

网页爬取是指从网站上提取数据的过程。当开发者在研究自动化或调查等问题时,或者当他们需要从缺乏API或提供有限的数据访问的公共网站上收集数据时,爬取可以成为开发者武库中的一个强大工具。
来自各种不同背景的人和企业都在使用网页爬取,它比人们意识到的更普遍。事实上,如果你曾经从一个网站上复制粘贴过代码,你就执行了与网页爬取者相同的功能–尽管是以更有限的方式。
网页爬取的应用案例
网页爬取被用于许多部门,有许多应用。一些常见的用途包括。
- 汇总来自多个来源的数据。从多个来源收集数据并将其合并为一个数据集。
- 价格监测。监测多个网站的产品价格,比较价格,看是否有价格下降。这种方法也用于库存监测。
- 潜在客户开发。一些公司专门从事爬取行业和特定部门的网站,以收集目标客户的数据,用于未来的线索生成。
在本教程中,你将学习使用Elixir语言进行网络抓取、数据提取和数据解析的基本知识。由于其高性能、简单性和整体稳定性,Elixir是网络抓取的最佳选择。你还将学习如何使用Crawly,这是一个用于Elixir的完整的网络抓取框架。
用Elixir实现网页爬取
近年来,尽管需求量非常大,但显卡的供应量一直很低,这使得人们很难找到可用的库存,并在可以找到的情况下推动价格上涨。
有关网络爬取的知识将使你能以最低的价格找到可用的显卡。在本教程中,你将抓取亚马逊的显卡选择,以获得最低价格的显卡。
要做到这一点,你将建立一个网络刮刀,为本教程从几个网站上提取价格信息。该爬取器将收集所有的价格数据,以便日后进行分析和比较。这是建立价格提醒服务的一个很好的基础,甚至是一个黄牛机器人,你可以用来购买供应有限的产品。
设置项目
要开始,你需要创建一个新的Elixir项目。
mix new price_spider --sup
--sup标志用于创建一个具有OTP骨架的新项目,包括监督树。这是有必要的,因为我们的price_spider项目将负责产生和管理几个进程。
一旦项目被创建,你将需要更新price_spicer/mix.exs中的依赖性列表。
defp deps do
[
{:crawly, "~> 0.13.0"},
{:floki, "~> 0.26.0"}
]
end获取依赖项:
cd price_spider mix deps.get
我们正在安装的库将用于从网站上刮取数据,并提取收集的数据供进一步使用。
在继续前进之前,你还要为你的爬虫添加一些基线配置。创建应用程序的配置文件。
mkdir config touch config/config.exs
打开price_spider/config.exs并添加以下内容:
# General application configuration
import Config
config :crawly,
middlewares: [
{Crawly.Middlewares.UserAgent, user_agents: [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
]},
{Crawly.Pipelines.WriteToFile, folder: "/tmp", extension: "jl"}
]这是为爬虫设置一个特定的用户代理。通过让它模仿浏览器,你可以将被网站屏蔽的可能性降到最低,并使你更有可能获得你需要的数据。像ScrapingBee这样的工具提供了一个轮流代理的列表,并生成有效的用户代理;这在爬取大量数据时是一个很好的帮助。
创建蜘蛛
网页爬虫,通常也被称为蜘蛛或简单的爬虫,是一种机器人,它系统地穿过网络,收集和索引网页上的数据。
在Crawly的上下文中,蜘蛛是用户创建的行为,Crawly用它来从一组网站中爬取数据。与任何行为一样,你的蜘蛛需要实现以下回调。
init/0:这个被调用一次,用于初始化蜘蛛和它需要维护的任何状态。base_url/0:这个被调用一次,用于返回被抓取网站的基本URL。它也被用来过滤不相关的链接,使蜘蛛专注于目标网站。parse_item/1:这是为网站上的每个项目调用的,用于解析爬虫的响应。它返回一个Crawly.ParsedItem结构。
在lib/price_spider/spiders/basic_spider.ex文件中创建你的spider。
defmodule PriceSpider.BasicSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/ref=sr_1_3?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-3",
"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080GAMING-OC-12GD/dp/B09QDWGNPG/ref=sr_1_4?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-4",
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30800J-10PLHR/dp/B099ZCG8T5/ref=sr_1_5?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-5"
]
]
end
@impl Crawly.Spider
def parse_item(_response) do
%Crawly.ParsedItem{:items => [], :requests => []}
end
end运行蜘蛛
现在是时候让你运行你的第一个蜘蛛。用iex-S mix启动Elixir交互式控制台,并运行以下命令:
Crawly.Engine.start_spider(PriceSpider.BasicSpider)
你应该得到类似以下的结果:
16:02:49.817 [debug] Starting the manager for Elixir.PriceSpider.BasicSpider 16:02:49.822 [debug] Starting requests storage worker for Elixir.PriceSpider.BasicSpider... 16:02:49.827 [debug] Started 4 workers for Elixir.PriceSpider.BasicSpider
发生了什么事?
一旦你运行该命令,Crawly就会为你的每一个启动URL安排蜘蛛程序的运行。当它收到一个响应时,Crawly会将响应对象传递给parse_item/1回调,以处理响应并提取数据。
在这个基本的例子中还没有实现任何解析逻辑,所以它返回一个空的Crawly.ParsedItem结构。在本教程的下一节,你将使用Floki从响应中提取数据。
从响应中提取数据
作为Crawly.Spider行为的一部分,parse_item/1被期望返回一个request-and-items结构。在实现这个逻辑之前,让我们来探讨一下你正在处理的数据。
打开Elixir交互式控制台,运行以下命令:
response = Crawly.fetch("https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/")你应该看到与下面类似的结果:
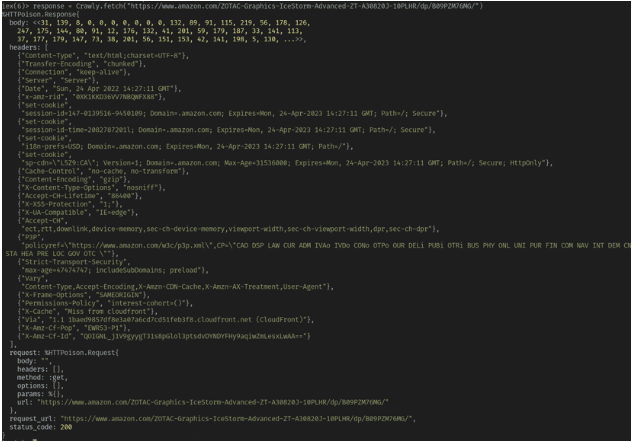
这是网站的原始响应。接下来你将使用Floki从响应中提取数据。值得注意的是,我们将从响应中提取价格。
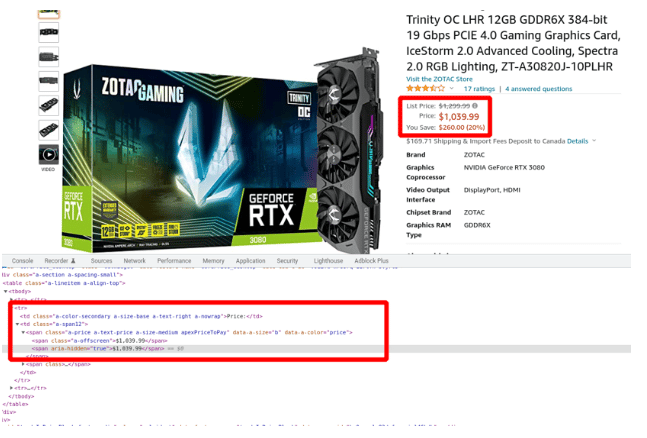
你可以通过Elixir交互式控制台进一步探索数据来定位价格。运行以下命令:
response = Crawly.fetch("https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/")
{:ok, document} = Floki.parse_document(response.body)
price = document |> Floki.find(".a-box-group span.a-price span.a-offscreen") |> Floki.text假设一切工作正常,你应该看到类似以下的输出:
iex(3)> price = document |> Floki.find(".a-box-group span.a-price span.a-offscreen") |> Floki.text
"$1,039.99"现在你可以把所有东西都接入你的蜘蛛:
defmodule PriceSpider.BasicSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/",
"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080GAMING-OC-12GD/dp/B09QDWGNPG/",
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30800J-10PLHR/dp/B099ZCG8T5/"
]
]
end
@impl Crawly.Spider
def parse_item(response) do
{:ok, document} =
response.body
|> Floki.parse_document
price =
document
|> Floki.find(".a-box-group span.a-price span.a-offscreen")
|> Floki.text
|> String.trim_leading()
|> String.trim_trailing()
%Crawly.ParsedItem{
:items => [
%{price: price, url: response.request_url}
],
:requests => []
}
end
end你可以通过运行以下命令来检查事情是否正常工作:
Crawly.Engine.start_spider(PriceSpider.BasicSpider)
在最初的设置中,我们将Crawly配置为将爬虫的结果写入tmp/目录中的一个文件。这个文件的名字将与蜘蛛的名字相同,加上一个时间戳。
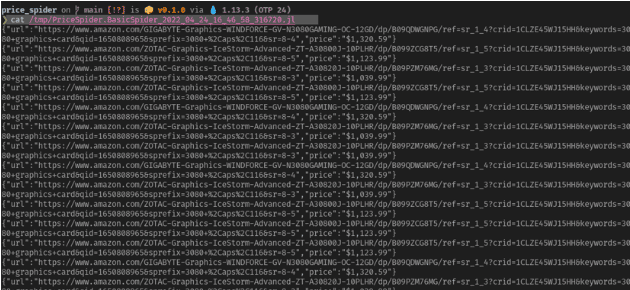
更进一步
现在,你已经有了一个可以工作的亚马逊蜘蛛,是时候进一步开展工作了。在这一点上,蜘蛛只能抓取它所提供的特定URL。你可以让它从搜索结果页中发现URL,从而使蜘蛛更进一步。
在lib/price_spider/spiders/amazon_spider.ex下创建一个新文件,并添加以下代码。
defmodule PriceSpider.AmazonSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/s?k=3080+video+card&rh=n%3A17923671011%2Cn%3A284822&dc&qid=1650819793&rnid=2941120011&sprefix=3080+video%2Caps%2C107&ref=sr_nr_n_2"
]
]
end
@impl Crawly.Spider
def parse_item(response) do
{:ok, document} =
response.body
|> Floki.parse_document()
# Getting search result urls
urls =
document
|> Floki.find("div.s-result-list a.a-link-normal")
|> Floki.attribute("href")
# Convert URLs into requests
requests =
Enum.map(urls, fn url ->
url
|> build_absolute_url(response.request_url)
|> Crawly.Utils.request_from_url()
end)
name =
document
|> Floki.find("span#productTitle")
|> Floki.text()
price =
document
|> Floki.find(".a-box-group span.a-price span.a-offscreen")
|> Floki.text()
|> String.trim_leading()
|> String.trim_trailing()
%Crawly.ParsedItem{
:requests => requests,
:items => [
%{name: name, price: price, url: response.request_url}
]
}
end
def build_absolute_url(url, request_url) do
URI.merge(request_url, url) |> to_string()
end
end这些是你对蜘蛛所做的主要改动。
- 一个新的代码块从搜索结果中检索出所有的URL。
- 每个URL都被转换为一个请求,并被添加到我们解析的项目的请求列表中。
- 一个新的字段被添加到我们解析的项目中,
名称,它包含产品的标题。 - 新函数
build_absolute_url将相对的URL转换为绝对的URL。
你可以通过运行以下命令来运行你的新蜘蛛:
Crawly.Engine.start_spider(PriceSpider.AmazonSpider)[文中代码源自Scrapingbee]
运行增强版的蜘蛛后,你应该看到更多的项目被处理。
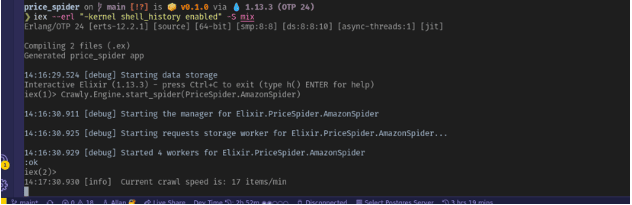
你可以通过查看你的tmp/目录文件看到生成的项目列表,它应该是这样的。
{"url":"https://www.amazon.com/ASUS-Graphics-DisplayPort-Axial-tech-2-9-Slot/dp/B096L7M4XR/ref=sr_1_30?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-30","price":"$1,786.99","name":"ASUS ROG Strix NVIDIA GeForce RTX 3080 Ti OC Edition Gaming Graphics Card (PCIe 4.0, 12GB GDDR6X, HDMI 2.1, DisplayPort 1.4a, Axial-tech Fan Design, 2.9-Slot, Super Alloy Power II, GPU Tweak II)"}
{"url":"https://www.amazon.com/ASUS-Graphics-DisplayPort-Military-Grade-Certification/dp/B099ZC8H3G/ref=sr_1_28?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-28","price":"$1,522.99","name":"ASUS TUF Gaming NVIDIA GeForce RTX 3080 V2 OC Edition Graphics Card (PCIe 4.0, 10GB GDDR6X, LHR, HDMI 2.1, DisplayPort 1.4a, Dual Ball Fan Bearings, Military-Grade Certification, GPU Tweak II)"}
{"url":"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080VISION-OC-10GD/dp/B098TZX3NT/ref=sr_1_23?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-23","price":"$1,199.99","name":"GIGABYTE GeForce RTX 3080 Vision OC 10G (REV2.0) Graphics Card, 3X WINDFORCE Fans, LHR, 10GB 320-bit GDDR6X, GV-N3080VISION OC-10GD REV2.0 Video Card"}你已经成功地抓取了亚马逊并提取了显卡的价格,这些数据你可以作为其他任何数量的应用程序的基础。
总 结
在本教程中,你已经学会了如何使用Crawly来抓取网站并从中提取数据。您还学习了网络抓取的基本知识,并具备了构建网络爬虫和网络抓取器的基础。
请记住,你只是触及了Crawly所能做的表面,还有更强大的功能可以使用。这些功能包括请求欺骗,这是一种模拟不同的用户代理或不同的IP地址的方法;通过管道进行项目验证;过滤以前看到的请求和项目;并发控制;以及Robots.txt执行。
当你做更多的网络抓取工作时,考虑抓取网站的道德影响以及如何负责任地进行抓取是很重要的。在Crawly的官方文档中可以找到一个很好的出发点。

