

Yelp在全球拥有超过1.99亿条企业评论,是最大的众包评论网站之一。在这篇文章中,你将学习如何从Yelp的搜索结果和单个餐馆的页面中爬取数据。你将学习可用于网页爬取的不同Python库,以及有效使用它们的技术。
如果你以前从未听说过Yelp,它是一家为当地企业提供众包评论的美国公司。他们开始时是一家为餐馆和食品企业提供评论的公司,但最近也开始向外扩展,覆盖其他行业。Yelp的评论对食品企业非常重要,因为它们直接影响到他们的收入。
Yelp评论对收入的影响从5%到9%不等。
你可能想在Yelp上爬取有关当地企业的信息,以弄清谁是你的竞争对手。你可以通过爬取他们的评级和评论数来评估他们有多受欢迎。你还可以利用这些数据来筛选出包含评价最高的餐厅的街区,以及哪些街区的服务不足。
如果你是Python的绝对初学者,你可以阅读我们完整的Python网页爬取教程,它将教会你开始所需要知道的一切
取出Yelp.com的搜索结果页面
这是Yelp上一个典型的搜索结果页面的样子。你可以通过进入这个网址来访问这个特定的页面。
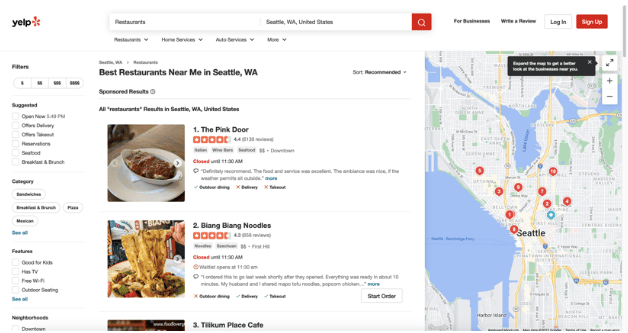
在一个名为yelp_scraper的新文件夹中创建一个名为scraper.py的新文件。这个文件将包含这个项目的所有Python代码。
$ mkdir yelp_scraper $ touch yelp_scraper/scraper.py
你将使用三个库:re (regular expressions)、Requests、BeautifulSoup。
- 请求将帮助你在Python中下载网页
- BeautifulSoup将帮助你从HTML中提取数据。
- 正则表达式将帮助你在BeautifulSoup中使用一些高级数据提取技术
在Python中默认安装了Request和BeautifulSoup,但你必须安装。你可以通过在终端运行这个PIP命令轻松做到这一点:
$ pip install beautifulsoup4 requests
一个典型的网站是由HTML(超文本标记语言)组成的。当你在浏览器中打开一个URL时,这就是服务器的响应。你可以使用requests下载相同的HTML。打开scraper.py文件,键入以下代码:
import requests url = "https://www.yelp.com/search?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States" html = requests.get(url) print(html.text)
运行这段代码应该在你的终端窗口中打印出一大块文本。这就是HTML,你将在稍后从这个HTML输出中解析数据。
如何从Yelp结果页中提取餐厅信息
在你继续之前,重要的是要最终确定你需要提取哪些数据。本文将重点讨论从搜索结果页中提取以下餐厅数据。
- 命名
- 评级
- 审查计数
- 邻居
- 餐厅页面URL
在大多数网络爬取任务中,你将使用BeautifulSoup进行HTML解析和数据提取。它不是这项工作的唯一库,但它有一个非常强大和易于使用的API,使它成为大多数程序员的默认选择。
如果你按照开头的安装说明,你应该已经安装了BeautifulSoup。不过在你使用它之前,你需要探索Yelp返回的HTML,并找出哪些HTML标签包含你需要提取的数据。
你很快就会知道,你根本不需要用BeautifulSoup来提取搜索结果的数据。你将主要用它来提取各个餐厅页面的数据,我们将在本教程的后半部分介绍。
如果你观察一下,Yelp上的每个新的搜索查询只刷新结果部分。页面的其他部分保持不变,不会被刷新。这通常表明,该网站正在使用某种API来查询结果,然后在此基础上更新页面。幸运的是,这在Yelp的案例中也是如此。
在你选择的浏览器中打开 “Developer Tools”,并导航到 “Network“标签。开发者工具在大多数主要的网络浏览器中都是默认的,它允许你检查网页的HTML以及它所发出的网络请求。试着在Yelp上搜索一个新的地点,同时打开网络标签,观察网页发出的新请求。希望你能很快发现向/search/snippet端点发出的请求。
如果你在一个新的标签页中打开这个URL,你会注意到它返回一个JSON响应,并包含用于填充搜索结果部分的所有数据。
与HTML响应相比,从JSON API响应中提取数据几乎总是很容易。如果你再仔细看一下这个URL,你会发现它只包含几个动态部分:
https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&parent_request_id=d824547f7d985578&request_origin=user
你可以安全地去掉parent_request_id,URL应该仍能正常运行。这意味着你可以插入你想要搜索的任何城市或地区,而URL的其余部分应该保持不变,并发挥同样的作用。
火狐浏览器允许你轻松搜索这个JSON响应。在过滤框中输入结果页中第一家餐厅的名字,就可以找出哪些JSON键包含你需要的数据。
似乎所有的搜索结果都以列表的形式存储在searchPageProps -> mainContentComponentsListProps。这个列表中还有一些不代表搜索结果的额外元素。你可以通过只考虑那些将searchResultLayoutType键设置为iaResult的列表项来轻松过滤掉这些元素。
在scraper.py文件中键入以下代码,它将搜索Seattle, WA地区的餐馆并列出它们的名称:
import requests
search_url = "https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&request_origin=user"
search_response = requests.get(search_url)
search_results = search_response.json()['searchPageProps']['mainContentComponentsListProps']
for result in search_results:
if result['searchResultLayoutType'] == "iaResult":
print(result['searchResultBusiness']['name'])你可以再次使用Firefox过滤出JSON中的邻域、评论数、评级和业务页面URL,以弄清哪些键包含这些信息。你最终应该得到以下的键。
- 邻近地区(列表):
result['searchResultBusiness']['neighborhoods']。 - 评论数:
result['searchResultBusiness']['reviewCount'] - 评价:
结果['searchResultBusiness']['rating'] - 业务URL:
result['searchResultBusiness']['businessUrl']
最后的scraper.py文件应该类似于这样:
import requests
search_url = "https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&request_origin=user"
search_response = requests.get(search_url)
search_results = search_response.json()['searchPageProps']['mainContentComponentsListProps']
for result in search_results:
if result['searchResultLayoutType'] == "iaResult":
print(result['searchResultBusiness']['name'])
print(result['searchResultBusiness']['neighborhoods'])
print(result['searchResultBusiness']['reviewCount'])
print(result['searchResultBusiness']['rating'])
print("https://www.yelp.com" + result['searchResultBusiness']['businessUrl'])
print("--------")运行这个文件应该会有类似这样的输出:
The Pink Door ['Downtown'] 6139 4.4 https://www.yelp.com/biz/the-pink-door-seattle-4?osq=Restaurants -------- Biang Biang Noodles ['First Hill'] 658 4.3 https://www.yelp.com/biz/biang-biang-noodles-seattle-2?osq=Restaurants -------- Tilikum Place Cafe ['Belltown'] 2167 4.3 https://www.yelp.com/biz/tilikum-place-cafe-seattle-3?osq=Restaurants -------- Nue ['Capitol Hill'] 1269 4.2 https://www.yelp.com/biz/nue-seattle?osq=Restaurants -------- Toulouse Petit Kitchen & Lounge ['Lower Queen Anne'] 4663 4.0 https://www.yelp.com/biz/toulouse-petit-kitchen-and-lounge-seattle?osq=Restaurants -------- Biscuit Bitch ['Downtown'] 4401 4.1 https://www.yelp.com/biz/biscuit-bitch-seattle?osq=Restaurants -------- Kedai Makan ['Capitol Hill'] 1094 4.3 https://www.yelp.com/biz/kedai-makan-seattle-4?osq=Restaurants -------- Elliott’s Oyster House ['Waterfront'] 3984 3.9 https://www.yelp.com/biz/elliotts-oyster-house-seattle-2?osq=Restaurants -------- Katsu-ya Seattle ['South Lake Union'] 183 4.5 https://www.yelp.com/biz/katsu-ya-seattle-seattle?osq=Restaurants -------- Ishoni Yakiniku ['Capitol Hill'] 147 4.4 https://www.yelp.com/biz/ishoni-yakiniku-seattle?osq=Restaurants --------
现在你知道如何从搜索结果页中提取你需要的所有信息了。你可以用同样的方法来提取餐厅图片、价格范围、商业标签和其他你需要的东西。
如何从Yelp餐厅页面提取餐厅信息
让我们继续前进,弄清楚如何从Yelp上的专用餐厅页面提取一些额外的信息。本节将涵盖提取。
- 命名
- 评级
- 网站
- 电话号
- 地址
下面的图片显示了所有这些信息在一个餐厅页面上的直观位置。你可以通过这个网址访问这个确切的页面。
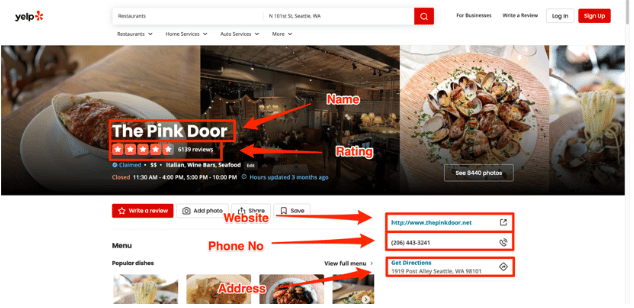
与搜索结果不同,这个页面不依赖于JSON API。数据是嵌入在HTML响应中的,你必须使用BeautfulSoup来提取它。
大多数人用于这一步的工作流程是:打开开发者工具,找出包含所需信息的标签。我将展示同样的工作流程。右键点击餐厅名称,点击检查。
正如你所看到的,餐厅名称被存储在一个h1标签中。经过进一步调查,这似乎是页面上第一个(也是唯一的)H1标签。
通常情况下,你应该尝试搜索唯一的类名或ID,你可以用它来锁定一个特定的HTML标签并提取数据,但Yelp随机化了类名,所以你不能在这里依赖它们。
用下面列出的代码替换scraper.py文件的内容。它使用request打开餐厅页面,并使用BeautifulSoup提取餐厅名称:
from bs4 import BeautifulSoup
import requests
html = requests.get("https://www.yelp.com/biz/the-pink-door-seattle-4?osq=Restaurants")
soup = BeautifulSoup(html.text)
name = soup.find('h1').text
print(name)运行上述代码应该在终端打印出餐厅的名称:
The Pink Door
接下来,使用开发者工具检查评级星级,并尝试搜索可以用来提取评级信息的东西。评级信息被存储在一个div的aria-label属性中。这就是HTML的模样:
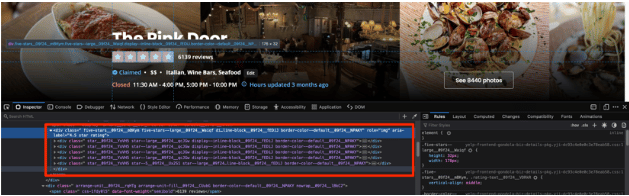
值得庆幸的是,BeautifulSoup允许你根据任意的属性来定位元素。它甚至允许你根据部分属性模式来定位标签。这意味着,你可以要求BeautifulSoup针对HTML中的一个div,其aria-label值包含部分字符串star rating。这需要使用一个正则表达式模式。
在scraper.py文件中添加以下代码,从这个div中提取ria-label:
import re
# ...
rating_tag = soup.find('div', attrs={'aria-label': re.compile('star rating')})
rating = rating_tag['aria-label']
print(rating)这样做的原因是aria-label的星级部分对所有餐馆来说都是一样的,只有前面的小数点会改变。
你可以使用类似的方法来提取评论数。评论数的HTML看起来像这样:
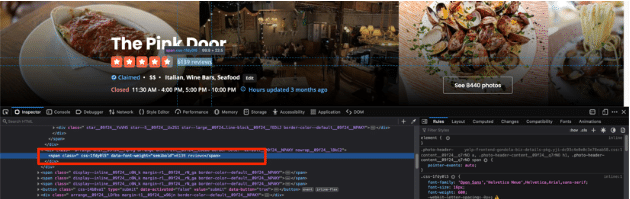
你可以根据span标签内的文本来锁定这个span。在scraper.py文件中添加以下代码来实现这一目的。
review_count = soup.find('span', text=re.compile('reports')).textprint(review_count)你可以使用一个稍微不同的方法来提取企业网站。看一下包含网站URL的部分的HTML。
你可以锁定包含商业网站字符串的p标签,然后从同级p标签中提取文本。这种方法是有效的,因为页面上只有一个p标签有这个确切的字符串,而且BeautifulSoup允许你使用.next_sibling属性轻松访问同级标签。
下面的代码应该可以帮助你完成这个任务:
website_sibling = soup.find('p', text="Business website")
if website_sibling:
website = website_sibling.next_sibling.text
print(website)有一个if条件,因为并不是所有的企业都在其业务页面上列出了网站,在这种情况下,soup.find的调用将返回None,在没有if条件的情况下,代码会中断。
同样的方法也适用于电话号码。而这就是提取代码的模样:
phone_no_sibling = soup.find('p', text="Phone number")
if phone_no_sibling:
phone_no = phone_no_sibling.next_sibling.text
print(phone_no)对于地址提取,只有一个小的修改。你也必须使用.parent属性。
你可以用 “Get Directions“的文字来定位a标签,然后选择父标签的同级别的标签。下面列出了这样做的相关代码:
address_sibling = soup.find('a', text="Get Directions")
if address_sibling:
address = address_sibling.parent.next_sibling.text
print(address)现在你有了所有的代码,可以从Yelp上的餐厅专用页面中提取餐厅的名称、评论数、评级、网站、电话号码和地址。完整的代码应该类似于这样:
import re
from bs4 import BeautifulSoup
import requests
html = requests.get("https://www.yelp.com/biz/the-pink-door-seattle-4")
soup = BeautifulSoup(html.text)
name = soup.find('h1').text
print(name)
website_sibling = soup.find('p', text="Business website")
if website_sibling:
website = website_sibling.next_sibling.text
print(website)
phone_no_sibling = soup.find('p', text="Phone number")
if phone_no_sibling:
phone_no = phone_no_sibling.next_sibling.text
print(phone_no)
address_sibling = soup.find('a', text="Get Directions")
if address_sibling:
address = address_sibling.parent.next_sibling.text
print(address)
rating_tag = soup.find('div', attrs={'aria-label': re.compile('star rating')})
rating = rating_tag['aria-label']
print(rating)
review_count = soup.find('span', text=re.compile('reviews')).text
print(review_count)
[文中代码源自Scrapingbee]成功运行的代码应该在终端打印出这个信息:

总 结
我们只是触及了Python可能实现的表面,并向你展示了一些简单的方法,即如何利用所有不同的Python包来从Yelp中提取数据。如果你的项目规模越来越大,你想提取更多的数据,并想自动化更多的东西,你应该研究一下Scrapy。它是一个成熟的Python网络抓取框架,具有暂停/恢复、数据过滤、代理轮换、多种输出格式、远程操作和一大堆其他功能。

