

想用R语言爬取网页吗?你来对地方了!
我们将从基础开始教你如何用R语言进行网络搜索,并将带你了解网络搜索的基本原理(以R语言为例)。
在这篇文章中,我们不仅会带你了解像rvest和Rcrawler这样突出的R库,而且还会指导你如何用裸露的代码来爬取信息。
总的来说,以下是你要学习的内容。
- R网页爬取的基础知识
- 用R处理不同的网页爬取情况
- 利用rvest和Rcrawler来进行网页爬取
让我们开始这段旅程吧!
简 介
用R爬取网络的第一步需要你了解HTML和网络爬取的基础知识。你将首先学习如何访问浏览器中的HTML代码,然后,我们将检查标记语言和HTML的基本概念,这将使你走上爬取信息的道路。而且,最重要的是–你将掌握用R爬取数据所需的词汇。
我们将关注以下关键项目,这将有助于你的R爬取工作。
- HTML基础知识
- HTML元素和标签
- 在R中解析HTML数据
所以,让我们开始吧,好吗。
1.HTML元素和标签
如果你仔细检查HTML代码,你会注意到像<title>...</title>,<body>...</body>等。这些被称为标签,是每个HTML文档中的特殊标记。每个标签都有一个特殊的用途,并由你的浏览器进行不同的解释。例如,<title>为浏览器提供了–是的,你猜对了–该网页的标题。同样地,<body>包含了页面的主要内容。
标签通常是一对开头和结尾的标记(如<title>和</title>),中间有内容,或者它们是独立的自我关闭的标签(如<br />)。它们遵循什么样的风格,通常取决于标签类型和它的使用情况。
在这两种情况下,标签也可以有属性,提供额外的数据和信息,与它们所属的标签相关。在我们上面的例子中,你可以注意到第一个标签<html lang="en">中的这样一个属性,其中lang属性指定该文档使用英语作为主要的文档语言。
一旦你理解了HTML的主要概念、它的文档树和标签,HTML文档就会突然变得更有意义,你就能识别你感兴趣的部分。这里的主要收获是,HTML页面是一个具有标签层次的结构化文档,你的爬虫将利用它来提取所需的信息。
2.使用R解析一个网页
那么,利用我们目前所学到的信息,让我们尝试使用我们最喜欢的语言R来爬取一个网页。请记住,到目前为止,我们只是–完全是双关语–爬取了HTML的表面,所以对于我们的第一个例子,我们不会提取数据,而只是打印出普通的HTML代码。
我想爬取ScrapingBee.com的HTML代码,看看它是什么样子。我们将使用readLines()来映射HTML文档的每一行,并创建其平面表示。
scrape_url <- "https://www.scrapingbee.com/" flat_html <- readLines(con = url)
现在,如果我们打印flat_html,我们应该在你的R控制台得到这样的东西。

整个输出将是相当多的行,所以我冒昧的为这个例子修剪了它。但是,在我带你进一步使用R进行网络搜索之前,你可以做一些事情来获得一些乐趣。
- 爬取www.google.com,并试图使你收到的信息有意义。
- 爬取一个非常简单的网页,如https://www.york.ac.uk/teaching/cws/wws/webpage1.html,看看你得到什么?
请记住,只有当你进行实验时,爬取才是有趣的。因此,在我们推进博客文章的过程中,如果你在浏览每一个例子时都能尝试一下,并把你自己的想法加进去,我会很高兴。
虽然我们上面的输出看起来很好,但它仍然不是一个严格意义上的HTML文档,因为在HTML中,我们有一个由标签组成的文档层次结构,看起来像是

这是因为,readLines()是逐行读取文档的,没有考虑到文档的整体结构。虽然,考虑到这一点,我只是想给你一个关于爬取的基本概念,这段代码看起来是一个很好的说明。
当然,真实世界的代码会复杂得多。但是,幸运的是,我们有很多库可以为我们简化R语言中的网络爬取。我们将在后面的章节中介绍其中的四个库。
首先,我们需要经历不同的爬取情况,当你用R爬取数据时,你会经常遇到这些情况。
使用R的常见网页爬取情况
1.使用R通过FTP下载文件
尽管现在FTP的使用越来越少,但它仍然经常是一种快速交换文件的方式。
在这个例子中,我们将使用CRAN FTP服务器,首先获得指定目录的文件列表,过滤列表中的HTML文件,然后下载每一个文件。让我们开始吧。
目录列表
我们试图获取数据的URL是ftp://cran.r-project.org/pub/R/web/packages/BayesMixSurv/。
ftp_url <- "ftp://cran.r-project.org/pub/R/web/packages/BayesMixSurv/" get_files <- getURL(ftp_url, dirlistonly = TRUE)
很好,我们在get_files中得到了文件列表。
> get_files "BayesMixSurv.pdf\r\nChangeLog\r\nDESCRIPTION\r\nNAMESPACE\r\naliases.rds\r\nindex.html\r\nrdxrefs.rds\r\n"
看上面的字符串,你能看到文件名是什么吗?
这个浏览器的截图以一种略为方便用户的方式显示了它们
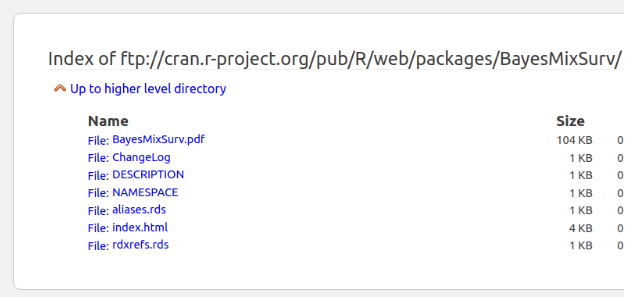
结果是,我们得到了逐行的文件列表,并有DOS的行尾(回车/换行)。用R语言解析这个文件很容易,只需使用str_split()和str_extract_all()。
extracted_filenames <- str_split(get_files, "\r\n")[[1]] extracted_html_filenames <-unlist(str_extract_all(extracted_filenames, ".+(.html)"))
让我们打印一下文件名,看看我们现在有什么。
> extracted_html_filenames [1] "index.html"
所以,我们现在有了一个我们想要访问的HTML文件的列表。在我们的例子中,它只有一个HTML文件。
文件下载
现在,我们要做的就是创建一个函数FTPDownloader,它可以下载我们的文件(再次使用getURL())并将其保存到本地文件夹。
FTPDownloader <- function(filename, folder, handle) {
dir.create(folder, showWarnings = FALSE)
fileurl <- str_c(ftp_url, filename)
if (!file.exists(str_c(folder, "/", filename))) {
file_name <- try(getURL(fileurl, curl = handle))
write(file_name, str_c(folder, "/", filename))
Sys.sleep(1)
}
}我们现在就快成功了!我们只需要一个cURL句柄来进行实际的网络通信。
Curlhandle <- getCurlHandle(ftp.use.epsv = FALSE)
现在,我们只需从plyr包中调用l_ply(),并将我们的文件列表(extracted_html_filenames)、我们的下载函数(FTPDownloader)、本地目录和我们的cURL句柄交给它。
library(plyr) l_ply(extracted_html_filenames, FTPDownloader, folder = "scrapingbee_html", handle = Curlhandle)
然后,我们就完成了!我们现在应该有一个名为scrapingbee_html的目录,其中有一个index.html。
那是通过FTP,那网络的协议HTTP呢?这一点,我们接下来要检查一下。
2.用R语言从维基百科上爬取信息
在本节中,我将向你展示如何从达芬奇的维基百科页面检索信息,https://en.wikipedia.org/wiki/Leonardo_da_Vinci。
让我们看一下解析信息的基本步骤。
wiki_url <- "https://en.wikipedia.org/wiki/Leonardo_da_Vinci" wiki_read <- readLines(wiki_url, encoding = "UTF-8") parsed_wiki <- htmlParse(wiki_read, encoding = "UTF-8")
- 我们在
wiki_url中保存我们的URL - 我们使用
readLines来获取URL的HTML内容,并将其保存在wiki_read中。 - 我们使用
htmlParse()将HTML代码解析成一个DOM树,并将其保存为parsed_wiki。
你问,什么是DOM树?这是个公平的问题。
DOM树
DOM是Document Object Model的缩写,本质上是HTML文档的类型化、内存中的表示。
由于 DOM 已经正确解析了所有元素,我们可以通过htmlParse 返回的对象轻松访问文档中的元素。例如,要获得所有<p>元素的列表,我们可以简单地使用以下代码。
wiki_intro_text <- parsed_wiki["//p"]
wiki_intro_text现在将包含一个所有段落的列表。用下面的代码,我们会访问第四个元素。

DOM的功能非常强大,但也有其他功能可以处理我们的普通HTML字符串。
例如,getHTMLLinks()将为我们提供一个页面中所有链接的列表。

你也可以通过length()函数看到这个页面上的链接总数。

我在这里再抛出一个用例,即从这些HTML页面上爬取表格。这也是你在网络爬取中经常会遇到的事情。R中的XML包提供了一个名为readHTMLTable()的函数,当涉及到从HTML页面中爬取表格时,它使我们的生活变得更加容易。
虽然莱昂纳多的维基百科页面没有HTML,所以我将使用一个不同的页面来展示我们如何使用R从网页上爬取HTML。
以下是新的网址:https://en.wikipedia.org/wiki/Help:Table
因此,让我们加载页面并检查我们有多少个HTML表。
wiki_url1 <- "https://en.wikipedia.org/wiki/Help:Table" wiki_read1 <- readLines(wiki_url1, encoding = "UTF-8") length((readHTMLTable(wiki_read1))) [1] 108
108张表格是很多的,但是那一页是关于表格的,不是吗。
很公平,让我们选择一个表。为此,我们可以使用names()函数。
names(readHTMLTable(wiki_read1)) [1] "NULL" [2] "NULL" [3] "NULL" [4] "NULL" [5] "NULL" [6] "The table's caption\n" …
这里有很多NULL,但也有一个命名的,”表的标题”,所以让我们看看这个。
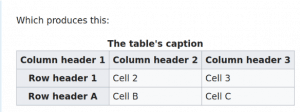
readHTMLTable(wiki_read1)$"The table's caption\n"
V1 V2 V3
1 Column header 1 Column header 2 Column header 3
2 Row header 1 Cell 2 Cell 3
3 Row header A Cell B Cell C下面是这个表格在HTML中的样子
在,想象一下访问和爬取真实世界的数据和信息。例如,你可以尝试在https://en.wikipedia.org/wiki/United_States_Census,获取美国人口普查的所有历史数据。这是一个非常好的表的使用案例。
也就是说,它不一定总是那么直接。通常情况下,我们有HTML表单和认证要求,这可能会阻止你的R代码被爬取。而这正是我们接下来要学习处理的问题。
3.在用R爬取时处理HTML表单
我们经常会遇到一些不那么容易爬取的页面。让我们以新加坡的气象服务为例–http://www.weather.gov.sg/climate-historical-daily。
密切注意下拉菜单,想象一下,如果你想爬取只有在点击下拉菜单时才能得到的信息。在这种情况下,你会怎么做?
好吧,我将向前跳几步,将向你展示rvest包的预览,同时爬取这个页面。我们在这里的目标是爬取2016年至2022年的数据。
library(rvest)
html_form_page <- 'http://www.weather.gov.sg/climate-historical-daily' %>% read_html()
weatherstation_identity <- page %>% html_nodes('button#cityname + ul a') %>%
html_attr('onclick') %>%
sub(".*'(.*)'.*", '\\1', .)
weatherdf <- expand.grid(weatherstation_identity,
month = sprintf('%02d', 1:12),
year = 2016:2022)让我们检查一下,我们已经能够爬取到什么类型的数据。下面是我们的数据框架的样子。
str(weatherdf) > 'data.frame': 3780 obs. of 3 variables: $ Var1 : Factor w/ 63 levels "S104","S105",..: 1 2 3 4 5 6 7 8 9 10 ... $ month: Factor w/ 12 levels "01","02","03",..: 1 1 1 1 1 1 1 1 1 1 ... $ year : int 2016 2016 2016 2016 2016 2016 2016 2016 2016 2016 ... - attr(*, "out.attrs")=List of 2 ..$ dim : Named num 63 12 5 .. ..- attr(*, "names")= chr "" "month" "year" ..$ dimnames:List of 3 .. ..$ Var1 : chr "Var1=S104" "Var1=S105" "Var1=S109" "Var1=S86" ... .. ..$ month: chr "month=01" "month=02" "month=03" "month=04" ... .. ..$ year : chr "year=2016" "year=2017" "year=2018" "year=2019" ...
从上面的数据框架中,我们现在可以很容易地生成URL,提供对我们感兴趣的数据的直接访问。
urlPages <- paste0('http://www.weather.gov.sg/files/dailydata/DAILYDATA_',
weatherdf$Var1, '_', weatherdf$year, weatherdf$month, '.csv')现在,我们可以使用lapply()大规模下载这些文件。
lapply(urlPages, function(url){download.file(url, basename(url), method = 'curl')})注意:一旦你执行它,这将下载大量的数据。
使用rvest进行网络爬取
受BeautifulSoup等库的启发,rvest可能是我们用来爬取网络的最流行的R包之一。虽然它足够简单,使用R语言进行爬取看起来毫不费力,但它也足够复杂,可以实现任何爬取操作。
那么,现在让我们看看rvest的行动。在这个例子中,我们将抓取IMDB,由于我们是电影爱好者,我们将挑选一部特别的电影杰作作为我们的第一个抓取任务。
最后是 sharknado
library(rvest)
sharknado <- html("https://www.imdb.com/title/tt8031422/")好了,在这一点上,我们已经得到了sharknado所需要的一切。让我们弄清楚谁是演员。
sharknado %>%
html_nodes("table") %>%
.[[1]] %>%
html_table()
X1 X2
1 Cast overview, first billed only: Cast overview, first billed only:
2 Ian Ziering
3 Tara Reid
4 Cassandra Scerbo
5 Judah Friedlander
6 Vivica A. Fox
7 Brendan Petrizzo
8 M. Steven Felty
9 Matie Moncea
10 Todd Rex
11 Debra Wilson
12 Alaska Thunderfuck
13 Neil deGrasse Tyson
14 Marina Sirtis
15 Audrey Latt
16 Ana Maria Varty Mihail伊恩-齐林,这不是《比佛利山庄,90120》中的那个家伙吗?还有《美国派》中的维基也在里面。不要忘了《星际迷航》中的迪安娜-特洛依。
尽管如此,仍有怀疑sharknado的人。我想评分会证明他们是错的?所以,这里是你如何从IMDB提取电影的评级。
sharknado %>%
html_node("strong span") %>%
html_text() %>%
as.numeric()
[1] 3.5我仍然坚持我的话。但我希望你能明白这一点,对吗?看看我们使用rvest爬取信息是多么容易,而我们在更简单的爬取场景中却要写10多行代码。
我们名单上的下一个是Rcrawler。
使用Rcrawler进行网页抓取
Rcrawler是另一个帮助我们从网上收获信息的R包。但与rvest不同的是,我们更多地将Rcrawler用于网络图相关的爬取任务。例如,如果你希望爬取一个非常大的网站,你可能想更深入地尝试一下Rcrawler。
注意:Rcrawler更多的是关于爬行,而不是爬取。
我们将回到维基百科,我们将尝试找到科学家的出生日期、死亡日期和其他细节。
library(Rcrawler)
list_of_scientists <- c("Niels Bohr", "Max Born", "Albert Einstein", "Enrico Fermi")
target_pages = paste0('https://en.wikipedia.org/wiki/Special:Search/', gsub(" ", "_", list_of_scientists))
scientist_data <- ContentScraper(Url = target_pages ,
XpathPatterns = c("//th","//tr[(((count(preceding-sibling::*) + 1) = 5) and parent::*)]//td","//tr[(((count(preceding-sibling::*) + 1) = 6) and parent::*)]//td"),
PatternsName = c("scientist", "dob", "dod"),
asDataFrame = TRUE)因此,scienstist_data现在包含以下信息集。
# Scientist dob dod 1 Niels Bohr 7 October 1885Copenhagen, Denmark 18 November 1962 (aged 77) Copenhagen, Denmark 2 Max Born 11 December 1882 5 January 1970 (aged 87) 3 Albert Einstein 14 March 1879 18 April 1955 4 Enrico Fermi 29 September 1901[文中代码源自Scrapingbee]
就这样了。你几乎知道了在R中开始进行网页爬取所需要的一切。
尝试用有趣的用例来挑战自己,揭开挑战的面纱。用R进行网页爬取真的很有趣!

