

爬取是指从HTML中提取内容。这听起来很简单,但有很多障碍。首先是要获得上述HTML。为此,我们将使用Python来避免被发现。
如果你试过,你就知道这可能需要绕过反机器人系统。使用Python–或任何其他工具–在不被阻止的情况下进行网络爬取,并不是那么简单。
网站倾向于保护他们的数据和访问。防御系统有许多可能采取的行动。请继续阅读,学习如何减轻它们的影响。或者直接使用PythonRequests或Playwright绕过机器人检测。
注意:在大规模测试时,千万不要直接使用你的家庭IP。一个小错误或疏忽,你就会被禁止。
前提条件
为了使代码工作,你需要安装python3。有些系统已经预装了它。之后,通过运行pip install 来安装所有必要的库。

IP速率限制
最基本的安全系统是禁止或节制来自同一IP的请求。这意味着一个普通用户不会在几秒钟内请求一百个页面,所以他们着手将该连接标记为危险。

IP速率限制的工作原理与API速率限制类似,但通常没有关于它们的公开信息。我们无法确定我们可以安全地做多少个请求。
我们的互联网服务提供商分配给我们的IP,我们无法影响或掩盖它。解决办法是改变它。我们不能修改一台机器的IP,但我们可以使用不同的机器。数据中心可能有不同的IP,尽管这不是一个真正的解决方案。
代理人是。它们接收传入的请求并将其转发到最终目的地。它在那里不做任何处理。但这足以掩盖我们的IP并绕过阻止,因为目标网站将看到代理的IP。
轮换代理
有一些免费代理,尽管我们不推荐它们。他们可能为测试工作,但不可靠。我们可以使用其中的一些进行测试,我们将在一些例子中看到。
现在我们有一个不同的IP,我们的家庭连接是安全的。很好。但是,如果他们阻止代理的IP呢?我们又回到了最初的位置。
我们不会详细介绍免费代理。由于它们的寿命通常很短,所以要经常更换。
另一方面,付费代理服务提供IP旋转。我们的服务将工作相同,但网站会看到一个不同的IP。在某些情况下,他们对每一个请求或每几分钟进行轮换。在任何情况下,他们都更难被禁止。而当它发生时,我们会在短时间内得到一个新的IP。

我们知道这些;这意味着机器人检测服务也知道这些。一些大公司会阻止来自已知代理IP或数据中心的流量。对于这些情况,有一个更高的代理级别:住宅代理。
住宅代理更昂贵,有时带宽有限,为我们提供普通人使用的IP。这意味着,我们的移动供应商明天就可以给我们分配这个IP。或者一个朋友昨天就有了它。他们与实际的最终用户是没有区别的。
我们可以爬取任何我们想要的东西,对吗?默认情况下是比较便宜的,必要时是比较贵的。不,还没到那一步。我们只通过了第一道关卡,还有一些关卡要过。我们必须看起来像合法用户,以避免被标记为机器人或爬虫。
用户代理标头
下一步将是检查我们的请求头。最著名的是User-Agent(简称UA),但还有很多。UA遵循一个我们稍后将看到的格式,许多软件工具都有自己的格式,例如GoogleBot。下面是如果我们直接使用Python Requests或cURL,目标网站将收到的内容。

![]()
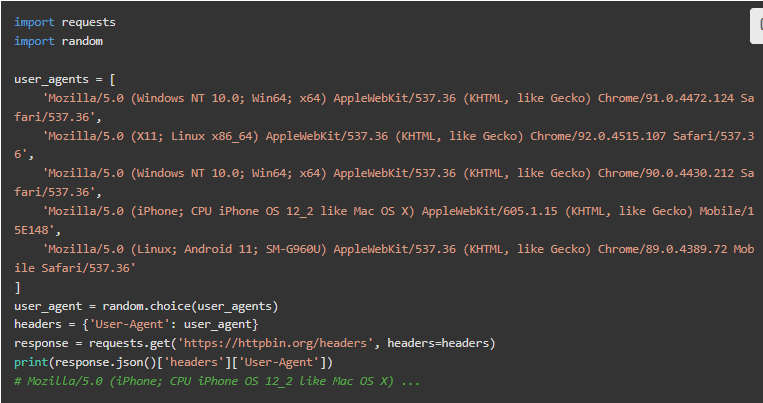
许多网站不会检查UA,但对于那些做这个的网站来说,这是一个巨大的红旗。我们必须伪造它。幸运的是,大多数库允许自定义头文件。下面是使用Requests的例子。

要获得你当前的用户代理,请访问httpbin–就像代码片段中所做的那样–并复制它。请求所有具有相同UA的URL可能也会触发一些警报,使解决方案变得更加复杂。
理想情况下,我们会拥有所有当前可能的用户代理,并像对待IP那样轮换它们。既然这几乎是不可能的,我们至少可以拥有一些。有一些用户代理的列表可供我们选择。
请记住,浏览器经常更换版本,这个列表可能在几个月后就会被淘汰。如果我们要使用User-Agent旋转,一个可靠的来源是必不可少的。我们可以用手来做,也可以使用一个服务提供商。
我们离成功更近了一步,但在头文件中仍有一个缺陷:反机器人系统也知道这个技巧,并与用户代理一起检查其他头文件。
整套的标头信息
每个浏览器,甚至是版本,都会发送不同的头信息。检查Chrome和Firefox的行动。
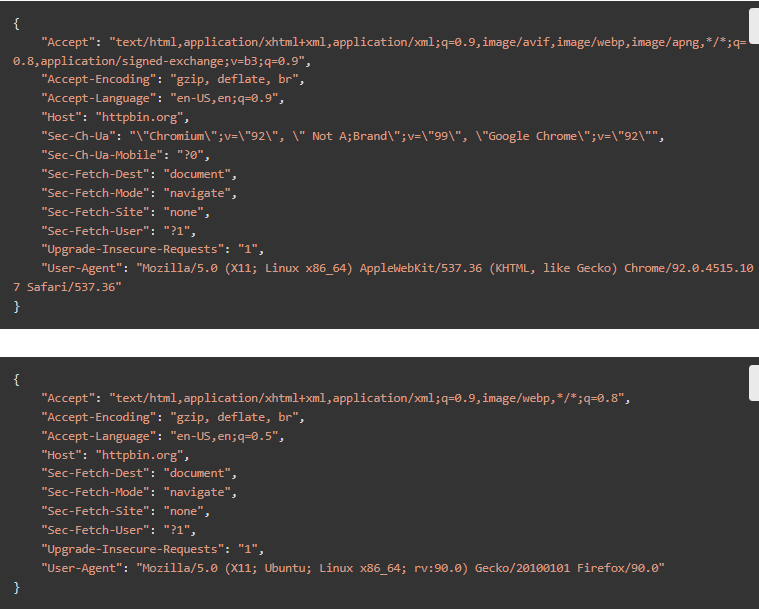
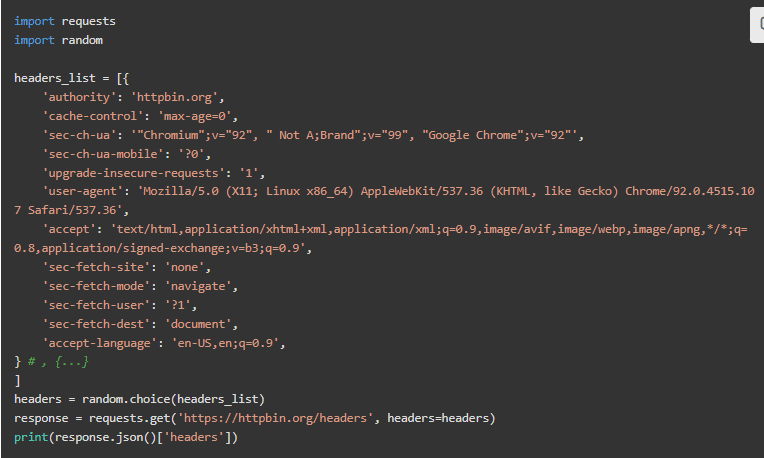
它的意思就是你认为的意思。之前那个有5个用户代理的数组是不完整的。我们需要一个有每个用户代理的完整头信息的数组。为了简洁起见,我们将展示一个有一个项目的列表。它已经足够长了。
在这种情况下,从httpbin复制结果是不够的。最理想的做法是直接从源头复制。最简单的方法是通过Firefox或Chrome的DevTools–或者你的浏览器中的类似工具来实现。进入网络标签,访问目标网站,右键单击请求并复制为cURL。然后将curl语法转换为Python语法,并将头信息粘贴到列表中。
我们可以添加一个Referheader以获得额外的安全性–比如Google或同一网站的内部页面。这将掩盖我们总是在没有互动的情况下直接请求URL的事实。但是要小心,因为添加引用者会改变更多的头信息。你不希望你的Python请求脚本被这样的错误所阻止。
Cookies (缓存)
我们忽略了上面的Cookie,因为它们值得单独列出一个章节。Cookies可以帮助你绕过一些反机器人或使你的请求被阻止。它们是一个强大的工具,我们需要正确理解。
例如,Cookies可以跟踪用户会话,并在登录后记住该用户。网站为每个新用户分配一个cookie会话。有许多方法,但我们将尝试简化。然后用户的浏览器将在每次请求中发送该cookie,跟踪用户的活动。
这怎么会是个问题呢?我们使用的是轮换代理,所以每个请求可能有一个来自不同地区或国家的不同IP。反机器人可以看到这种模式并阻止它,因为这不是用户浏览的自然方式。
另一方面,一旦绕过了反机器人解决方案,它将发送有价值的cookies。如果会话看起来合法,防御系统不会检查两次。请查看如何绕过Cloudflare以获取更多信息。
cookies会帮助我们的Python请求脚本避免被机器人检测吗?还是会伤害我们,让我们被屏蔽?答案就在于我们的实现。
对于简单的情况,不发送 cookie 可能效果最好。没有必要维持一个会话。
对于更高级的案例和反机器人软件,会话cookie可能是达到和刮取最终内容的唯一途径。总是考虑到会话请求和IP必须匹配。
如果我们想在XHR调用后在浏览器中生成内容,也会发生同样的情况。我们将需要使用一个无头浏览器。在初始加载后,Javascript将尝试使用XHR调用来获取一些内容。在受保护的网站上,如果没有cookie,我们无法进行这种调用。
我们将如何使用无头浏览器,特别是Playwright,以避免被发现?继续阅读!
无头浏览器
一些反机器人系统只有在浏览器解决了一个Javascript挑战后才会显示内容。而我们不能用Python Requests来模拟这样的浏览器行为。我们需要一个能执行 Javascript 的浏览器来运行并通过挑战。
Selenium、Puppeteer和Playwright是最常用和最知名的库。避免使用它们–出于性能方面的考虑–会比较好,它们会使爬取的速度变慢。但有时,没有其他选择。
我们将看到如何运行Playwright。下面的片段显示了一个简单的脚本,它访问了一个页面,打印了发送的头信息。输出只显示User-Agent,但由于它是一个真实的浏览器,头信息将包括整个集合(Accept,Accept-Encoding,等等)。
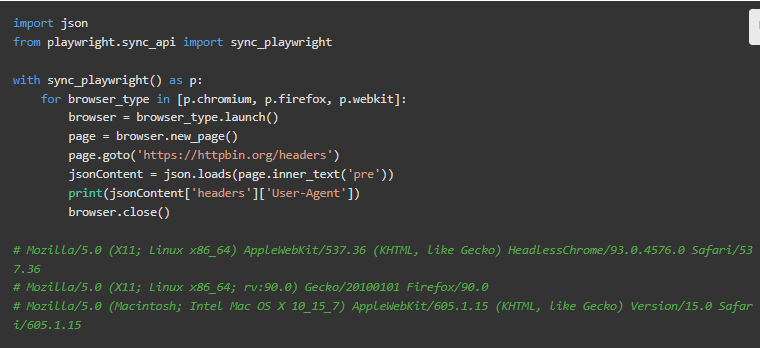
这种方法也有自己的问题:看看用户代理。Chromium的用户代理包括HeadlessChrome,它将告诉目标网站,嗯,它是一个无头浏览器。他们可能会据此采取行动。
回到页眉部分:我们可以添加自定义页眉,覆盖默认页眉。用这一行替换前面的片段,并粘贴一个有效的User-Agent。
![]()
这只是与无头浏览器的一个入门级。无头检测本身就是一个领域,很多人都在研究它。有些是为了检测,有些是为了避免被屏蔽。举个例子,你可以用一个实际的浏览器和一个无头的浏览器访问pixelscan。为了被视为 “一致”,你需要努力工作。
请看下面的截图,这是用Playwright访问pixelscan时拍摄的。看到这个UA了吗?我们伪造的那个是正确的,但他们可以通过检查导航器的Javascript API检测到我们在撒谎。
我们可以传递user_agent,playwright会在javascript中为我们设置用户代理和标题。很好!
![]()
对于更高级的情况,你可以很容易地在你的脚本中加入Playwright的隐蔽性,使检测更加困难。它可以处理头文件和浏览器Javascript API之间的不一致,以及其他事情。
总之,拥有100%的覆盖率是很复杂的,但你在大多数时候都不需要它。网站总是可以做一些更复杂的检查。WebGL,触摸事件,或电池状态。
你不需要这些额外的功能,除非试图爬取一个需要绕过反机器人解决方案的网站,如Akamai。而对于这些情况,额外的努力将是强制性的。说实话,这也是一种要求。
地理限制或地理封锁
这就是所谓的地理封锁。只有来自美国境内的连接才能观看CNN的直播。为了绕过这一点,我们可以使用虚拟专用网络(VPN)。然后我们可以像往常一样浏览,但由于VPN的存在,网站会看到一个本地IP。
在爬取有地理封锁的网站时也会发生同样的情况。对于代理来说,有一个等同于:地理位置的代理。一些代理供应商允许我们从一个国家列表中选择。激活该功能后,我们将只获得来自美国的本地IP,比如说。
行为模式
如今,阻止IP和用户代理是不够的。它们在几个小时内,如果不是几分钟,就会变得难以管理和变质。只要我们使用干净的IP和真实世界的用户代理进行请求,我们就会很安全。涉及的因素更多,但大多数请求应该是有效的。
- 转到主页
- 点击 “商店 “按钮
- 向下滚动
- 转到第二页
- …
几天后,启动相同的脚本可能导致每个请求都被阻止。许多人都可以执行这些相同的动作,但机器人有一些东西使他们明显:速度。使用软件,我们会按顺序执行每一个步骤,而实际用户会花一秒钟时间,然后点击,用鼠标滚轮慢慢向下滚动,把鼠标移到链接处,然后点击。
也许没有必要伪造这一切,但要意识到可能出现的问题并知道如何面对它们。
我们必须思考什么是我们想要的东西。也许我们不需要那第一个请求,因为我们只需要第二页。我们可以把它作为一个入口点,而不是主页。并节省一个请求。它可以扩展到每个域的数百个URL。不需要按顺序访问每一页,向下滚动,点击下一页,再重新开始。
为了刮取搜索结果,一旦我们认识到分页的URL模式,我们只需要两个数据点:每页的项目数量和项目。而大多数时候,这些信息都存在于第一页或请求中。

- 扰乱页面顺序以避免模式检测
- 使用不同的IP和User-Agent,所以每个请求看起来都是一个新的。
- 在一些调用之间添加延迟
- 随机使用谷歌作为推荐人
我们可以写一些混合所有这些的代码段,但在现实生活中,最好的选择是使用一个工具,如Scrapy、pyspider、node-crawler(Node.js),或Colly(Go)。这些片段的想法是为了了解每个问题的本身。但对于大规模的、现实生活中的项目来说,靠我们自己处理所有的事情会太复杂。
验证码
即使是准备得最好的请求也会被抓住,并显示出验证码。如今,解决验证码是可以实现的–反验证码和2Captcha–但这是对时间和金钱的浪费。最好的解决方案是避免它们。第二好的办法是忘记那个请求并重试。
例外是很明显的:那些在第一次访问时总是显示验证码的网站。如果没有办法绕过它,我们就必须解决它。然后,使用会话cookies来避免再次被挑战。
这听起来可能有悖常理,但等待一秒钟,用不同的IP和一组头信息重试同样的请求,会比解决验证码更快。
登录墙或付费墙
一些网站喜欢显示或重定向用户到一个登录页面,而不是验证码。几次访问后,Instagram会重定向匿名用户,Medium会显示一个付费墙。
与验证码一样,解决方法可以是将IP标记为脏,忘记请求并重新尝试。图书馆通常默认遵循重定向,但提供一个不允许重定向的选项。理想情况下,我们只禁止重定向到登录、注册或特定页面,而不是所有的页面。
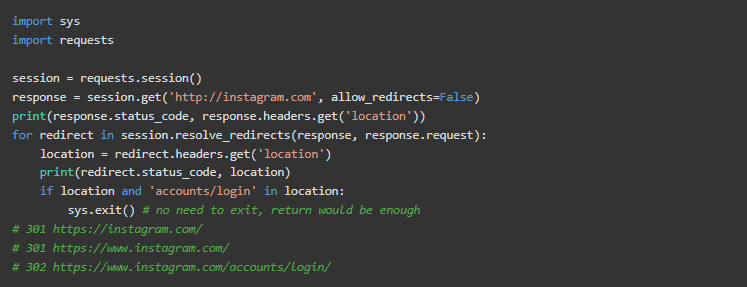
在这个例子中,我们将跟踪重定向,直到其位置包含accounts/login。我们将对该页面进行延迟排队,并在实际项目中再次尝试。
做一个好的网络公民
我们可以使用几个网站进行测试,但在大规模做同样的事情时要小心。尽量做一个好的互联网公民,不要造成小的DDoS。限制你在每个域名上的互动。亚马逊可以处理每秒成千上万的请求。但不是所有的目标网站都会。
我们总是在谈论 “只读 “的浏览模式。访问一个页面并阅读其内容。永远不要提交表格或执行带有恶意的主动行动。
如果我们采取更积极的方法,其他几个因素也很重要:写作速度、鼠标移动、不点击的导航、同时浏览许多页面等等。机器人预防软件对主动行动特别积极。出于安全原因,它应该如此。
我们不会讨论这部分,但这些行动会给他们新的理由来阻止请求。同样,好公民不会尝试大规模登录。我们谈论的是爬取,而不是恶意的活动。
有时网站会让数据收集变得更难,也许不是故意的。但在现代前端工具中,CSS类可能每天都在变化,破坏了彻底准备的脚本。
总 结
- IP轮换代理
- 用于挑战性目标的住宅代理机构
- 全套头信息,包括User-Agent
- 当需要Javascript挑战时,用Playwright绕过机器人检测–也许可以添加隐身模块
- 避免可能将你标记为机器人的模式
还有很多,可能还有更多我们没有涉及的。但有了这些技术,你应该能够大规模地抓取和爬取。毕竟,如果你知道如何使用python,在不被阻止的情况下进行网络抓取是可能的。

