41d93e7fc {
# name = "head",
# children = [ ...我们现在有了一个Nokogiri::HTML::Document对象。我们现在有了一个Nokogiri::HTML::Document对象,它本质上是我们文档的DOM表示,并将允许我们用CSS选择器和XPath表达式查询文档。
为了选择正确的DOM元素,我们需要利用浏览器的开发工具做一些侦查工作。在下面的例子中,我们使用Chrome浏览器来检查一个所需的元素是否有任何附加的类。
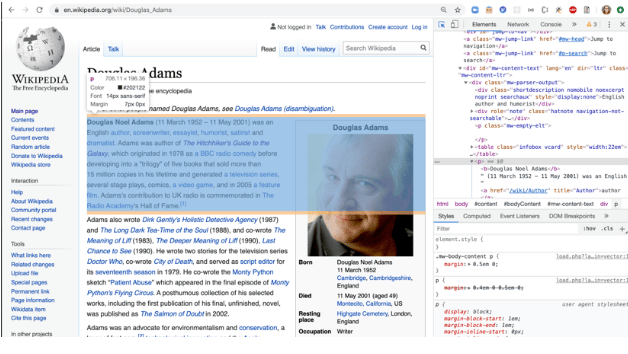
正如我们所看到的,维基百科并没有完全广泛地使用HTML类,真是太可惜了。不过,我们还是可以通过它们的标签来选择它们。例如,如果我们想获得所有的段落,我们可以通过选择所有的<p>元素,然后获取它们的文本内容。
description = doc.css("p").text
# => "\n\nDouglas Noel Adams (11 March 1952 – 11 May 2001) was an English author, screenwriter, essayist, humorist, satirist and dramatist. Adams was author of The Hitchhiker's Guide to the Galaxy, which originated in 1978 as a BBC radio comedy before developing into a \"trilogy\" of five books that sold more than 15 million copies in his lifetime and generated a television series, several stage plays, comics, a video game, and in 2005 a feature film. Adams's contribution to UK radio is commemorated in The Radio Academy's Hall of Fame.[1]\nAdams also wrote Dirk Gently's...这种方法产生了一个4,336字长的字符串。然而,想象一下,你想只得到第一个介绍性段落和图片。你可以使用正则表达式或者让Ruby用.split方法为你做这个。
在我们的例子中,我们可以注意到段落的定界符(\n)被保留了下来,所以我们可以简单地用换行符分割,得到第一个非空段落。
description = doc.css("p").text.split("\n").find{|e| e.length > 0}另一种方法是用.strip修剪所有的空白,然后从我们的字符串数组中选择第一个元素。
description = doc.css("p").text.strip.split("\n")[0]另外,根据HTML的结构,有时一个更简单的方法是直接访问选择器元素。
description = doc.css("p")[1]
#=> #(Element:0x3fe41d89fb84 {
# name = "p",
# children = [
# #(Element:0x3fe41e43d6e4 { name = "b", children = [ #(Text "Douglas Noel Adams")] }),
# #(Text " (11 March 1952 – 11 May 2001) was an English "),
# #(Element:0x3fe41e837560 {
# name = "a",
# attributes = [
# #(Attr:0x3fe41e833104 { name = "href", value = "/wiki/Author" }),
# #(Attr:0x3fe41e8330dc { name = "title", value = "Author" })],
# children = [ #(Text "author")]
# }),
# #(Text ", "),
# #(Element:0x3fe41e406928 {
# name = "a",
# attributes = [
# #(Attr:0x3fe41e41949c { name = "href", value = "/wiki/Screenwriter" }),
# #(Attr:0x3fe41e4191cc { name = "title", value = "Screenwriter" })],
# children = [ #(Text "screenwriter")]
# }),一旦我们找到了我们感兴趣的元素,我们需要对它调用.children方法,这将返回–你已经猜到了–更多嵌套的DOM元素。我们可以对它们进行迭代,以获得我们需要的文本。下面是一个关于两个节点的返回值的例子。
doc.css("p")[1].children[0]
#=> #(Element:0x3fe41e43d6e4 { name = "b", children = [ #(Text "Douglas Noel Adams")] })
doc.css("p")[1].children[1]
#=> #(Text " (11 March 1952 – 11 May 2001) was an English ")现在,让我们找到文章的主要图片。这应该很容易,对吗?最直接的方法是选择标签,不是吗?
doc.css("img").count
#=> 16不完全是,那一页上有相当多的图片。
那么,我们可以过滤一些特定的图像数据,不是吗?
doc.css("img").find{|picture| picture.attributes["alt"].value.include?("Douglas adams portrait cropped.jpg")}
#=> ![]()
完美,这给了我们正确的形象,对吗?
算是吧,但请稍安勿躁。只要有一点变化,我们的find()调用就不会再找到。
好吧,好吧,那使用XPath表达式呢?
doc.xpath("/html/body/div[3]/div[3]/div[5]/div/table[1]/tbody/tr[2]/td/a/img")
#=> ![]()
诚然,我们在这里也得到了图片,并没有在一个任意的标签上进行过滤,但是,就像绝对路径一样,如果DOM层次结构只是有一点变化,这也会很快被打破。
那么现在怎么办?
如前所述,维基百科在涉及到ID时并不十分慷慨,但有一些看似独特的HTML类,在整个维基百科中似乎相当稳定。
doc.css(".infobox-image img")
#=> ![]()
正如你所注意到的,获得正确(和稳定)的DOM路径可能有点棘手,确实需要一些经验和对DOM树的分析,但当你找到正确的CSS选择器或XPath表达式,并且它们经受住了时间的考验,不因DOM的变化而中断,这也是相当有价值的。就像很多时候一样,你的浏览器的开发工具将是你在这一努力中最好的朋友。
将爬取的数据导出到CSV
好吧,在我们继续讨论如何利用我们前面提到的成熟的网络爬取框架之前,让我们看看如何实际使用我们刚刚从网站上得到的数据。
一旦你成功地爬取了网站,你可能想把这些数据保留下来,以便以后使用。一个方便且可互操作的方法是将其保存为CSV文件。CSV文件不仅可以用Excel轻松管理,而且也是许多其他第三方平台(如邮件框架)的标准格式。自然地,Ruby用csv gem帮你搞定了。
require "nokogiri"
require "csv"
require "open-uri"
html = URI.open("https://en.wikipedia.org/wiki/Douglas_Adams")
doc = Nokogiri::HTML(html)
description = doc.css("p").text.split("\n").find{|e| e.length > 0}
picture = doc.css("td a img").find{|picture| picture.attributes["alt"].value.include?("Douglas adams portrait cropped.jpg")}.attributes["src"].value
data_arr = []
data_arr.push(description, picture)
CSV.open('data.csv', "w") do |csv|
csv << data_arr
end那么,我们在这里做了什么?让我们快速回顾一下。
- 我们导入了我们要使用的库。
- 我们使用OpenURI来加载URL的内容,并将其提供给Nokogiri。
- 一旦Nokogiri有了DOM,我们就礼貌地要求它提供描述和图片的URL。
- 我们将数据添加到我们的data_arr数组中。
- 我们使用CSV.open将数据写入我们的CSV文件中。
第二部分:Kimurai–一个完整的Ruby网页爬取框架
到目前为止,我们的重点是如何加载一个URL的内容,如何将其HTML文档解析成一个DOM树,以及如何使用CSS选择器和XPath表达式选择特定的文档元素。虽然这一切都做得很好,但仍有一些限制,即JavaScript。
越来越多的网站依靠JavaScript来呈现他们的内容(当然,特别是单页应用程序或利用无限滚动来获取数据的网站),在这种情况下,我们的Nokogiri实现将只获得最初的HTML bootstrap文档,而没有实际数据。没有得到实际的数据,对于一个爬取者来说,是不太理想的,对吗?
在这些情况下,我们可以使用专门支持JavaScript驱动的网站的工具。其中之一是Kimurai,一个专门为网络爬取设计的Ruby框架。像我们之前的例子一样,它也使用Nokogiri来访问DOM元素,以及使用Capybara来执行交互式动作,通常由用户执行(如鼠标点击)。除此之外,它还支持无头浏览器(即无头Chrome和无头Firefox)和PhantomJS的完全整合。
在文章的这一部分,我们将爬取一个招聘信息的网络应用。首先,我们将通过访问不同的URL地址进行静态操作,然后,我们将引入一些JS操作。
Kimurai 设置
为了爬取动态网页,你需要安装一些工具–下面你会发现带有macOS安装命令的列表。
- Chrome和Firefox:
brew cask install google-chrome firefox - ChromeDriver:
brew cask install chromedriver - geckodriver:
brew install geckodriver - PhantomJS:
brew install phantomjs - Kimurai gem:
gem install kimurai
在本教程中,我们将使用一个简单的Ruby文件,但你也可以创建一个Rails应用程序,爬取一个网站并将数据保存到数据库。
静态页面爬取
让我们从Kimurai认为最基本的东西开始:一个带有爬取器选项的类和一个解析方法。
class JobScraper < Kimurai::Base
@name= 'eng_job_scraper'
@start_urls = ["https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY"]
@engine = :selenium_chrome
def parse(response, url:, data: {})
end
end我们定义了以下三个字段。
- @name: 你可以随心所欲地命名你的爬取器,如果你的爬取器只有一个文件,则可以完全省略它。
- @start_urls:这是一个起始URL的数组,它将在解析方法中被逐一处理。
- @engine:用于爬取的引擎;Kimurai支持四个默认引擎。对于我们这里的例子,我们将使用Selenium和Headless Chrome。
现在我们来谈谈解析方法。它是爬取器的默认入口方法,接受以下参数。
- 响应:Nokogiri::HTML对象,我们从这篇文章的前一部分知道。
- url:一个字符串,可以手动传递给方法,否则将从@start_urls数组中获取。
- data:一个用于在请求之间传递数据的存储器。
就像我们使用Nokogiri时一样,你也可以在这里使用CSS选择器和XPath表达式来选择你要提取的文档元素。
浏览器对象
每个Kimurai类也有一个默认的
浏览器字段,它提供了对底层Capybara会话对象的访问,并允许你与它的浏览器实例进行交互(例如,编译表单或执行鼠标操作)。
好了,让我们深入了解一下我们工作网站的页面结构。
由于我们对工作条目感兴趣,我们应该首先检查是否有一个共同的父元素(最好有自己的HTML ID,对吗?)。我们很幸运,这些工作都包含在一个单一的<td>中,有一个resultsColID。

现在,我们只需要找到各个条目元素的标签,就可以爬取数据了。幸运的是,这也是相对简单的,一个带有job_seen_beacon类的<div>。

下面是我们之前的基类,有一个粗略的实现,还有一个@@jobs数组来记录我们发现的所有工作条目。
require 'kimurai'
class JobScraper < Kimurai::Base
@name= 'eng_job_scraper'
@start_urls = ["https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY"]
@engine = :selenium_chrome
@@jobs = []
def scrape_page
doc = browser.current_response
returned_jobs = doc.css('td#resultsCol')
returned_jobs.css('div.job_seen_beacon').each do |char_element|
#code to get only the listings
end
end
def parse(response, url:, data: {})
scrape_page
@@jobs
end
end
JobScraper.crawl!是时候获得实际的数据了!
让我们再一次查看这个页面,并尝试找到我们所要的数据点的选择器。
| 数据点 | 选择器 |
|---|---|
| 页面URL | h2.jobTitle > a |
| 标题 | h2.jobTitle > a > span |
| 描述 | div.job-snippet |
| 公司 | div.companyInfo > span.companyName |
| 地点 | div.companyInfo > div.companyLocation |
| 薪资 | span.improved-salary > span |
有了这些信息,我们现在应该能够从我们页面的所有工作条目中提取数据。
def scrape_page
doc = browser.current_response
returned_jobs = doc.css('td#resultsCol')
returned_jobs.css('div.job_seen_beacon').each do |char_element|
# scraping individual listings
title = char_element.css('h2.jobTitle > a > span').text.gsub(/\n/, "")
link = "https://indeed.com" + char_element.css('h2.jobTitle > a').attributes["href"].value.gsub(/\n/, "")
description = char_element.css('div.job-snippet').text.gsub(/\n/, "")
company = char_element.css('div.companyInfo > span.companyName').text.gsub(/\n/, "")
location = char_element.css('div.companyInfo > div.companyLocation').text.gsub(/\n/, "")
salary = char_element.css('span.estimated-salary > span').text.gsub(/\n/, "")
# creating a job object
job = {title: title, link: link, description: description, company: company, location: location, salary: salary}
# adding the object if it is unique
@@jobs << job if !@@jobs.include?(job)
end
end我们也可以不创建一个对象,而是创建一个数组,这取决于我们以后需要什么样的数据结构。
job = [title, link, description, company, location, salary, requirements]
按照目前的代码,我们只得到前15个结果,或只是第一页。为了获得后面几页的数据,我们可以访问后续的URL。
def parse(response, url:, data: {})
# scrape first page
scrape_page
# next page link starts with 20 so the counter will be initially set to 2
num = 2
#visit next page and scrape it
10.times do
browser.visit("https://www.indeed.com/jobs?q=software+engineer&l=New+York,+NY&start=#{num}0")
scrape_page
num += 1
end
@@jobs
end最后,我们可以将我们的数据存储在CSV或JSON文件中,方法是在我们的解析方法中添加以下片段之一。
CSV.open('jobs.csv', "w") do |csv|
csv << @@jobs
end或,
File.open("jobs.json","w") do |f|
f.write(JSON.pretty_generate(@@jobs))
end用Selenium和Headless Chrome进行动态页面爬取
到目前为止,我们的Kimurai代码与我们之前的例子没有什么不同。虽然,我们没有通过真正的浏览器加载一切,但我们仍然简单地加载页面,提取所需的数据项,并根据我们的URL模板加载下一个页面。
真正的用户不会做这最后一步,对吗?不,他们不会,他们只是点击 “下一步 “按钮。这正是我们现在要检查的内容。
def parse(response, url:, data: {})
10.times do
# scrape first page
scrape_page
puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count}🔹 🔹 🔹"
# find the "next" button + click to move to the next page
browser.find('/html/body/table[2]/tbody/tr/td/table/tbody/tr/td[1]/nav/div/ul/li[6]/a/span').click
puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE NEXT BUTTON 🔺 🔺 🔺 🔺 "
end
@@jobs
end我们仍然调用之前的scrape_page()方法,但现在我们也使用Capybara的浏览器对象来查找()(使用XPath表达式)并点击()”下一步 “按钮。
我们添加了两个put语句,这样我们成功地爬取了第一页,但随后我们遇到了一个错误。

我们现在有两个选择
- 检查我们收到的
response,以及DOM树是否有任何不同(剧透,是的)。 - 让浏览器截图,并检查页面看起来是否有任何不同。
虽然选项1当然是更彻底的一个,但选项2往往是指出任何明显变化的捷径。因此,让我们先试试这个。
就像很多时候一样,用Capybara进行截图是非常直接的。只需在浏览器对象上调用save_screenshot(),一个屏幕截图(名字随机)就会被保存在你的工作目录中。
def parse(response, url:, data: {})
10.times do
# scrape first page
scrape_page
# take a screenshot of the page
browser.save_screenshot
# find the "next" button + click to move to the next page
browser.find('/html/body/table[2]/tbody/tr/td/table/tbody/tr/td[1]/nav/div/ul/li[6]/a/span').click
puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count}🔹 🔹 🔹"
puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE NEXT BUTTON 🔺 🔺 🔺 🔺 "
end
@@jobs
end在运行了几次这个测试,并仔细检查了错误之后,我们知道它有两个版本,而且当弹出式窗口显示时,我们的 “下一步 “按钮是不能点击的。幸运的是,一个简单的browser.refresh就能解决这个问题。
def parse(response, url:, data: {})
10.times do
scrape_page
# if there's the popup, escape it
if browser.current_response.css('div#popover-background') || browser.current_response.css('div#popover-input-locationtst')
browser.refresh
end
# find the "next" button + click to move to the next page
browser.find('/html/body/table[2]/tbody/tr/td/table/tbody/tr/td[1]/nav/div/ul/li[6]/a/span').click
puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count}🔹 🔹 🔹"
puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE NEXT BUTTON 🔺 🔺 🔺 🔺 "
end
@@jobs
end最后,我们的爬取器顺利工作,经过十轮后,我们最终得到了155个工作列表。
下面是我们的动态爬取器的完整代码:
require 'kimurai'
class JobScraper < Kimurai::Base @name= 'eng_job_scraper' @start_urls = ["https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY"] @engine = :selenium_chrome @@jobs = [] def scrape_page doc = browser.current_response returned_jobs = doc.css('td#resultsCol') returned_jobs.css('div.job_seen_beacon').each do |char_element| # scraping individual listings title = char_element.css('h2.jobTitle > a > span').text.gsub(/\n/, "")
link = "https://indeed.com" + char_element.css('h2.jobTitle > a').attributes["href"].value.gsub(/\n/, "")
description = char_element.css('div.job-snippet').text.gsub(/\n/, "")
company = char_element.css('div.companyInfo > span.companyName').text.gsub(/\n/, "")
location = char_element.css('div.companyInfo > div.companyLocation').text.gsub(/\n/, "")
salary = char_element.css('span.estimated-salary > span').text.gsub(/\n/, "")
# creating a job object
job = {title: title, link: link, description: description, company: company, location: location, salary: salary}
@@jobs << job if !@@jobs.include?(job)
end
end
def parse(response, url:, data: {})
10.times do
scrape_page
if browser.current_response.css('div#popover-background') || browser.current_response.css('div#popover-input-locationtst')
browser.refresh
end
browser.find('/html/body/table[2]/tbody/tr/td/table/tbody/tr/td[1]/nav/div/ul/li[6]/a/span').click
puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count}🔹 🔹 🔹"
puts "🔺 🔺 🔺 🔺 🔺 CLICKED NEXT BUTTON 🔺 🔺 🔺 🔺 "
end
CSV.open('jobs.csv', "w") do |csv|
csv << @@jobs
end
File.open("jobs.json","w") do |f|
f.write(JSON.pretty_generate(@@jobs))
end
@@jobs
end
end
jobs = JobScraper.crawl!另外,你也可以把crawl!方法改为parse!方法,这将允许你使用返回语句并打印出@@jobs数组。
jobs = JobScraper.parse!(:parse, url: "https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY") pp jobs [代码源自Scrapingbee]
总 结
当你需要访问和分析大量来自不同来源的(半结构化)数据时,网页爬取无疑是一个非常强大的工具。虽然它允许你快速访问、汇总和处理这些数据,但它也可能是一项具有挑战性和艰巨性的任务,这取决于你使用的工具和你想处理的数据。
重要的是,你正在使用正确的工具和正确的方法来抓取一个网站。正如我们在这篇文章中所了解到的,Ruby是一个很好的选择,它有许多可用于此目的的现成的库。需要记住的一个重要方面是,在计划你的爬虫策略时,要避免被网站的速率限制。

